
多孤岛数据访问加速初创公司Alluxio与Dell EMC签约合作
多孤岛大数据访问加速初创公司Alluxio去年与华为达成合作关系,最近又与Dell EMC就ECS产品签订了类似的协议。
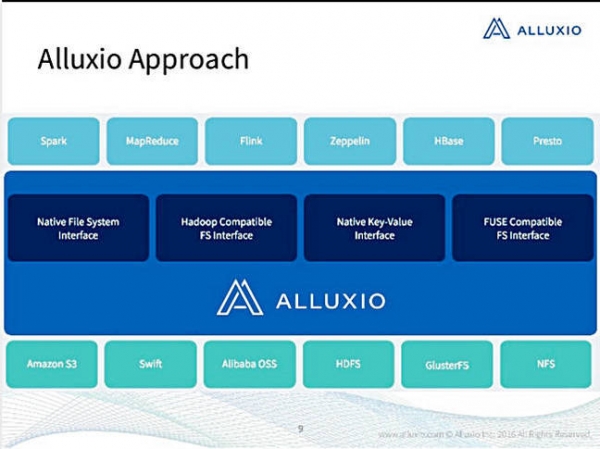
Alluxio解决的问题是,很多单独的存储机制是针对需要被多个分析型应用访问的大规模非结构化数据。每种应用(Hadoop、Spark、Storm、samza等)需要自己安排访问每个数据源(AWS S3、HDFS、Ceph、Isilon、Gluster等)。
Alluxio提供了一个中央软件层,能够通过他们选择的接口让上述任何一种应用访问任何一种数据源。这样能够不费力地做到像NVMe驱动器为PCI协议闪存数据存储所做的那样,为上层系统软件提供标准接口。
除了提供统一访问的Alluxio之外,开源代码提供了内存缓存来加速数据访问,包括读和写。
Alluxio graphic
Dell EMC与Alluxio的合作涉及到Alluxio企业版(AEE)和Dell EMC的Elastic Cloud Storage(ECS)对象存储服务器用于大数据工作负载。ECS曾经的代号是Nile。Dell EMC和Alluxio宣称,他们给"客户提供了DAS存储的替代选择,提供ECS的优点同时还有Alluxio AEE软件的性能改进"。
Alluxio首席执行官李浩源表示,Alluxio能够让ECS用作网关或者存储组件:"Alluxio为Dell EMC ECS客户提供了能够使用任何计算框架在本地或者云中以内存速度访问单独存储系统的灵活性。"
对于潜在客户来说,将Dell EMC与Alluxio这个组合与Dell EMC的DSSD D5相对比是有道理的,后者也提供了对大数据的高速访问。两者之间在速度和成本上的对比是很有意思的。
对于Alluxio来说,就在几个月前刚刚与华为签约之后又和Dell EMC签约,这是个好消息,其他存储提供商可能也会接踵而至,比如HDS、HPE和NetApp。
好文章,需要你的鼓励


OpenClaw 智能体正式登陆 iOS 与 Android 平台
开源AI智能体OpenClaw今日宣布正式推出iOS和Android应用。用户可通过手机连接OpenClaw Gateway路由层,调用AI智能体及其工具完成各类任务,涵盖编程、餐饮规划等场景。OpenClaw此前因MoltBook社交媒体实验走红,其创始人Peter Steinberger已于今年2月加入OpenAI。尽管MoltBook事件后来被揭露部分由真人假扮智能体,此次移动端上线标志着AI智能体正加速渗透日常生活。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2017
01/18
16:14
分享
点赞

智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
软件定义汽车时代:从“年”到“周”,研发团队如何高效驾驭复杂度?
美国消费品安全委员会拟出台电动自行车电池安全新规
Alluxio与北京大学计算机学院签署合作框架协议,推动产学研深度融合
戴尔科技集团释放边缘数据的价值
戴尔科技叠加态吐槽大赛
基于分级存储管理系统对流数据的贡献,Dell EMC Isilon获艾美奖
DELL EMC数据保护开始支持AWS和Azure中国国内的多云环境
戴尔科技集团推出全新存储、数据管理和数据保护解决方案
Dell EMC和超微发布基于英特尔新款至强Scalable芯片的服务器阵容
微软与Dell EMC合作为“战略边缘”提供Azure云
VMware收购Dell EMC Service Assurance Suite团队以增强网络服务能力
Dell EMC或将进行存储大整合:精简臃肿的产品组合
