
土豆洛书大模型,加速AI 应用创新与发展
土豆数据洛书基础大模型是面向产业的AI大模型,紧贴行业应用,提供行业大模型底座能力,全链路优化从基础模型到场景模型的使用效果。洛书大模型已在近日与中科曙光智能计算产品成功适配,为我国AI领域再添强大动力。
结合中科曙光智能计算产品卓越的计算能力和性价比,土豆数据科技的洛书大模型国产化解决方案将在智慧城市领域、时空信息领域、企业智能服务等领域提供全国产化行业应用智能体基座,帮助领域客户加速实现数字化转型,全面降本增效。
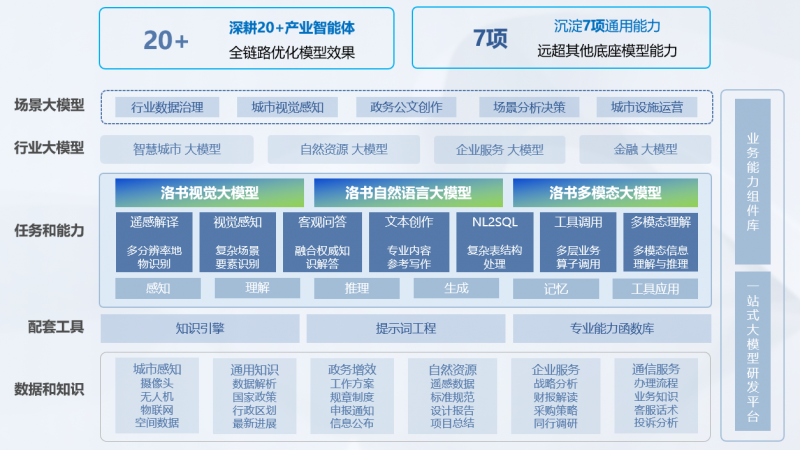
洛书大模型是高性能、高效率的自然语言处理模型,洛书基础大模型具有多模态、多任务处理能力,通过对大量数据的深度学习,具备了在视觉感知、遥感识别、数据分析、文本写作、工具调用等多个领域的强大性能,在实际应用中能够更好地应对复杂场景,提高生产效率。同时,洛书大模型注重领域知识工程的构建,通过集成专业能力函数库,使其在解决实际产业问题时具有更高的准确性和可用性。
中科曙光智能计算产品提供AI硬件系统及开发工具栈,结合储备的高效算子库、框架及组件等,进一步提升AI全栈优化能力。具有从基础算子、框架工具到扩展组件等搭建“算力、软件、平台”的AI全栈能力。
此次适配成功,赋能土豆数据科技在AI领域综合方案的场景适配能力得到进一步提升。未来,部署在中科曙光智能计算产品之上的洛书大模型将为企业提供更加高效、便捷、安全的人工智能应用方案,助力企业实现智能化转型。同时,该解决方案也将进一步推动我国AI技术的创新与发展,为各行各业带来更多的创新机遇。
随着AI技术的不断进步,我国AI产业正迎来前所未有的发展机遇。土豆数据科技此次成功适配中科曙光智能计算产品,将为我国AI产业的发展注入新的活力。土豆数据科技未来在中科曙光智能计算产品上会带来更多创新成果,为我国AI产业的发展贡献力量!
来源:业界供稿
好文章,需要你的鼓励


Flytrex无人机携手达美乐,可一次性送达两个大号披萨
无人机食品配送服务商Flytrex与全球知名披萨连锁品牌Little Caesars宣布合作,推出全新Sky2无人机,最大载重达4公斤,可一次配送两个大披萨及饮料,满足全家用餐需求。Sky2支持最远6.4公里的配送范围,平均从起飞到送达仅需4.5分钟。首个试点门店已在德克萨斯州怀利市上线,并实现与Little Caesars订单系统的直接集成。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

欧洲最大3D打印公寓楼提前数月竣工
法国社会住房项目ViliaSprint?已正式完工,成为欧洲最大的3D打印多户住宅建筑,共12套公寓,建筑面积800平方米。项目由PERI 3D Construction使用COBOD BOD2打印机完成,整体工期较传统建造缩短3个月,实际打印仅用34天(原计划50天),现场操作人员从6人减至3人,建筑废料率从10%降至5%。建筑采用可打印混凝土,集成光伏板及热泵系统,能源自给率约达60%。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2024
05/09
16:25
分享
点赞

欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
Synetic在2026嵌入式视觉峰会上发布LYNX计算机视觉SDK
生数科技发布世界动作模型Motubrain,为机器人智能带来"无限可能"
