
Pure Storage重磅公布大量软件更新 向超融合领域迈进
Pure Storage将在旧金山举行的年度Pure Accelerated大会上,公布大量软件产品以及一些新的硬件,并展示一种端到端的NVMe over Fabrics闪存堆栈。
还有一个面向FlashArray的接近超融合的功能,广泛的公有云集成,高速对象闪存存储,增加了文件服务,城市集群,以及推出了所谓的自驱动存储,使用机器学习等。这次大会涉及到大量功能特性,是Pure Storage最大规模的软件发布,主要有三个方面:
- 新的或者增强的Tier 1存储,也就是FlashArray设备
- 大数据转向大智能,面向FlashBlade的功能
- 自驱动存储——机器学习为驱动的功能,面向管理员
FlashArray是Pure Storage的Tier 1全闪存存储阵列,FlashBlade是面向非结构化数据的全闪存阵列。
Pure Storage强调自己的25项新软件功能,此外还有一些软件方面的更新。
Tier 1存储和FlashArray软件
Purity FA v5 for Flash Array with FlashArray是将传统Tier 1阵列可靠性与全闪存阵列的特性——例如重复数据删除、压缩和NVMe驱动器、框架访问速度——结合了起来。有一个名为ActiveCluster的功能用于连接两个相距达150英里的数据中心,以双活集群方面,带有透明故障切换、零恢复点对象(RPO)和恢复时间对象(RTO)。
像Oracle数据库、SAP、VMware、Hyper-V和SQL Server这样运行软件基础设施的任务关键型数据中心来说,是需要这种集群的,保证应用不会出现故障中断。
这里需要一个第三方来监看这两个站点之间的连接,并声明当连接出现故障的时候哪个站点作为主站点,这些都可以通过Pure1 Cloud Mediator功能来实现,该功能运行在Pure Storage的一个数据中心内,这样就不需要额外的硬件了。Pure FA v5中包含了一项Active Cluster免费功能,Pure Storage称Dell EMC SRDF和NetApp的Metro Cluster功能的实施成本高达数万美元。
该功能可用于在数据中心内提供机架级的动态集群,以及连接不同的数据中心,使用异步连接还可以添加第三个数据中心,而这个数据中心可以坐落于地球上任何一个地方的。
进入公有云
Pure Storage正在加强快照功能,最初的完整快照功能之后,增加了增量永久快照。
快照功能可以把本地存储快照到FlashArray以及FlashBlade。快照还可以迁移到NFS目标,例如DataDomain阵列。
CloudSnap通过S3协议将Pure Storage的快照迁移到AWS和Glacier,使用的是便携快照格式,CloudSnap可以转换为原生的Amazon格式,例如EBS、S3或者Glacier。
沃恩可以设想,来自一台数据中心服务器的虚拟机快照发送到Amazon,然后实例化运行在AWS中,提供基于云的备份、恢复、迁移和灾难恢复功能。
SNAPDIFF是一个开放可用的ASPI,针对第三方使用,Pure Storage有很多合作伙伴用它来把他们的数据发送到阵列,例如Actifio、Catalogic、Cohesity、Commvault、Rubrik和Veeam。可以想象,这有助于将数据迁移到FlashBlade上。
这些快照功能是免费包含在Purity FA v5软件中的,不需要特别的云网关设备。
VVOLs和QoS
Purity FA v5.0还具有:
- 始终如一的服务质量(QoS)
- QoS性能分级;铜级、银级、金级
- 策略为驱动的QoS,面向多租户客户,例如服务提供商
- VVOL支持HA和托管在阵列上的无状态VASA提供商
- 即时VMFS <—> VVOL的迁移
Pure Storage称VVOL是非常易于实施、使用和管理的。
准超融合和文件服务
Pure Storage强调说,开发者可以直接通过使用v5软件在FlashArray上运行虚拟机和容器,这些是运行在一种准沙箱中的,带有专门的GPU和RAM资源,提供安全性和性能隔离。

