
闪存正通过多级跳板逐步走向DIMM未来
直到最近,数据访问与存储技术的主要发展动力一直取决于提升介质本身速度的表现,因此整个存储业界始终关注由磁盘到闪存乃至提升闪存存储容量的技术等核心议题。

层、极、堆栈与DIMM共同建立起一座通往更高存储数据访问速度的桥梁
不过在此之上,企业也开始将注意力转向消除存储领域追求存储数据IO提速的终极障碍:操作系统代码堆栈。消除这一限制意味着以内存或者近内存级别速度实现存储数据访问,从而给存储数据IO带来永久性革命。
而目前的过渡表现为将数据由磁盘存储至闪存——即SSD当中。这一举措的直接理由在于闪存能够提供次毫秒级访问延迟,这一水平远低于磁盘的20到100毫秒延迟。另外,闪存存储驱动器所需物理空间更低,对电力的消耗更小且不像磁盘驱动器那样需要夸张的冷却系统加以配合。
随着闪存存储方案可靠性与使用寿命的提升,外加使用成本的不断降低,同时配合足以显著缩减存储数据体积的重复数据删除与压缩技术,闪存已经开始全面接掌一级数据存储任务,并逐步渗透至二级数据存储领域。
闪存是一类仍在不断发展的存储介质。最初的平面或者说2D NAND采用单级单元设计(即每单元存储1 bit)。此类单元首先设置写入级电压,并通过阈值电压测试其电阻级别的方式实现读取。如果电流以能够通过,则代表当前施加的阈值电压已经超出电阻水平并在单元内记录为二进制中的1; 如果电流无法通过,则代表当前单元为二进制中的0。
为了能够在同一NAND晶片内提供更高存储容量,各厂商着力于通过更为精密的光刻技术降低单元尺寸,从而将更多单元塞进该晶片当中。正因为如此,80纳米级别单元开始让位于70纳米单元,随后是60纳米、50纳米乃至如今的14纳米,但这种升级的同时意味着单元内所保留的、用于实现可靠信号读取的电子越来越少。如此一来,单元尺寸缩小的作法已经走进了死胡同,开发商必须找到能够其它能够进一步提升容量与降低制造成本的途径。
由此衍生了两大主要解决思路,即着眼于级与层。
多极设计 (bit)
我们实际上完全能够对电阻级别范围进行细分在同一单元内添加更多bit值(而非继续像SLC单元中那样只包含或全有、或全无这两种状态),而能够容纳4种状态的2级单元产品亦由此诞生。其能够将50 GB SSD产品的容量倍增至100 GB,且继续使用同样的制造工艺并将成本削减至原本的约一半。
这即为我们常说的MLC,即多级单元NAND。制造商还逐渐意识到,他们可以将电阻水平加以进一步细分,即分为8种状态以实现3级单元,这种名为TLC(即3级单元)的NAND在容量上较MLC高出50%。着眼于当下,制造商们又在考量是否能够实现4级单元(QLC)技术,从而将容量进一步提升25%。
以下为此类产多值单元的工作原理,亦包含SLC、MLC、TLC与QLC单元的可行二进制值表达:
- SLC = 0或1——意味着两种状态与一种阈值电压。
- MLC = 00、10、01或11——代表四种状态与三种阈值电压。
- TLC = 000、001、010、011、100、101、110、111——代表八种状态与七种阈值电压。
- QLC = 0000、0001、00100011、0100、0101、0110、0111、1000、1001、1010、1011、1100、1101、1110、1111——共十六种状态与十五种阈值电压。
我们无法在同一单元中添加更多bit,因为SSD控制技术无法处理由此带来的精度保障与误差消除运算。另外,在同一单元中存储更多bit亦会降低SSD速度水平并缩短其使用寿命,意味着SSD的性能将不断缩水或者无法实现理想的生命周期。正因为如此,开发商想到了增加层数的设计方案。
多层设计
