
Box CEO:人工智能将改变生活创造巨大机遇

云存储公司Box首席执行官Aaron Levie在近日举行的Boxworks 2017大会上公布了在AI方面的更新。
- 近日,Box推出的Box Skills可以让应用开发者采用来自微软、Google和IBM的人工智能,运用到他们的云文件中。
- Box首席执行官Aaron Levie表示,就像PC给我们带来的影响一样,AI也将给我们的技术生活带来巨大转变——当数字化生活越来越普及的当下让机器为我们做更多的事情。
- 他认为真正的机会在于利用诞生于硅谷的尖端人工智能技术,并且让开发者随时可以使用。
- 他还说,他以平常心看待竞争对手Dropbox,因为两家厂商瞄准的是不同的市场。
无论你走在硅谷的何处,都能感受到时下最热门的技术就是“人工智能”,人工智能已经成为Google新款Pixel手机、Amazon Echo智能音箱、微软Office和众多技术初创公司的最大卖点。
作为年收入27.5亿美元的云文件公司Box的首席执行官,Aaron Levie坦言,当谈到AI的时候,人们多少有些厌倦了这个被热炒的词。不过,在该公司的Boxworks大会上,Levie宣布Box将发力人工智能,推出新的功能和能力。
这次发布在AI方面的升级,让Box客户可以选择来自Google、微软和IBM的AI服务,然后用于自动分类和标记云中的语音、视频和图像文件。拿医院举例,Box可以使其更轻松地构建一个系统,任何X射线信息都会根据联邦法律被自动标记和保护起来,并锁定到只能被得到允许的医生查看。
“最终,计算机将会代表我们做一些事情,”Levie表示。
他将人工智能的崛起与PC在80年代掀起的革命做类比——这一变化可能会改变我们与技术交互的方式,为那些具有投资AI远见的人带来巨大机会。
“我们还处于刚开始探索我们能在这个领域做些什么,”Levie说。
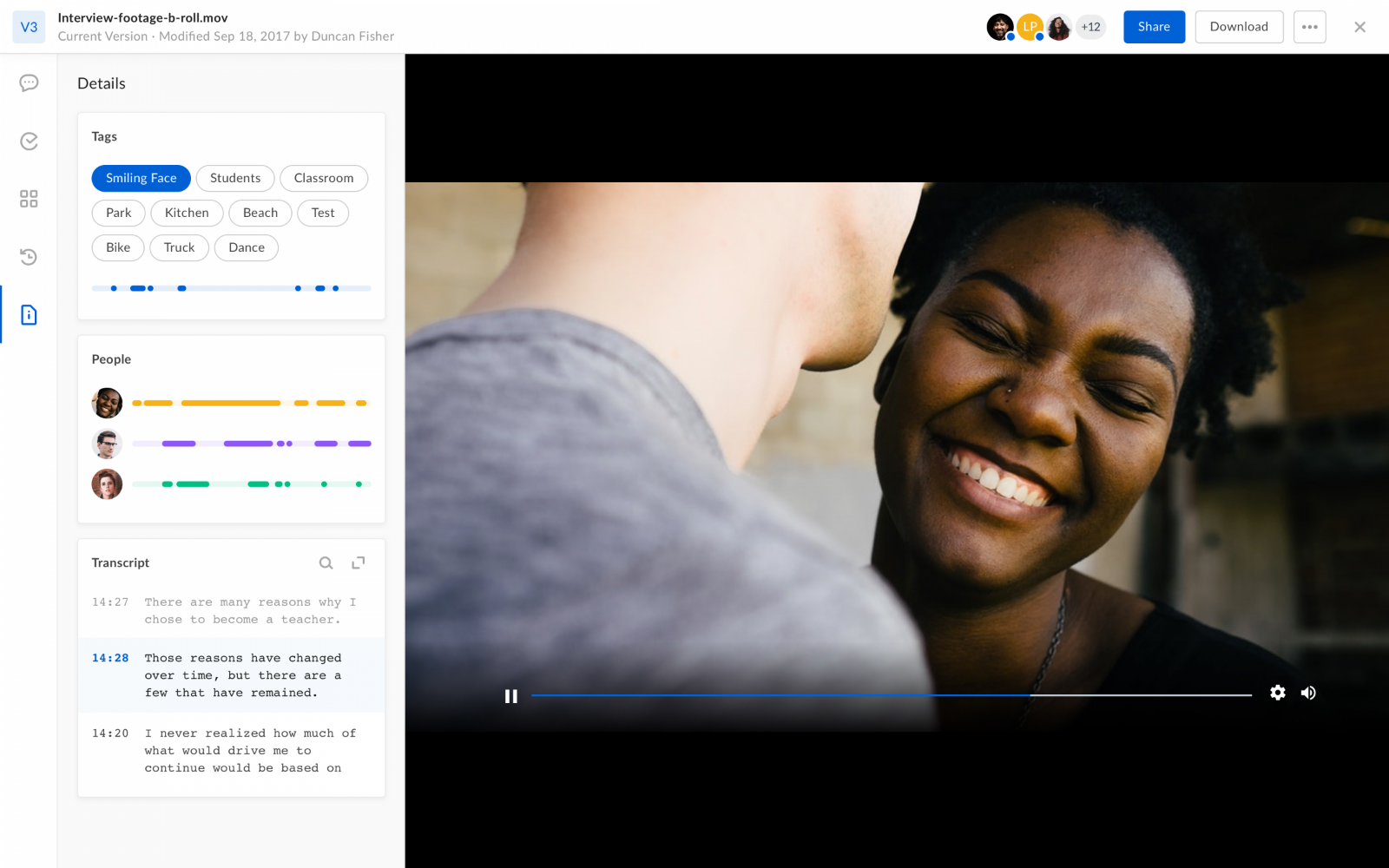
Box Skills让你可以对你的企业文件运用微软、IBM或者Google的AI技术。在这个例子中,Box会自动生产一个视频脚本,对其进行标记,然后识别每个演员,以及这个演员出现在视频的哪个片段中。
这时候就需要Box了,Levie说。Box将把AI作为自己的优势之一。随着在云中保存的数据量越来越大,组织这些数据也变得越来越困难。当企业寻求以一种更智能的方式来应对这种增长的时候,Levie希望这时候Box可以发挥作用。
“目前机器学习和AI用于这个问题的例子还比较少。在企业中,这是一个难题。”
Levie表示,按照这些方式,人工智能将开发发挥独有的作用,但是对大多数人来说使用人工智能还是一件很难的事情。像AWS、微软Azure和Google Cloud这样的平台,将提供越来越智能的服务来构建软件,但是你必须变得更加资深以利用这个优势。大多数公司在这个过程中可能需要一些帮助。
“在这方面我们将发挥作用,”Levie说。
Box是一家上市公司,并且华尔街显然认为Box有望不断成长——在撰写本文的时候,分析师普遍认为Box的目标价格将增长至每股24美元,高于目前的每股20美元。