Purity FA v5应用运行资源
这个Run功能可用于运行在阵列中靠近数据的分析应用,或者数据库和远程办公应用。Pure Storage表示,开发者可以构建他们自己的定制协议来做到这一点。我们不会把这看作为完全的朝荣和基础设施一体机(HCIA)。
Pure Storage还推出了Purity v5中的Windows文件服务,使用Run功能。它支持SMB 2、3以及NFS v3和4。Pure Storage称,这适用于那些在SAN条件下需要文件访问的使用实例,例如VDI用户文件和文件共享。

Purity FA v5文件服务
还有一些插件用于微软的管理堆栈中,客户可以带入他们自己的微软许可。
FlashBlade功能实现的大数据智能
Pure Storage表示,FlashBlade非结构化全闪存阵列适合于人工智能、大数据、物联网和相关的边缘计算应用,这些应用需要更多容量和带宽来保存高速访问数据。
FlashBlade的Purity FB v2软件可横向扩展至75个刀片,比以前多了5倍,有一个8PB的命名空间,这涉及到5个4U的机架,总共20U。
现在该系统的性能可达到850万IOPS,75GB/s读带宽和25GB/s写带宽。
v2软件支持SMB文件访问、LDAP、HTTP、IP v6、快照和网络锁定管理器,以及SMB,FlashBlade还有基于S3的对象存储支持,这是自然而然的扩展,因为FlashBlade基本上是内部的一个大型基于键值的存储。
Pure Storage表示,这比AWS S3访问首个字节的速度要快10倍。基本上,这里我们看到的就是一个本地部署的全闪存对象存储;所以,它要比基于磁盘的对象存储系统快很多,但是是基于闪存的定价。
机器学习驱动存储管理
对于存储管理员来说,Pure1 META是一种管理大量Pure Storage阵列的、以机器学习为驱动的资源。Pure Storage表示,它将构建一个实时的全球传感器网络,目前客户使用的上千台阵列每天有1万亿个数据点。这个想法是把工作负载类型与数据点模式相匹配,使用机器学习,这样构建工作负载配置包括像读写IO大小、带宽、IOPS、重复数据删除和压缩率、总容量等。
如果客户A正在使用带有已知模式的工作负载,客户B开始使用相同的工作负载,那么就可以预测他们使用的阵列资源,更加智能地预测阵列大小(性能、容量、带宽),更好地管理这个阵列的资源。
Pure Storage将为客户提供全局的仪表板,以提供关于阵列的综合指标:
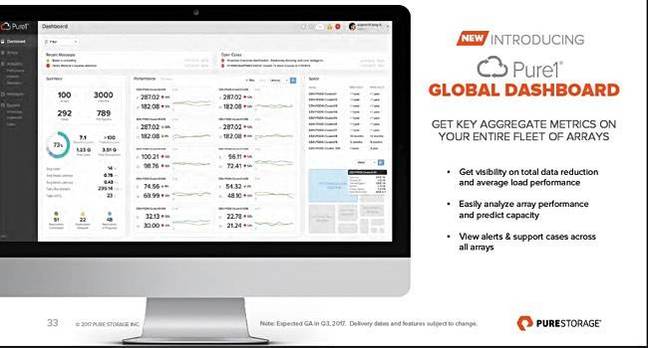
Pure1 Global Dashboard
这里有一种可能性,就是可能在阵列之间迁移工作负载以更好地进行负载均衡。Pure Storage还谈到了使用实时分析防止问题影响阵列运作,可通过所谓的“指纹”识别来找出已知问题。
如果找到匹配项,通知客户管理员,通知支持服务,开始解决问题。
Pure Storage称,META提供了预测智能来检测和防止阵列出现问题,基于工作负载的性能衡量以及配置,工作负载交互智能。用营销的语言来说,在客户层面的存储管理变得太过复杂,存储已经变得更像是自主驾驶的汽车。
最终结果就是更具成本效益的阵列和阵列操作,以及更低的管理成本。
硬件
Pure Storage公布了一个针对FlashArray的新扩展架——DirectFlash,带有原生的NVMeF支持,意味着通过NVMe over Fabric跨50Gbit/s RoCE v2 Ethernet进行访问。
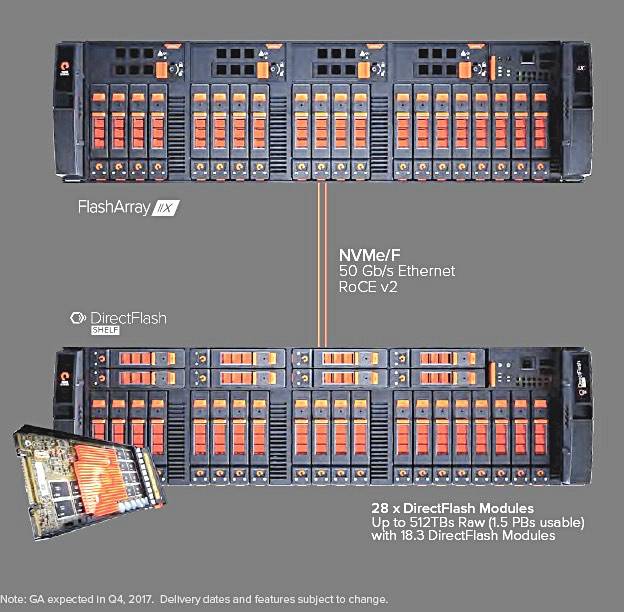
Pure DirectFlash
这个扩展架可以容纳最多512TB原始容量,如果是使用28个DirectFlash模块的话。
Pure Storage还展示了端到端的NVMe over Fabric到思科UCS服务器,使用40GBit/s RoCE v2 Ethernet连接。这正是我们在4月设想的NVMeF版本FlashStack。
这只是一个演示,但是方向非常清晰。
此外还有一个中型刀片用于FlashBlade,有17TB容量,介于现有的8TB和52TB刀片之间。
供货
Pure Storage提供的这张幻灯片罗列了27项以及具体提供时间。