通过精心制造,我们确实有可能在晶片中添加更多单元层,即通过增加闪存晶片垂直高度的方式实现容量提升。因此24层方案应运而生,随后是三星公司牵头的48层设计,目前SanDisk/东芝紧随其后而英特尔与美光亦在考虑是否应当放弃长久以来坚持的平面NAND设计思路。
我们能够更轻松地在3D NAND当中使用尺寸远大于现有2D NAND的存储单元,这意味着每个单元可包含更多电子数,因而可实现更快执行速度并在各个bit级状态下提供更长使用寿命——包括SLC、MLC以及TLC。三星公司目前正在生产64层TLC 3D NAND(亦称V-NAND)SSD产品,其存储容量高达7 TB与15.3 TB,远高于现有2.5英寸磁盘驱动器。平面TLC NAND的存储容量则仍然被限制在2 TB或3 TB水平,这迫使各家制造商不得不纷纷投身3D NAND技术的开发当中。
各厂商皆在着眼于64层堆叠设计,并希望能够实现96层甚至更高层数以持续增加闪存存储产品的容量水平。不过新的问题亦由此产生。构建这样一块多层芯片意味着制造商需要以极为精确的方式对不同存储单元层进行彼此堆叠,随后在各层之间设置(蚀刻)通孔以作为不同层间数据传输所使用的连通线路。这些通孔必须极为精确地进行垂直排布并拥有几乎完全一致的直径数字,同时分毫不差地与每一层相交以贯通整块芯片并完成自身数据传输任务。这是制造技术领域的一项非凡成就。每层0.01度的误差即会在96层堆叠架构的顶端与底端造成0.48度的误差角,这可能意味着其无法正常工作并导致芯片彻底报废。
而要在此基础之上再添加24层以及/或者进一步缩减存储单元尺寸,无疑会将误差的可接受范围降低至更小的区间之内。
我们可能最终仍然会迎来96层设计方案。但我们是否仍能够继续降低存储单元制程尺寸还是个存在争议的问题。而在另一方面,必须承认的是我们已经走进了技术层面的死胡同,这意味着我们必须在后NAND技术时代找到其它技术手段以克服上述致命障碍。
后NAND时代存储介质技术
目前最为突出的此类产方案为英特尔与美光公司合力打造的3D XPoint(CrossPoint)方案,其采用批量相变机制对硫系材料的电阻值水平进行转换。这项技术号称拥有较NAND更高的存储密度(即在更低占用空间下提升更高存储容量)及更快执行速度。然而其实际工作原理仍是个谜,且XPoint目前只以Optane SSD形式发布了少量样品,而速度更快的DIMM接口XPoint将于今年晚些时候发布以配合英特尔公司将于2018年进行的CPU升级(Purley CPU及其Omni-Path互连机制)。
三星公司则给出了一款相对中庸的竞争性方案Z-SSD技术,其能够以尚未公开的方式将NAND闪存的访问速度提升至接近DRAM的水平。在此之后,还有西部数据(SanDisk)尚在开发的电阻RAM技术以及HPE的ReRAM技术——即忆阻器技术。再有,IBM公司的研究人员在考虑开发相变存储器方案,亦有多家初创企业分别拿出了自己的自旋力矩RAM(STT-RAM)以及EverSpin等设计蓝图。

IBM公司的相变存储器
以上提到的各项技术皆能够提供所谓存储级内存(简称SCM)方案,即可实现内存级别速度的永久性(非易失)存储产品。在计算机当中,内存会得到直接访问,具备字节可寻址能力且可对接各类加载与存储指令。传统存储(非存储级内存)则通过IO代码堆栈实现访问,其面向存储在非易失性介质之上的块访问驱动器中的文件或数据块进行读取与写入,具体包括纸带、磁鼓、机械磁盘、磁带当然亦包括后来的NAND闪存。
从CPU周期的角度来看,该IO堆栈的执行需要消耗数千次CPU周期; 这是对CPU时间的巨大浪费,会严重拖慢应用程序的执行速度,但考虑到存储设备的速度与CPU的执行速度间存在无数倍差异,这样的浪费又属于“必要之恶”。因此,CPU会在完成某一IO的初始化工作之后,转向正在运行且发出IO请求的其它应用中的其它线程。
