
思科打磨HALO和闪存 新推两款HyperFlex超融合系统
思科宣布推出了两款全闪存HyperFlex系统,性能最高提升了6倍之多。
HyperFlex是思科的超融合基础设施一体机(HCIA)产品,OEM Springpath的HALO软件,采用思科的UCS服务器和Nexus网络组件,是闪存和磁盘混合的系统。
现在有HyperFlex 220c和240c M4全闪存节点,都采用40Gbps网络。还会有3个或者更多这样的节点整合到单一系统中,有一堆UCS 6200或者6300系列框架互连。
该系统采用至强E02600 v4 CPU,每个插槽最多16个核心,最高1.5TB DDR4 DRAM,以及12Gbps SAS网络机制。这些节点采用Cisco Virtual Interface Card (VIC) 1227,并预装了vSphere ESXi 6.0软件。
下面这个表格显示了HX220c和HX240c混合配置和闪存配置的对比:
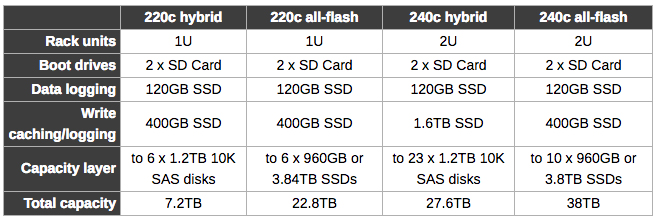
思科在博客中写道:“有了新的HyperFlex全闪存节点,以及第三代40 Gbit/s UCS框架网络,客户可以期待IOPS吞吐性能提高6倍之多,延迟缩短80%。”

思科HyperFlex HX240c硬件,最上面是全闪存版本
数据规格表中这样写道:“HX240c M4和HX240c M4全闪存节点可以配置采用各种UCS B系列刀片服务器和C系列机架服务器以搭建一个混合集群。”
评论
预计所有HCIA硬件厂商很快都将在他们的产品系列中增加全闪存的配置。这个市场如此火,没有哪个提供商可以忍受长期性能不利的问题。
好文章,需要你的鼓励


旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

三一学院与华为研究院联手出招:AI大模型“智能分诊“系统,省钱又省时
三一学院与华为联合提出两阶段AI模型调度框架:先按语义聚类分配最优模型,再用轻量分类器拦截低质回答升级处理,在保留97-99%最强模型准确率的同时显著降低推理延迟。

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
美国核管理委员会(NRC)近期提出对第61部分法规进行全面修订,首次为"超C类"(GTCC)低放射性核废料建立明确的许可处置路径。现有框架要求将其送入从未建成的深层地质处置库,形成"监管死胡同"。新规拟采用基于风险的分析方法,按废料实际放射性危害而非来源确定处置方式,约80%的GTCC废料或可适用近地表处置。这些废料目前分散存放于反应堆、医院及工业设施,新规将为其提供集中处置的可行路径。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。
2017
02/09
11:57
分享
点赞

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
OpenClaw 智能体正式登陆 iOS 与 Android 平台
智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