评论
Pure Storage基本上推出了“大家有,我也有”的大量功能,例如文件、对象和QoS,以易于使用的方式,并且将自己的软件扩展到公有云;有人提到了数据框架吗?这样做的话,基本就消除了竞争对手一直强调的竞争优势。
例如:
- NetApp SolidFire类型的防干扰QoS?——是的,有了
- NetApp Data Fabric——是的,有了
- Dell EMC SRDF——是的,有了
- Nimble以传感器为驱动的阵列管理?——是的,有了
- NAS特性——是的,有了
- 对象存储——是的,有了
- NVMe over Fabric——是的,马上就有了
Pure FA v5 Run功能将FlashArray扩展到超融合一体机领域。很容易想象,这样使得FlashArray实际上变成了一款HCIA系统,而这不正是NetApp通过SolidFire正在做的吗。
Pure Storage是否能够全面追赶Nutanix?这不是很有说服力,Pure Storage是这么有野心的公司吗?
现在Pure Storage正在试图发展成为一家存储平台公司,它公布了一系列功能特性,会让客户开心,让渠道有理由能够敲开新客户的大门,赢得更多订单。
来源:至顶网存储频道
好文章,需要你的鼓励


AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

从传统CRM迈向智能化客户互动的转型之路
生命科学企业在全渠道战略和AI平台上投入巨大,但成效往往不尽如人意。问题根源不在于技术本身,而在于组织架构、数据治理和工作方式未能同步演进。许多转型项目止步于试点阶段,原因是各部门数据孤立、职责不清。要实现从传统CRM向智能互动的真正转型,企业需优先建立统一的数据基础和跨团队协作机制,并将AI能力嵌入日常工作流程,而非将其视为独立模块。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2017
06/15
08:55
分享
点赞

从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
