
立足国产 智驭未来——奥卡云存储产品发布 原创
3月30日,以“智存储 驭未来”为主题的2021智能存储论坛暨奥卡云存储产品发布会在西安西咸新区成功举办。大会上奥卡云数据科技有限公司隆重对外发布了采用高效SCM技术、全局重删压缩、面向云计算领域的高端分布式全闪存存储系统——UniIO。会后,奥卡云数据科技有限公司CEO张科、奥卡云数据科技有限公司研发副总裁陈鹏接受了记者采访。

奥卡云的国产云存储之路
首先,奥卡云研发副总裁陈鹏,向我们介绍了公有云环境下对存储的特殊需求:

在当前主流的云计算数据中心之中,不但算力可以按需提供,存储也同样是如此,可以通过软件定义的方式,自如的对存储容量进行扩展、对传输性能进行控制,从而满足用户业务、应用多样化的实际使用需求。此外,在云环境中对存储性能的可持续性,也会有很高要求,在传统存储上,当存储系统即将写满时,会产生大量后台进行、维护进程,导致存储大幅性能波动,极大影响用户的正常业务应用。
奥卡云正是看到了云计算对存储系统的特殊需要,正式对外推出UniIO这款面向云、面向下一代数据中心的全闪存存储系统,为企业打通了一条全新的国产云存储之路。
高利用率、高可靠的UniIO
接下来,奥卡云CEO张科就UniIO分布式全闪存存储系统,向我们进行了更详尽的介绍。

高存储空间利用率
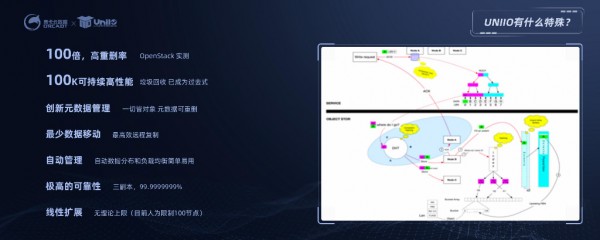
传统SSD存储为了保障应用性能,会在使用的过程中,预留15%-20%的存储空间,而UniIO由于自身的重删粒度小,重删范围大,所以能够达到很高的重删率。另外,通过后端放置专利技术,UniIO无需预留15%~20%的空间用于存储系统本身运行使用,相对于传统架构的存储,这15%~20%的空间释放给用户使用,进一步也提高了空间利用率。UniIO还有对性能无感知的压缩技术,也进一步提高了空间利用率。还有更重要的一点,UniIO采用创新的架构,将元数据与用户数据一样对待,元数据也同样可以重删,元数据也做到最精简。这种架构在目前已有的存储产品中是比较少见的。这种架构在业界是独一无二的,是奥卡云特有的。

这一些列的关键技术及措施,使得UniIO可用空间利用率达到95%以上。对于价格高昂的的闪存硬件,如果有20%的损耗,对于用户而言是极大的浪费。使用UniIO,仅需预留5%的空间既可满足系统本省运行使用,剩余95%都是用户的可得空间,提高了空间利用率。
在奥卡云当天的Openstack演示云环境下,重删压缩率在非最优配置环境下,UniIO的空间利用率可高达21:1。例如,10TB的物理存储空间,对于用户而言可以使用210TB。简单来说,就是买1份存储,可以当成21份存储使用。非常显著的减低了用户的整体拥有成本。
9个9的高可靠性
除了高可用性之外,受益于分布式存储的高可靠性,UniIO在配置3副本的情况下,可靠性达到9个9,即每年存储数据的丢失量不会多于1个对象,或者说宕机时间不会超过1秒钟。在此基础上,UniIO对于可靠性还做了一些特有的优化。例如,UniIO后台拥有智能的运维机制,会自动判断当前数据是否处于危险状态,会按照智能的算法始终将用户数据保持在安全稳定的状态。例如,当UniIO三副本的集群中有节点故障时,副本数又2降到1,UniIO就会自动感知到该节点上的数据已经处于危险状态,UniIO会将故障节点上的数据原原本本的复制到其他节点,并进行均匀分布,同时保持数据副副本在用户所设置的2副本~6副本范围内。这些处理对于用户来说都是透明的,也就是说UniIO随时随地,进行尽心尽力地在保护用户数据的安全可靠。
立足国产 坚持100%原创
目前国内软件定义存储行业,呈现出百花齐放、群雄逐鹿的态势。因为有很多开源软件可以依赖,降低了产品研发门槛。一些企业可以依托开源软件做改进和优化,最后形成自己特有的架构。但奥卡云并非如此,而是采用100%自动研发的方式,重新设计了一套全新架构来进行分布式存储的研发。
最后,奥卡云CEO张科对于奥卡云的国产化的规划进行了总结:
第一、100%坚持原创的IP,我们所写的每一行代码都是可控的,提供给用户的产品是可控的;
第二、奥卡云最早从前年开始就积极与国产生态合作,尤其像飞腾、申威,还有像最近加入的光合组织。这里给大家分享一个例子,今天演讲中提到的非易失性内存,在当前在国产平台上是不支持的。 我们联合飞腾、国防科大、上下游等企业,联合推进NVDIMM在国产平台的适配,不久的将来大家就会看到非易失性内存在国产平台上的应用落地。
第三、国产化是一个不可逆的过程。不管从国外的大环,还是国内新基建、促进双循环的过程来看,国产化替代是一个大的趋势,一个不可替代不可逆的过程。从我们去年做过的一些政府项目来看,政府有明确的需求,从中国的国情来看,国内的政府项目是国产化的先进试验点,他们对于国产化的需求比较靠前,这些都促进奥卡云在国产化的道路上前行,是奥卡云国产化战略的重要组成部分。
好文章,需要你的鼓励


图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
2026年7月13日,软件工程师Ryan Peterman在他的播客The Peterman Pod上发布了一期与David Patterson的长对话。

NVIDIA推出“三模式“AI语言大脑:一个模型同时兼顾速度与准确,彻底打破现有推理瓶颈
英伟达推出Nemotron-Labs-Diffusion三模式语言模型,将逐字生成、并行扩散与自猜自验融于一体,单用户吞吐量最高达Qwen3-8B的4倍,同时保持相近准确率。

豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

华东师范大学等多家机构联合出手:让机器人训练数据“少而精“,原来靠这个秘密武器
SIEVE是一种面向机器人模仿学习的数据筛选方法,通过发现可复用行为原语和转换接口,用50%数据和训练量超越全量训练效果。
2021
04/08
15:45
分享
点赞

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