如果存储设备能够以内存或者近内存级别速度运行,且数据能够直接面向该介质进行读取以及写入,那么我们将不再需要使用极耗时间的IO堆栈。
考虑到这一点,再加上非易失性存储提供的访问速度优势,原本的双线程切换操作将最终转化为线程合并这类解决方案。
对速度的渴求
与此同时,就在一部分厂商不断追求提升SSD存储容量的情况下,亦有一部分厂商专注于进一步提高其访问性能。当SSD初次出现时,其设计采用与现有主机系统磁盘驱动器插槽相兼容的思路,意味着它能够直接适配原本3.5英寸与2.5英寸磁盘驱动器所使用的SATA与SAS接口。在此之后,制造商意识到PCIe总线所具备的数据访问速度与延迟优势意味着其能够更为充分地发挥闪存存储产品的特性,即实现更高IOPS表现。另外,PCIe卡在物理空间方面也往往更加充裕,意味着制造商能够在其中塞进更多闪存芯片以进一步增加存储容量。
不过各家制造商的PCIe闪存卡亦需要协同配套的驱动器才能在不同主机系统之上使用,如此折腾的结果就是反倒不如直接推出标准的SAS与SATA驱动器。因此整个业界很快意识到他们仍然需要打造出真正标准化的驱动器,而这就是如今炙手可热的NVMe(即Non-Volatile Memory Express)规格。我们现在已经能够在市场上找到大量NVMe SSD产品,且仍有更多相关方案陆续涌现。
说到这里,大家对于整个业界的态势应该已经有了比较清晰的认识。NAND介质、设备与互连领域始终处于不断变化当中,而各存储方案供应商则在不断想办法增加其设备的存储容量与数据访问性能,希望尽可能使其拥有更接近于原始NAND的访问速度表现。正因为如此,SATA与SAS已经由原本的每秒3 Gbit传输速率升级至后来的每秒6 Gbit,再到如今的每秒12 Gbit。在另一方面,虽然PCIe仍然拥有相当显著的速度优势,但其还是无法真正采用主机系统中的CPU-内存总线这样一条DRAM互连速度标准中的黄金通道。NetList与Diablo Technologies等厂商已经率先开始尝试将NAND直接接入内存DIMM,这意味着其能够直接接入内存总线。
软件阻碍着数据访问速度的进一步提升
尽管以上提到的这一切都能够在理论层面带来更快的NAND数据访问速度,但服务器制造商的采用举措却显得相当迟缓——这主要是因为他们明确意识到,这种速度提升亦要求操作系统与应用软件进行有针对性的调整。
这里我们需要首先强调一点,存储介质凭借速度提升获得的回报其实是存在衰减的,这主要是因为业务系统当中还存在着其它一些严重影响访问延迟但却无法通过高速存储介质加以解决的因素。以下为相关示意图:
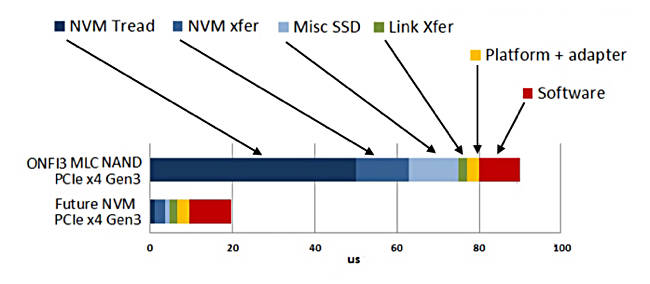
ObjectiveAnalysis公司Jim Handy整理出的数据访问延迟来源示意图
很明显,IO堆栈已经开始成为提升数据访问速度这一历史性课题当中最为突出的阻碍性因素,而如今的SCM恰好能够解决此项难题。
回避IO堆栈
SCM所实现的内存或者近内存速度级别NVDIMM可将SCM驱动程序添加至主机操作系统当中,并借此在一定程度上降低IO堆栈延迟影响。其能够从操作系统处接收文件层级IO语义(文件读取、文件写入等)并将其翻译为内存层级(加载、存储)语义,以供DIMM上的存储介质加以执行。将DRAM DIMM与电池或电容支持型NAND(NVDIMM-N)充当的非易失性存储资源相结合,我们能够实现相当于NVMe SSD IO堆栈层级访问性能约十倍的速度提升。这种方案被称为面向NVDIMM的数据块级访问机制。
