
双轮动力 西部数据整合存储技术格局
 HDD与SSD是技术上的零和博弈吗?曾经甚嚣尘上的固态存储取代机械存储声浪,在两种不同路径技术竞争背景下共进,不仅衍生出全新的产品形态,也为需求爆炸性增长的存储市场提供了更加细分的解决方案。
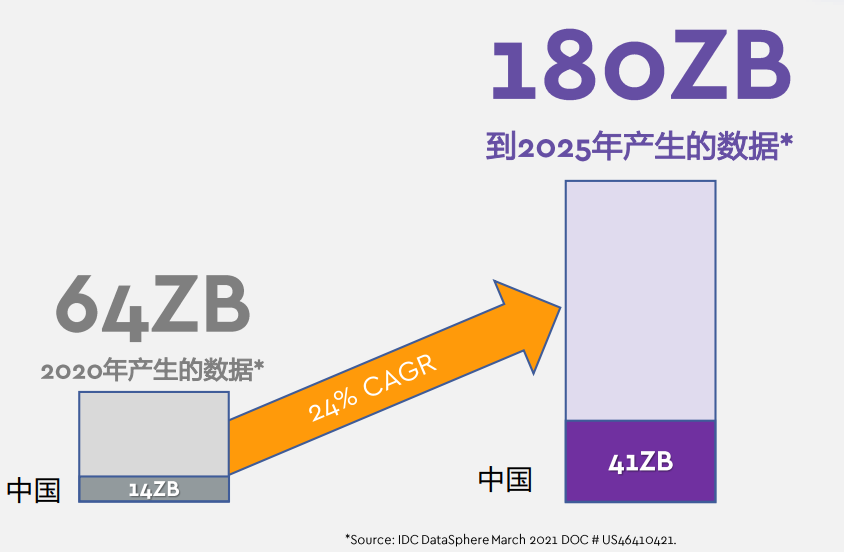
HDD与SSD是技术上的零和博弈吗?曾经甚嚣尘上的固态存储取代机械存储声浪,在两种不同路径技术竞争背景下共进,不仅衍生出全新的产品形态,也为需求爆炸性增长的存储市场提供了更加细分的解决方案。根据IDC的数据统计,全球数字信息存储需求依然呈现出快速增长态势,疫情持续与半导体缺货双重影响下,数据存储需求的增速有增无减。2020年至2025年,全球范围内,每年所产生的数据量复合增长率达23%,而中国市场更是从14ZB增加到41ZB、复合增长率更是达到24%。而与此同时,其中能够被存储下来的数据只是其中的很小一部分,因为届时每年新生产的存储设备容量仅几ZB,远远不能满足市场需求。
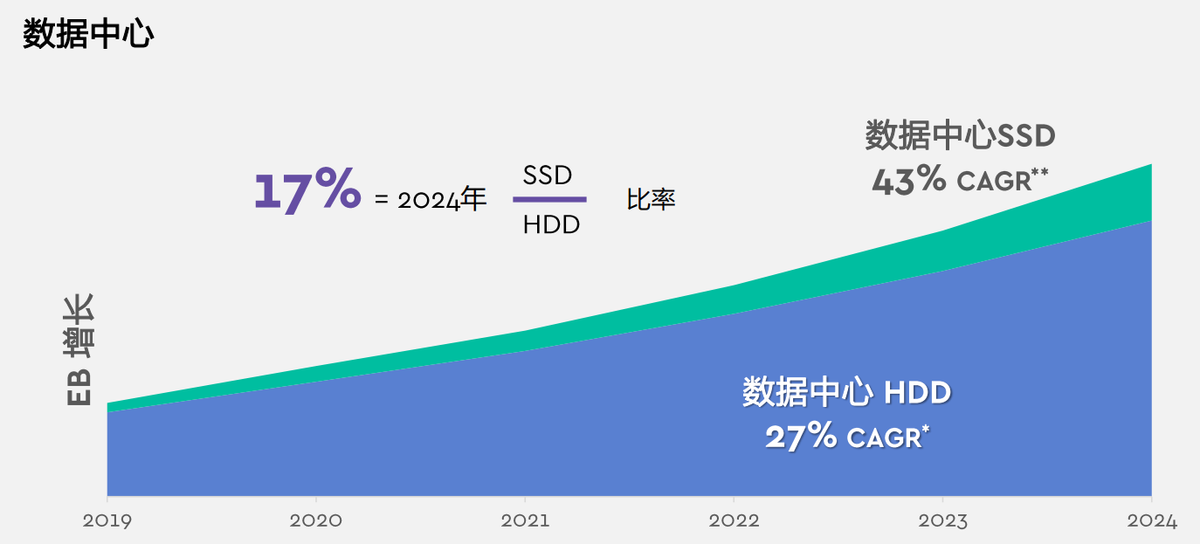
这几年,个人消费者并未直接感受到自身存储需求有所提升,无论是智能手机的数百GB存储空间还是PC的数TB存储空间增长停滞,都是建立在支持它们的数据中心、云存储快速增长的背景下的。在SSD产品年复合增长率高达43%的同时,HDD同样保持了27%的高增长速度,也从侧面印证了用户对数据容量依旧保持强烈需求。西部数据公司副总裁兼中国区业务总经理刘钢表示,“除了容量,用户对快数据的需求也非常急迫,不仅要存储数据,还要挖掘数据的价值,真正把数据用于分析、预测和决策。可以简单地理解为HDD支持的是大数据,而是SSD支持快数据的需求。”
近日,在西部数据举办的“数智创新 芯存未来”媒体分享会上,西部数据公司HDD业务部高级副总裁Ravi Pendekanti宣布其搭载了OptiNAND技术的20TB Ultrastar DC HC560产品的正式发布,且正在和多家互联网及云服务企业沟通进行部署测试,帮助用户高效应对在容量、性能及能耗方面的诸多挑战。

