
浪潮云海大数据平台产品能力评测斩获佳绩 原创
近日,在工信部指导下的数据中心联盟公布的2017大数据产品评测结果中,浪潮云海Insight大数据平台以优异的成绩通过了基础能力测试和性能测试两部分评测,其中三项性能指标排名第一。
大数据产品能力评测由工信部指导下的数据中心联盟组织,并委托中国信息通信研究院实施测试,是国内起步最早、覆盖最广、技术水平最高、影响最大的大数据评测体系,圈定了国内大数据基础平台厂商第一梯队,成为政府和行业用户评价和选购大数据产品的权威参考。
在此次基础能力测试中,云海Insight大数据平台满足全部32个必测项和12个可选项的测试要求,涵盖了Hadoop和Spark生态体系中的绝大部分组件和功能;
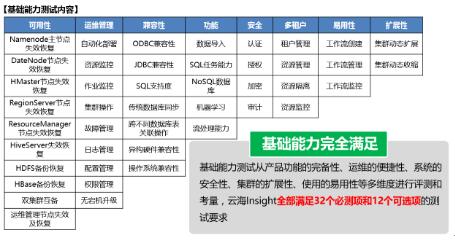
在性能测试中,云海Insight大数据平台通过全部15个测试用例指标验证,其中SQL执行总时间(10个用例)、HBase载入、机器学习SVM算法三项性能指标排名第一。
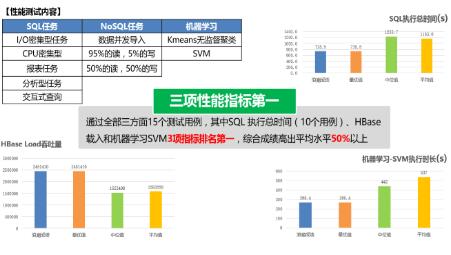
此次评测标准升级到了2.0版本,测试难度加大,基础能力测试用例达到44项;性能测试SQL负载测试数据规模从10TB扩展到30TB,NoSQL测试数据规模达到20亿条,机器学习最大负载数据规模达到1TB。
云海Insight打造全栈式企业级大数据平台
云海Insight大数据平台是浪潮着力打造的一款企业级大数据平台产品,包含Hadoop和Spark生态中的20多个主要技术组件,研发过程中始终秉承开放共享的技术发展策略,遵循国际开源技术标准。同时,云海Insight从客户业务的需求出发,着力于产品功能的完备性、运维的便捷性、系统的安全性、集群的扩展性、操作的易用性和性能的高效性,为政企客户打造成熟稳定的企业级规模化大数据平台。
目前,云海Insight实现了一站式管理运维,运维效率提升30%;提供统一的数据操作控制台,实现了可视化数据操作、全栈式任务管理和图形化流程编排,开发效率提升20%;SQL兼容性99%,全部通过TPC-DS标准SQL测试;各项性能指标持续提升,多次在第三方评测和客户测试中拔得头筹;提供向导式、高性能的机器学习工具,内置丰富算法模型,大大降低行业客户在机器学习领域的技术门槛;实现基于认证、授权、加密、审计四位一体的安全策略,保障数据资源和计算资源的安全隔离和灵活共享。
多年来,浪潮面向行业为客户提供云计算和大数据整体解决方案,积淀了丰富的经验。凭借成熟的大数据技术平台和扎实的行业实战能力,浪潮云海大数据平台成功在政府、电信、金融、公安、气象、卫生、教育等行业实现落地,运用大数据技术为客户提供业务价值。
加大技术投入,浪潮大数据竞争力持续提升
浪潮积极融入并回馈国际开源社区,多位技术人员在Apache社区的Spark、Kudu、Hue、HBase等多个项目中成为了代码贡献者。凭借领先的大数据发展理念和"技术-专利-标准"梯次攀登的创新战略,2016年浪潮申请云计算、大数据专利450项,居国内首位,在《2017中国大数据发展报告》中被评为技术创新度唯一满分的企业。
2017年,浪潮大数据竞争能力持续提升。今年3月,在由国家信息中心、南海大数据应用研究院发布的《2017中国大数据发展报告》中,浪潮被评为十大最具影响力大数据企业前三甲;同月,在2017中国IT市场年会中,浪潮获得"2016-2017中国大数据市场综合实力第一"殊荣;7月,浪潮正式加入Apache国际开源社区,以支持更多的浪潮大数据技术人员成为社区开源项目的贡献者。
2017年,中国唯一"大数据流通与交易技术国家工程实验室" 落户浪潮,围绕数据流通进行大数据相关体系建设、标准统一、核心技术研发和生态构建;浪潮宣布参建国家首个"教育大数据应用技术国家工程实验室",致力建设国内领先、国际一流的教育大数据理论研究、工程化实验、教育管理服务和专门人才培养一体化平台。
同时,依托大数据技术和产品,浪潮天元大数据平台积累了50PB高价值的互联网数据,具备20000+采集节点、500TB的日处理能力;成功助力全国27个省市政府建立大数据平台,实现了数据的共享共用,为众多政府、企业用户提供专业的大数据服务。
"进入大数据时代,稳扎稳打的技术实力和行业根基将让浪潮领先半步。通过联合上下游合作伙伴,浪潮致力于构建开放融合的大数据生态,为客户提供云计算大数据整体解决方案。" 浪潮集团副总裁张晖表示。未来,浪潮将继续通过更具竞争力的大数据产品、丰厚的行业沉淀,助力更多客户在云计算大数据时代下转型升级。
好文章,需要你的鼓励


大众汽车推进平价电动车战略,两款新车率先下线
大众汽车旗下ID. Polo与Cupra Raval已在西班牙马托雷尔工厂正式下线投产。两款车型起售价分别为24,995欧元和26,000欧元,均基于MEB+平台打造,搭载37kWh或52kWh电池组,续航里程最高可达454公里。这是大众"电动城市车家族"系列的首批产品,预计今年夏末秋初开始交付。大众集团通过跨品牌资源整合,实现约6亿欧元的成本节约,后续还将推出ID. Cross等新成员。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
三星宣布将于6月8日起为Samsung Health应用推出重磅功能更新,赶在Galaxy Watch 9传闻发布之前落地。新版本将引入多项AI驱动的生物特征分析功能,包括:综合心率、血氧、皮肤温度等数据的每日活力评分(Vitals)、结合体成分数据评估长期心脏健康的心脏健康评分、优化训练强度的每日有氧负荷追踪,以及横向对比用户群体的健身指数。此外,应用界面将重新划分为睡眠、营养、活动、正念和体征五大板块,并新增抗氧化指数、年龄指数和听力保护等个性化功能。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2017
11/10
16:15
分享
点赞

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
Meta智能眼镜被曝含"人脸识别"追踪代码,隐私风险引发警示
Gemini企业智能体平台的智能体RAG如何实现可靠响应
麻省理工学院AI与计算研讨会:技术进步中不可或缺的人文因素
亚马逊全新数据中心路由架构降低AWS网络能耗40%
iOS 27即将发布,多款iPhone应用将迎来全新设计升级
连接性已成为与计算和存储同等重要的AI基础设施核心要素
开发者仍在等待Meta最新AI模型的API访问权限
迈向Token经济时代,F5以“AI赋能交付”筑基智能新生态
米拉·穆拉提重返公众视野,谨慎发声
特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