Dropbox CEO Drew Houston
Box是一家拥有差异化技术的细分领域领导者,瞄准了移动设备和云计算市场,摩根大通在Boxworks大会后的分析报告中将Box股价评为“中性”。摩根大通表示,尽管Box有经营亏损的历史,但是Box的技术使其能够很好地应对Dropbox、微软和Google等云存储公司。
而且在云协同方面,Levie说他是以平常心看待Dropbox——最大的竞争对手,预计将在今年底IPO。
最近Dropbox重新设计公司标识,印证了Levie关于两家公司实际上是瞄准不同客户的说法。他说,虽然两家公司仍然在小企业领域是竞争关系,但是他相信Dropbox已经开始专注于高端用户和创意专业人士。Levie则着眼于大型企业。
“我们有非常不同的战略,我们面向的市场略有不同。”
好文章,需要你的鼓励


Netgear推出AI驱动网络管理平台,助力中小企业与服务商
Netgear发布云端网络管理平台Insight 10.0,引入AI驱动能力,专为中小型企业(SME)和托管服务提供商(MSP)设计。新版本提供智能运维、统一可视化、简化管理及云原生架构四大核心升级,支持自动化故障排查、设备健康监控及多站点集中管理,帮助IT团队从被动响应转向主动运维,解决中小企业长期缺乏企业级网络管理工具的痛点。

北京大学与DP Technology联手:用135M参数模型打败十亿参数级竞争者,像素级图像生成迎来新突破
北京大学与DP Technology提出PRA框架,通过16维低维中间状态与并行解码像素输入,同时解决像素空间自回归图像生成的高维预测误差和训练推断差距两大瓶颈,135M参数超越19亿参数模型。

旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

谢菲尔德大学的“词典革命“:一种不需要词典也能理解并生成语言的AI模型
MultiHashFormer用多个哈希函数替代传统词典,为生成式语言模型解决了哈希碰撞难题,在多规模测试中稳定超越标准Transformer,且支持零参数增量的多语言词汇扩展。
2017
10/25
16:51
分享
点赞

旧笔记本、台式机与打印机该如何正确回收处理
美国NRC提出核废料处置新规,为长期搁置问题开辟出路
OpenClaw 智能体正式登陆 iOS 与 Android 平台
智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Netgear推出AI驱动网络管理平台,助力中小企业与服务商
OpenClaw 智能体正式登陆 iOS 与 Android 平台
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
当数据库开始为Agent重写,OceanBase如何再造AI数据库?
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