西部数据公司HDD业务部高级副总裁Ravi Pendekanti
Ravi进一步表示,西部数据已开始批量出货这款单盘容量高达20TB的ePMR HDD,其首款产品Ultrastar DC HC560单碟容量高达2.2TB。
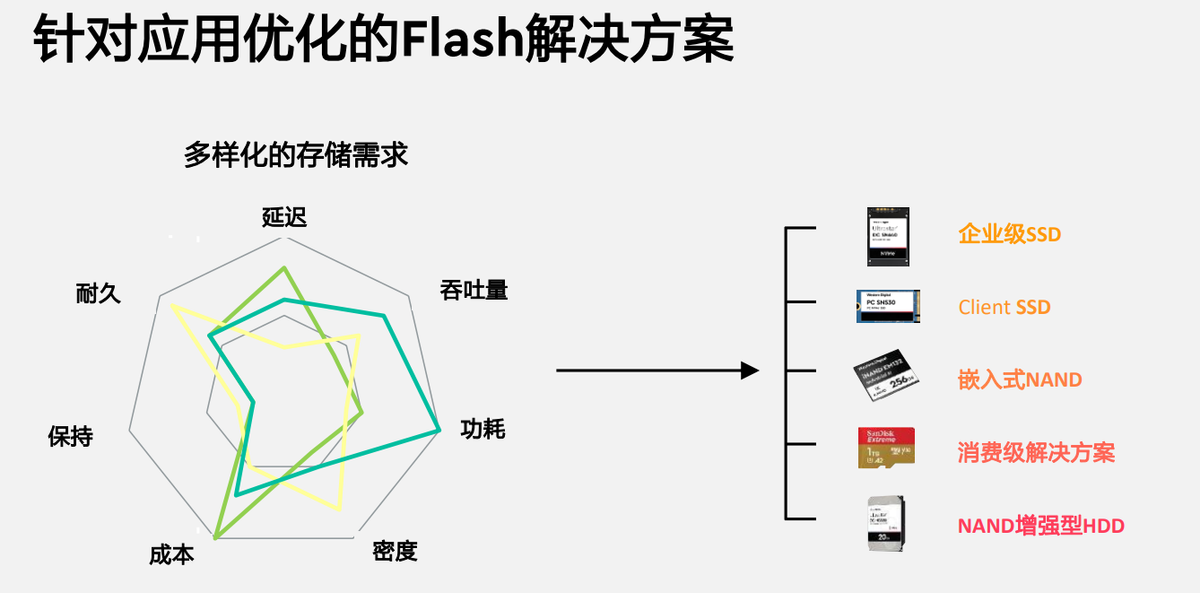
刘钢指出:“西部数据拥有从Flash到HDD的全产业链技术,一方面不断推进Flash产品不断丰富细化,满足从企业级用户到消费级的全解决方案。”根据其透露的信息,西部数据采用BiCS5技术的3D NAND已经实现112层产品的量产,今年还推出了162层的3D NAND技术,即在3D NAND问世的6年内,从实现了从48层到162层近3.4倍的层数增加。