如果大家通过字节层级访问使用NVDIMM,即使操作系统将其作为直接访问分卷(简称DAX,为微软公司提出的技术概念),则经过修改的应用程序代码能够直接向NVDIMM发送内存层级的加载-存储命令,从而回避块层级机制带来的时间消耗。在这种情况下,NVDIMM的访问速度能够进一步提升8倍,意味着其将较NVMe SSD实现80倍的速度增量。
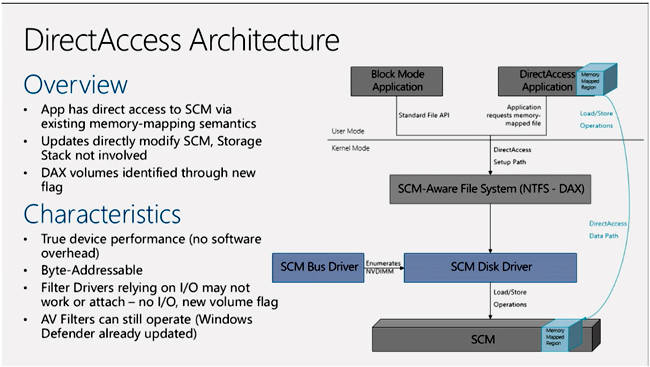
微软公司为Windows Server 2016发布的DAX架构
以下比较数字来自微软公司进行的实际测试:
- 在一项简单的4K数据块随机写入测试中,利用单一线程指向 NVMe SSD所能实现的延迟水平为0.07毫秒(70微秒),而传输带宽约为56 MBps。
- 在使用块模式NVDIMM-N进行同一项测试时,我们发现其延迟水平为0.01毫秒(10微秒),传输带宽则为580 MBps,速度提升10倍。
- 在采用字节可寻址模式进行同一项测试时,其速度结果进一步提升8倍,延迟为820纳秒而传输带宽则超过8 GBps。
感兴趣的朋友可以点击此处查看微软方面给出的背景介绍(英文原文)。
由此带来的助益不仅仅是为每应用每单位时间节约下数万次CPU周期,更重要的是确保主机系统的CPU无需将额外30%、40%甚至50%以上时间浪费在本不必要的IO处理身上,而能够转而处理更多实际工作。即使只进行粗略计算,如果我们能够在一台服务器上节省下40%的CPU资源,则意味着能够运行额外40套虚拟机或者将服务器的使用成本降低最高40%,同时让现有虚拟机拥有更快的运行速度。
总体而言,我们完全有机会借此消除一切拖慢现有任务执行流程的操作系统代码层冲突。
结论
- MLC与TLC 3D NAND SSD如今已经成为存储一级数据的规范性介质。
- NVMe访问协议正在逐渐取代SATA与SAS。
- 3D NAND SSD在堆叠层领域的强化将使得闪存具备更出色的性价比,进而在二级数据存储领域占得一席之地。
- DRAM/闪存NVDIMM将帮助我们回避IO代码堆栈以获得近内存级别字节可寻址存储访问速度。
- 3D XPoint以及/或者其它存储介质将使得NVDIMM获得更为可观的性能优势,从而成为DRAM的可行性替代方案。
- 非易失性SCM DIMM配合直接访问分卷将显著提升服务器(以及最终客户端)的存储数据访问速度。
这一切都将会通过向NAND芯片中添加更多层与级、通过DIMM挂载存储介质并最终回避IO代码堆栈的方式来进行。这代表着存储行业乃至整个IT技术领域都将迎来更加美好的未来,且这一前景再过几年即将真正出现在我们身边。现在就让我们期待闪存技术的下一波革命性成果吧!
好文章,需要你的鼓励


OpenClaw 智能体正式登陆 iOS 与 Android 平台
开源AI智能体OpenClaw今日宣布正式推出iOS和Android应用。用户可通过手机连接OpenClaw Gateway路由层,调用AI智能体及其工具完成各类任务,涵盖编程、餐饮规划等场景。OpenClaw此前因MoltBook社交媒体实验走红,其创始人Peter Steinberger已于今年2月加入OpenAI。尽管MoltBook事件后来被揭露部分由真人假扮智能体,此次移动端上线标志着AI智能体正加速渗透日常生活。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2017
02/26
09:56
分享
点赞

智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
软件定义汽车时代:从“年”到“周”,研发团队如何高效驾驭复杂度?
美国消费品安全委员会拟出台电动自行车电池安全新规
