
Apeiron公司展示“火箭级”英特尔Optane阵列技术
“Optane已经被串连起来,而非作为孤立组件存在。”
Aperion公司发布的一款Optane阵列拥有五倍于原Apeiron闪存阵列之数据吞吐能力、六倍以上IOPS以及高达38倍的延迟削减效果。
在一项技术演示中,Apeiron方面将其配备有NVMe闪存驱动器的ADS1000存储阵列与搭载英特尔Optane 3D XPoint驱动器的版本进行了性能比较。
该公司全球销售与市场营销执行副总裁Jeff Barber介绍称:“我们对NAND与Optane进行了第三方测试,其中读取/写入负载为七比三比例,其中采用Optane的Apeiron产品仅拥有13微秒延迟,而NAND版本的延迟则高达500微秒。在大型数据块写入方面,Optane的性能亦达到NAND的10倍,且延迟仅为后者的二十五分之一。”
英特尔的P4800X为一款容量为375 GB的驱动器,采用3D XPoint存储器构建并因此拥有全面优于NAND的速度表现与使用寿命水平。
该存储方案属于一套外部阵列,可通过一套经过强化的2级以太网经由NVMe over Ethernet实现RDMA访问。访问服务器配备有Apeiron公司自主开发的主机总线适配器(简称HBA),该公司的目标在于确保访问配备SSD的共享式外部阵列时,这些服务器能够获得与SSD直连相对等的访问速度。
此次测试当中使用到的闪存驱动器为24块东芝7.68 TB SSD,而ADS1000则通过32个40 GbitE端口同五台戴尔及NEC x86服务器进行对接。每台服务器安装有两套双端口Apeiron HBA。
此后,Apeiron公司又对安装有内部Optane驱动器的同一服务器进行了性能测试,再接入配备Optane驱动器的ADS1000阵列进行再度测试。
该公司主要关注IOPS、数据吞吐量以及平均延迟等指标,并就此整理出测试结论。
Barber指出,“我们基本上通过与WWT的合作共同完成了面向Apeiron网络的NAND NVMe性能研究。此项测试中的每台服务器安装有四块驱动器,同时采用戴尔与NEC服务器结合的方式以确保Apeiron能够与一切x86第三代PCIe系统相兼容。”
“Apeiron随后与英特尔协作以测试多块Optane驱动器并运行了同一批VDBench脚本,这里使用的全部为‘现成’Optane产品(未针对Apeiron驱动器、HBA以及机柜进行任何优化)。……我们在同一数据块大小(最高256 K)前提下以七比三的读取/写入负载比例进行测试。”
以下图表所示为NAND版本ADS1000与Optane版本之间的IOPS、数据吞吐能力以及延迟水平对比:
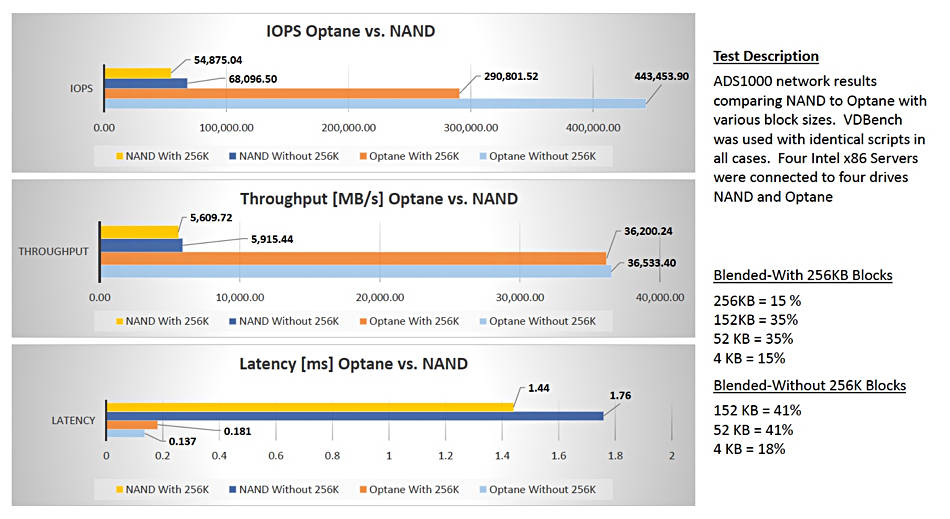
ADS1000阵列之NAND与Optane SSD两套版本间性能测试比较。点击查看大图。
Apeiron公司亦运行了FIO基准测试,Barber表示“FIO同样非常重要,因为其证明Apeiron网络并没有因此遭遇任何显著延迟提升。实际上,采用外部阵列时其速度表现甚至优于内部Optane驱动器安装方案。这意味着‘Optane已经被串连起来’,而非作为孤立设备存在。这将改变我们对于高性能计算、分析以及SAP HANA等工作负载的理解……”
以下图表为4K随机数据块读取性能结果:
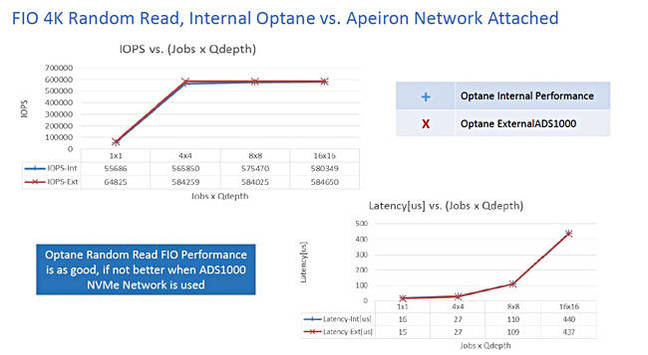
Apeiron公司的Optane DAS对Optane阵列FIO基准测试结果——条件为4K随机读取。
……以下图为128K数据块条件下的连续写入测试结果:
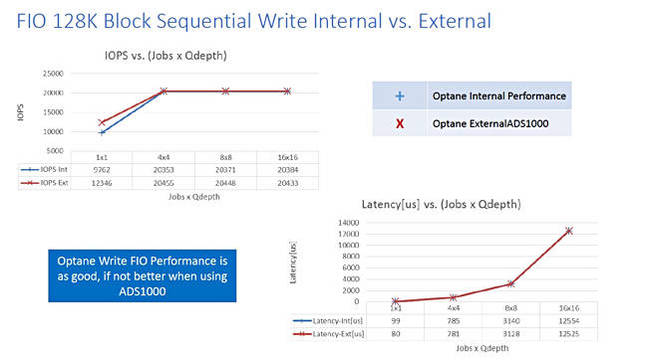
Apeiron Optane DAS对Optane阵列FIO基准测试结果——条件为128K连续写入。
评论意见
这是我们目前见到的第一项外部阵列Optane基准测试结果,而且明显可以看到RDMA over Ethernet所提供的访问性能水平与服务器本地访问Optane驱动器方案基本相当。
Apeiron公司的系统设计同时支持NAND与Optane SSD,而且可能还会支持其它速度更快的存储介质。该公司的关注重点在于展示,其传输体系与NVMe类似,即不会带来任何网络访问造成的性能损失,且阵列本身的性能亦可实现线性增长。从结果角度出发,这一证明过程基本获得成功。
我们的目标则在于比较NAND与Optane SSD的数据访问性能。
由于不清楚ADS1000所配备之Optane的具体价格,因此我们无法判断Optane的性价比究竟如何。不过很明显,Optane确实能够提升ADS1000的数据访问性能,我们也期待着Apeiron公司能够发布Optane性能白皮书并最终推出Optane ADS1000产品。
这样火箭级的高速阵列产品可能会在性能提升方面给几乎每一种外部块存储阵列带来发展启示。该公司亦可能已经制定出一份数据管理服务路线图,旨在进一步增加此类热门解决方案对企业客户的吸引力。
好文章,需要你的鼓励