西部数据公司副总裁兼中国区业务总经理刘钢

垂直整合能力更体现在跨产品技术领域,相比单一Flash产业链资源,西部数据致力于将其与HDD产品创新相结合,前面提到的OptiNAND技术,就是这样一个突破。利用NAND介质的性能与功能优势为HDD加速的技术概念屡见不鲜,但是它们都未触及制约HDD性能、容量进一步发挥的机械结构内部。
经过早期的宣传,SMR、EAMR(MAMR、HAMR等)等诸技术已深入人心,但是市场接受度有限或距离上市尚有时日。

OptiNAND技术结合了西部数据在Flash技术和HDD产品上的双重优势,HDD机械结构仅需小幅调整,就能配合HelioSeal(氦气封装)、TSA(三阶寻轨定位系统)、ePMR(能量辅助存储)等HDD创新技术,实现性能上的飞跃。自9月正式发布以来,仅仅2个多月,采用这一系列技术的Ultrastar DC HC560就实现了容量与速度的提升、规模出货,并获得了用户的认可。
存储磁盘元数据的3D NAND闪存以iNAND UFS的形态嵌入HDD,创新的专有固件算法及更新的的全新磁盘架构设计,进一步推升HDD的容量、性能和可靠性,降低功耗及TCO。截止至目前,采用相关ePMR技术的产品已部署超过100EB。
在谈到国内合作伙伴的生态布局方面,刘钢介绍了携手联想及SmartX赋能金融客户数字化转型、联手H3C与星环科技助力企业实现数据资产化、联合沃趣为金融企业提供卓越的云架构体验等诸多客户案例,深刻印证了西部数据深耕中国市场,不断通过创新的存储解决方案赋能合伙伙伴、为客户创造价值。
刘钢总结道:西部数据是一家同时拥有HDD和闪存技术的公司,我们提供的产品背后是从芯片到系统的完整产品线。我们专注在存储领域十多年了,是存储行业的重要贡献者。未来,我们希望可以跟更多国内生态伙伴一起,为整个存储市场提供优化的存储解决方案。
来源:业界供稿
好文章,需要你的鼓励


AI如何重振电商客户信任度
生成式AI在电商领域发展迅速,但真正的客户信任来自可靠的购物体验。数据显示近70%的在线购物者会放弃购物车,主要因为结账缓慢、隐藏费用等问题。AI基础设施工具正在解决这些信任危机,通过实时库存监控、动态结账优化和智能物流配送,帮助商家在售前、售中、售后各环节提升可靠性,最终将一次性买家转化为忠实客户。

SCB集团团队突破传统RAG技术壁垒:打造超大规模网络知识库的高速检索新方案
泰国SCBX金融集团开发的DoTA-RAG系统通过动态路由和混合检索技术,成功解决了大规模知识库检索中速度与准确性难以兼得的难题。系统将1500万文档的搜索空间缩小92%,响应时间从100秒降至35秒,正确性评分提升96%,为企业级智能问答系统提供了实用的技术方案。

Qumulo推出Stratus架构实现安全多租户环境
存储供应商Qumulo发布多租户架构Stratus,为每个租户提供独立的虚拟环境,通过加密技术和租户专用密钥管理系统实现隔离。该统一文件和对象存储软件支持本地、边缘、数据中心及AWS、Azure等云环境部署。Stratus采用加密隔离技术确保敏感数据安全,同时提供任务关键操作所需的灵活性和效率,帮助联邦和企业客户满足合规要求。

VGR:中科院和字节跳动的AI突破——让机器真正“看懂“图片再推理
中科院和字节跳动联合开发了VGR视觉锚定推理系统,突破了传统AI只能粗略"看图"的局限。该系统能在推理过程中主动关注图片关键区域,像人类一样仔细观察细节后再得出结论。实验显示VGR在图表理解等任务上性能大幅提升,同时计算效率更高,代表了多模态AI"可视化推理"的重要进展。

