
V10:借助全新数据集成 API 复用数据
当今时代,数据堪称每家公司的生命线。公司每天会出于各种原因生成和利用海量新数据。多年来,Veeam 一直重视数据保护,但数据复用能力更是我们引以为傲的资本。
设计初衷
Veeam 借由免费产品 Veeam FastSCP 初次进军这一市场时的一个主要目标是:将文件迁移至 ESX(i) 服务器,并从中迁出文件。当时的用户别出心裁,经常使用该产品创建数据副本。他们下载文件,借助该产品通过复用现有数据重新创建虚拟机。
几年后,我们在发布 Veeam Backup & Replication v5 时推出了一些引领行业的特性,如 SureBackup 和 Virtual Labs。这些特性可帮助您复用备份数据(以及您的 Veeam 备份存储投资),并将其用于测试备份或运行 Virtual Lab 以进行测试和故障排除。Virtual Lab 也适合新员工 — 您只需部署一些虚拟机,让虚拟机学习您的应用,以便它们可访问生产基础架构。
v8 改进了 Virtual Lab,支持将存储快照用作数据源。存储快照的利用使得数据复用功能可用于您的(现有)生产存储快照。
在 v9.5 Update 4 中,我们将这些特性更名为“DataLabs”,并对其进行扩展,加入了 Secure Restore 和 Staged Restore,可帮助用户更高效地将数据用于安全与合规目的。
总之,我们希望以尽量多的方式复用数据。
推出数据集成 API
在全新 Veeam Backup & Replication v10 中,我们加入了高效复用数据的重磅新特性,即数据集成 API。这一新特性支持第三方产品集成至您的备份中,带来了更多可能性,包括:
- 数据挖掘
- 数据分类
- 安全性分析
- eDiscovery
- 数据取证
企业在以惊人的速度创造数据。发挥这些信息的价值,通过数据复用获取关键洞察,帮助他们做出更明智的业务决策。
为何不利用备份扫描恶意软件、勒索软件和其他安全威胁以避免影响生产环境?这可以减轻环境保护负担,帮助您测试备份,查找可能在后续事件才会触发的有害因素。 支持第三方专家访问您的数据,以挖掘模式信息、提高销量或发现造成最近疑难问题或疾病的异常情况。

工作原理
通过利用 PowerShell,您可以高效使用这一 API,挂载任何虚拟机的任何虚拟磁盘。如果需要,您甚至可使用所有备份,同时显示所有磁盘!您可根据需要挂载和复用任何数量的数据,没有任何限制。
磁盘挂载后,将显示在已知的 VeeamFLR 文件夹中,您可通过 Windows Disk Management 使用这些磁盘。
 VeeamFLR 文件夹显示同时挂载的多个虚拟机备份。
VeeamFLR 文件夹显示同时挂载的多个虚拟机备份。VeeamFLR 文件夹显示同时挂载的多个虚拟机备份。
您还可通过 iSCSI 为其他服务器提供访问这些磁盘的权限,实现与所选第三方软件的完美集成。通过增加额外的安全层可实现该目的,例如仅支持通过某些 IP 进行访问。
如何实施
让我们详细了解一下如何实施。在下面的示例中,我们将通过 iSCSI 为外部服务器提供 1 个磁盘。
# Add the Veeam PowerShell snapin - if it already is loaded continue silently with no error
Add-PSSnapin VeeamPSSnapin -ErrorAction SilentlyContinue
# The backup variable $backup is populated by the cmdlet Get-VBRBackup which will return info regarding the backup data
$backup = Get-VBRBackup -Name "MyBackup"
# Provide the IP or hostname of the target server
$targetServerName = “192.168.1.5”
# Provide the credentials to access the remote server example: lab\administrator
# These must be stored within the Credentials manager in Veeam Backup & Replication
$targetAdminCredentials = Get-VBRCredentials -name "LAB\Administrator"
# Get-VBRRestorePoint is where you find the restore point you wish to use, -Last can be used for the amount of objects you wish to go back
$restorepoint = Get-VBRRestorePoint -Backup $backup | Sort-Object –Property CreationTime | Select -Last 1
# Publish the disk(s) for the restore point
$session = Publish-VBRBackupContent -RestorePoint $restorepoint -TargetServerName $targetServerName -TargetServerCredentials $targetAdminCredentials
该脚本中有一些重要内容需要您更新。
首先是 $backup 变量,该变量包含实际备份数据参考。
其次是 $targetServerName 变量。我们使用此变量定义向哪个服务器提供数据。
最后是 $targetAdminCredentials 变量,其包含访问远程服务器的证书。它们需存储在 Veeam Backup & Replication 证书管理器中。
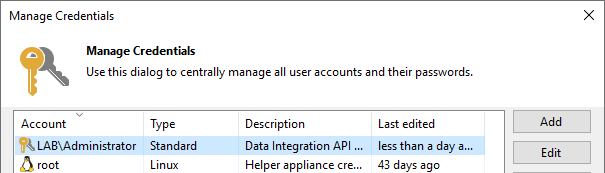 于连接远程服务器的证书
于连接远程服务器的证书通过运行该脚本,我们将支持提供的目标服务器访问磁盘,磁盘将在 Windows Disk Management 中显示。
 Windows Disk Management 中显示的磁盘(红色标记)
Windows Disk Management 中显示的磁盘(红色标记)来源:至顶网存储频道
好文章,需要你的鼓励


Netgear推出AI驱动网络管理平台,助力中小企业与服务商
Netgear发布云端网络管理平台Insight 10.0,引入AI驱动能力,专为中小型企业(SME)和托管服务提供商(MSP)设计。新版本提供智能运维、统一可视化、简化管理及云原生架构四大核心升级,支持自动化故障排查、设备健康监控及多站点集中管理,帮助IT团队从被动响应转向主动运维,解决中小企业长期缺乏企业级网络管理工具的痛点。

北京航空航天大学研究团队揭秘:给AI代码助手加几行“路标注释“,导航效率提升了多少?
北京航空航天大学研究发现,向AI代码助手注入轻量级结构注释,可使Bug定位准确率提升2.2%,运行轮次减少1.6次,且运行结果方差减半。

旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

北京大学与DP Technology联手:用135M参数模型打败十亿参数级竞争者,像素级图像生成迎来新突破
北京大学与DP Technology提出PRA框架,通过16维低维中间状态与并行解码像素输入,同时解决像素空间自回归图像生成的高维预测误差和训练推断差距两大瓶颈,135M参数超越19亿参数模型。
2020
04/03
14:55
分享
点赞

pgEdge推出ColdFront,加入OLTP与OLAP融合赛道以支持AI应用
TabFM:面向表格数据的零样本基础模型正式发布
Netgear推出AI驱动网络管理平台,助力中小企业与服务商
旧笔记本、台式机与打印机该如何正确回收处理
美国NRC提出核废料处置新规,为长期搁置问题开辟出路
OpenClaw 智能体正式登陆 iOS 与 Android 平台
智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