Meta开发的AI编程助手,真的懂你吗?还是需要你反复“纠正“它才能干活?
Meta团队推出SWE-Together评测框架,将真实用户与AI编程的多轮对话转化为可复现的测试题,首次将"用户需要纠正AI多少次"纳入评分体系。

亚马逊 Mechanical Turk 将停止接受新用户注册
亚马逊宣布,其众包服务Mechanical Turk将于2026年7月30日停止接受新用户注册。现有用户可继续正常使用,AWS也将持续维护安全性,但不再引入新功能。该平台自2005年上线以来,曾是人工标注数据的重要来源,并在AI训练领域发挥过关键作用。然而近年来平台逐渐衰退,2023年研究显示33%至46%的任务已由大语言模型完成,平台价值受到质疑。业界普遍认为该服务已名存实亡。

AI模型的“肌肉记忆“:阿联酋人工智能大学揭示为何安全训练会被无害微调悄悄抹去
阿联酋MBZUAI研究团队发现,AI安全对齐后的"引力回归"现象:良性微调会沿着可预测的几何方向使模型悄悄恢复危险行为,且该方向可被测量和干预。
2017
06/13
16:30
分享
点赞

5060 Ti 16GB 跑本地 AI,真不如加钱买二手 3090?
散热为什么成了AI算力的“阀门”?
亚马逊 Mechanical Turk 将停止接受新用户注册
量子力学百年演进:从费解理论到改变世界的技术基石
Uber欧洲扩张计划遭遇阻碍,五国上线暂停
Claude Sonnet 5 发布:编码、推理与工具使用能力全面提升
AI高速扩张正悄然考验电网承载极限
福特对AI失望,重新雇用350名经验丰富的工程师
首批四家云服务商加入CISPE欧盟云主权认证计划
2026 Eurobike 展会:最值得关注的电动自行车与新奇产品盘点
联想Legion 7i Gen 10游戏本评测:颜值在线,性价比存疑
杀毒软件已不够用?全面了解现代网络安全防护
