
本届大赢家:SK海力士赚得成吨收入
韩国DRAM厂商与NAND制造商SK海力士公司公布其2017年第一季度实现营收增长,同时创下破纪录利润水平。

该公司本季度营收达到6.29万亿韩元,较上年同期增长72%,亦较上季度高出17%。净收入则为1.9万亿韩元,较上年同期提升惊人的324%,较上季度增幅则为17%。
另外,SK海力士公司亦借此创下破纪录利润水平。
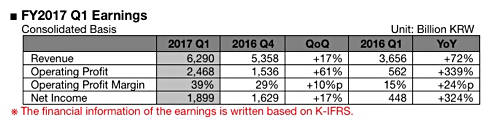
本季度净运营利润率为30%,而营收与利润的双重增长主要受到产品价格上涨的推动
在DRAM方面,该公司的出货总量下降5%,但产品平均售价(简称ASP)则上涨了24%。由于年初库存量低而引发的供应量受限状况导致了供应紧张,最终带来总出货量下降状况。然而,PC与服务器供应商的强劲需求仍然显著提高了产品的单位售价并因此带来出色的财报表现。
在财报电话会议当中,SK海力士公司总裁兼企业支持负责人Kim Jun-Ho表示:“云计算市场开始起飞,因此市场对于服务器DRAM的需求表现出极为强劲的势头。”
尼古拉斯公司分析师兼总经理Aaron Rakers表示,PC市场的缩水趋势正得以缓和。SK海力士预计将凭借着约20%的市场需求增长而继续享受这一DRAM供应量不足带来的红利。
DRAM营收在本季度占SK海力士公司整体营收的74%。
闪存产品同样迎来了类似的出货量增幅下降与平均售价提升趋势,其销售量缩水3%,但产品平均售价则提升了15%。移动产品与固态硬盘市场需求继续保持旺盛,而供应商的库存量则与DRAM一样处于较低水平。

SK海力士公司的72层3D NAND产品
Rakers指出,该公司本季度的NAND闪存营收约为13.3亿美元,占其总体营收中的24%。他认为SSD仅占全部闪存产品营收中的16%。
Kim Jun-Ho同时表示:“市场需求旺盛主要是受到中国智能手机NAND闪存需求量增长以及个人计算机SSD使用比例的提高所推动。”
着眼于未来,SK海力士认为DRAM需求量的增长主要受到系统内DRAM容量水平提升的推动,而非系统本身数量的增长。Kim Jun-Ho指出,“今年推出的新型智能手机将越来越多地采用双摄像头与改进型AI技术,而采用LPDDR4X等速度更快的移动DRAM将能够更好地支持这些先进功能。”
在服务器方面,随着云服务规模的持续增长,数据中心的需求量亦快速提升。众多供应商正在建立自有数据中心,而这仅成为云服务市场的普遍潮流。很明显,高容量DRAM模块能够帮助相关服务器提供低延迟与高处理能力优势。
在PC领域,“高端笔记本与游戏PC亦在不断提升内置DRAM内存容量,这也将给销售额带来增长。”
总体而言:“今年市场对于DRAM的需求量增长预计将超过20%,且需求增长量将超过供应能力增长。在另一方面,厂商并无能力显著提升DRAM生产能力,而对3D NAND的迫切需求也将导致针对DRAM的投资额保持在较低水平。”
SK海力士公司表示,其将扩大2Z纳米DRAM的生产能力,并在今年下半年开始大规模生产1X纳米DRAM。不过Kin Jun-Ho强调称,“我们认为这种供应能力短缺将持续至今年年底。”
在闪存方面,“今年市场对NAND的需求量增长预计将在30%到35%之间,而需求增长可能略微超过供应量增长……我们计划向移动市场内投放36层MLC产品,并面向高存储密度移动与SSD市场投放48层与72层产品。”
SK海力士公司正在参与东芝存储器业务的投标,如果其成功,那么东芝方面的NAND生产设施及容量将帮助海力士显著提升DRAM产能水平。
好文章,需要你的鼓励


大多数 AI 项目仅停留在构建阶段:为何主权控制是规模化成功的关键
尽管AI实验广泛开展,但大多数AI项目缺乏成熟度无法规模化。93%的组织在使用或构建AI系统,但仅不到10%建立了强健的治理框架。研究显示,超过50%的AI实验从未投产,仅1%的项目实现真正变革性成果。缺乏数据和AI主权是关键障碍,而拥有主权的组织AI项目成功率提升2倍,回报率增长5倍。

香港中大联合牛津等名校:AI视频已能完美骗过人工智能检测,连顶级模型都认不出真假
香港中文大学等顶尖院校联合研究发现,当前最先进的AI视频生成技术已能制作出连顶级检测系统都无法识别的假视频。研究团队开发了Video Reality Test平台,测试结果显示最强生成模型Veo3.1-Fast的假视频仅有12.54%被识别,而最强检测系统Gemini 2.5-Pro准确率仅56%,远低于人类专家的81.25%。研究还发现检测系统过度依赖水印等表面特征,音频信息能提升检测准确性,但技术发展已对信息真实性判断带来严峻挑战。

企业AI价值实现的五大人力准备障碍
企业正竞相释放AI的变革潜力,但真正的瓶颈不在技术而在人力准备度。Gartner研究显示,56%的CEO计划在未来五年削减管理层级,但91%的CIO未跟踪AI引发的技能变化。超过80%的领导者根本不衡量AI准确性。AI价值取决于员工适应和与智能机器共同发展的能力。CIO必须应对五个关键人力障碍:AI退出效应、中层管理困境、行为副产品、准确性悖论和影子AI现象,这些深层次的行为反射和组织动态如不解决将阻碍转型。

Google DeepMind让AI画图快了一半,“预览模式“让创作者告别漫长等待
Google DeepMind团队提出了革命性的"扩散预览"模式,通过ConsistencySolver技术实现AI图像生成的"预览+精修"工作流程。该技术能在5-10步内生成高质量预览图像,与传统40步完整生成保持高度一致性,用户体验测试显示总体时间节省近50%,大大提高了创作效率和创意探索的自由度。
2017
04/28
15:06
分享
点赞

大多数 AI 项目仅停留在构建阶段:为何主权控制是规模化成功的关键
企业AI价值实现的五大人力准备障碍
企业AI PC普及将在2026年放缓
AI闪耀中国!联想天禧AI亮相吴晓波科技人文秀
亚马逊全新通用型EC2 M8a实例正式发布
IBM推出SAP迁移管理工具应对2027年系统升级截止期
博通AI硬件收入激增65%,VMware业务稳健增长
英伟达发布Nemotron 3开源模型助力可扩展多智能体系统
从AI到模拟对抗,网络安全桌面演练今年有了新变化
Equity 2026年预测:AI智能体崛起、重磅IPO与风投行业变革
英伟达护城河难撼动,Gemini无法击败OpenAI
山河为证,荣誉加冕,华为乾崑助传祺向往S9首次智行中国顺利收官
