
浪潮FPGA方案,节省80%磁盘空间和网络流量
浪潮FPGA方案,节省80%磁盘空间和网络流量
举个现实的例子,我们每年最大的“剁手节”——双十一当天所产生的交易日志就达到了PB级别,而这仅仅是1天、1个网站搜索产生的数据。
那这些数据对于数据中心而言意味着什么?1天内不仅多了至少1PB的数据需要存储,并且又有至少1PB网络流量被占用。按照1块盘8TB的容量来算,需要124块硬盘,按照1台服务器12块盘来算,需要至少12台服务器来存储这些日志。同时,在双十一后,这些数据仍需要被存储一段时间用于后续的大数据分析,这期间日志文件会被各个计算机群频繁的访问读取,不仅长期占用大量存储空间,也会加重数据中心内外部网络负担。
数据量爆发式增长
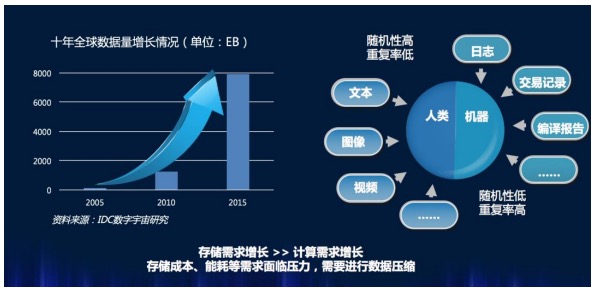
那么有没有什么方法压缩这些数据?类似我们在电脑上用WinRAR或者其他压缩工具把文件压缩为zip、rar,数据中心的海量数据是否也能被压缩。
数据压缩,用计算能力换取更多存储空间
目前,业界常用的压缩算法有基于UNIX系统的文件压缩GZip、高储存密度的计算机文件压缩Zip、无损压缩软件BZIP2等,其中GZip由于具有较好的压缩比、压缩效率和平台通用性,因此被广泛的应用。

GZip文件压缩
但传统的压缩程序基于CPU,会存在一些问题。比如,压缩任务所需要的计算资源较高,在进行大文件或者多文件压缩任务时,会导致CPU的负载率高,影响其他任务的正常运转。另外,如果压缩任务请求频繁,比如网站文件的GZip压缩,网站的同时访问人数就基本等同于压缩任务数,这时候CPU的单核性能高但并行能力弱的特性会导致压缩任务吞吐量不足。
因此,针对数据中心海量数据压缩,用计算能力换取更多存储空间是必然趋势。比如数据文件中存在很多重复出现的字符串,如果用更短的符号代替,就能达到缩短字符串的目的。例如,有个文本中大量使用“整机柜服务器”这个词,我们用"整机柜"代替,就缩短了3个字符,如果用"整"代替,就缩短了5个字符。事实上,只要保证对应关系,可以用任意字符代替那些重复出现的字符串。并且这一过程是无损的、可逆的。
基于FPGA的浪潮压缩方案,压缩率达94.8%
为了解决传统压缩架构的弊端,浪潮基于FPGA来开发GZip压缩算法,通过充分利用板卡硬件流水设计和任务级并行,来提升压缩任务的吞吐量,并有效降低CPU的负载。

浪潮FPGA F10A
由于FPGA采用与CPU迥异的运行模式,因此需要进行算法移植。目前,浪潮基于FPGA的GZip算法进行了专门的开发和优化,在样本压缩测试中,压缩率能够达到94.8%,极大降低数据文件所占用的存储空间。
举个例子,在大型数据中心,各个业务部门之间的数据可能存在于不同的集群,因此当数据需要被大量的跨集群读取时,即使各个集群中有数百G的智能网络专线,但是传输的数据不能把带宽占满,因此可能导致任务的较大延时。而在这些传输的数据中,日志等字符重复率较高的文本文件的数量也是很大的,采用浪潮FPGA方案能够迅速将文件缩小90%以上,并且能够在传输完成后快速解压,有效降低带宽占用。
1.6GB/s压缩效率,10倍于传统压缩方案
数据的压缩虽然可以节省磁盘空间,但是却也需要更多的计算能力,如果使用原有的CPU来进行处理,压缩和解压的速度较慢,会影响整个集群的业务效率,这就得不偿失了。而浪潮FPGA方案在运行简单但重复性高的任务时,能省去取指和译码步骤,极大的提高了重复运行相同代码的效率。据实测数据显示,基于高性能的硬件平台和优化的算法,浪潮FPGA方案可以达到1.6GB/s的GZip压缩速度,而使用传统x86架构处理器的性能只能达到60-150MB/s。浪潮FPGA为业界带来至少十倍于传统方法的计算效率。
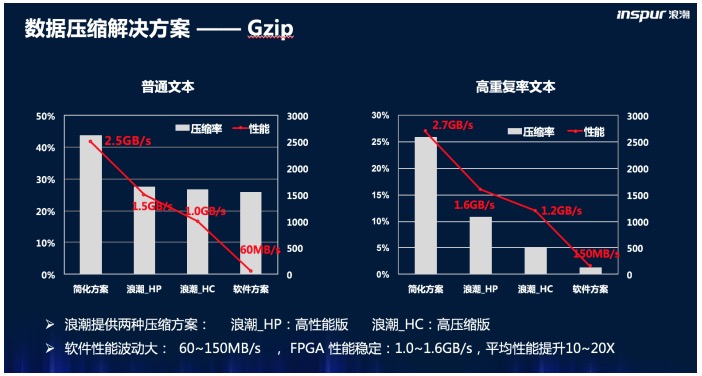
数据压缩解决方案GZip
举个例子,由于GZip可以压缩Html、JavaScript、Cascading Style Sheets等网络常用的文档,因此目前大部分的网站会启用GZip压缩来降低网站访问速度,通常经过GZip压缩的网站可以降低2/3以上的大小,因此从客户端来看,网站的打开速度可能提升3倍。但是对于极高并发量的大型网站来说,过高的瞬时流量可能导致服务器的高负载,而采用浪潮FPGA方案则能够支撑更高的并发量。
由于GZip无损压缩主要针对有大量重复字符的文件,因此以文本为主的数据,比如日志文件、交易记录、编译报告、html文件等都能进行很好的压缩。但是对于已经被压缩过的文件,比如JPEG图片文件等,压缩率可能很低甚至为负。为此在GZip无损压缩之外,浪潮还开发出基于FPGA的WebP有损压缩方案,进一步提升图片等数据的压缩率和压缩效率。未来,浪潮还将推出更多FPGA方案,为更多应用提供更高效的计算平台支撑。
好文章,需要你的鼓励


Siri AI、ChatGPT、Claude真实横评,谁才是最强AI助手?
海外博主做了一次 Siri AI、ChatGPT、Claude 横评。看完之后我最大的感受是,AI 助手的竞争已经不只是模型能力,而是谁离用户更近。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。
2017
11/30
16:27
分享
点赞

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
