
IBM:记住我们的话,认知计算需要闪存阵列

IBM公司已经于去年公布了其推出的三款DS8880整体阵列的对应全闪存版本,其闪存容量得到进一步提升同时将认知计算营销元素加入其中。
上代系统分别为DS8884、DS8886与DS8888。如今我们迎来了其全闪存衍生方案,全部以“F”后缀表示。这些阵列专门经过调整,旨在为大型机z Systems以及POWER中端服务器提供存储资源。
- DS8884F: 入门级阵列。设计目标在于各类传统应用,例如ERP、订单处理、OLTP、数据库、CRM以及人力资源信息系统。其中配备256 GB DRAM缓存与6.4到154 TB原始闪存容量。
- DS8886F: 中端产品,支持更为广泛的工作负载与应用类型。其中配备2 TB缓存与6.4到614.4 TB闪存容量。
- DS8888F: 高端分析级存储,具备更出色的性能与容量,适用于预测性分析、实时优化、机器学习、认知系统、自然语言语音与视频处理等。其中配备2 TB缓存与6.4 TB至1.22 PB闪存容量。
各闪存驱动器放置于IBM公司的高性能闪存外壳Gen2当中。这些闪存外壳与去年的DS8880系统同步推出,可在4U机架空间内提供400 GB、800 GB、1.6 TB以及3.2 TB闪存卡在座容量,同时支持RAID 5、6与10数据保护功能。
作为竞争对手,其它厂商的整体全闪存阵列往往拥有更为可观的闪存存储容量。日立公司的 VSP F800与F150最高存储容量可达8 PB。EMC的VMAX 850可达到4 PB,HPE的StoreServ 20000亦拥有3.9 PB存储空间。其部分原因在于,其它各厂商普遍采用容量在3.2 TB以上的闪存驱动器产品。
IBM公司介绍称,此系列新型阵列拥有更出色的“六个九”可用性,意味着正常运行时间达99.9999%——不及Infinidat的“七个九”,且可提供一致性微秒级应用响应时间——但未提供确切数字。
大型机z Systems与POWER服务器集成能力则是该系列新型阵列的另一大优势:
- DS8880F使得存储系统上的主机适配器能够利用DB2软件优先处理高优先级数据库I/O。
- DS8880F复制服务可面向AIX与IBM i实现与PowerHA SystemMirror的集成。
- DS8880F Metro Mirror可与PowerHA HyperSwap相集成,从而在主DS8880F发生故障或者计划内存储中断时将I/O操作切换至远程站点处。
- 其支持zHyperwrite技术,可将DS8880F与z/OS相结合以加快Metro Mirror环境下的DB2日志写入速度。
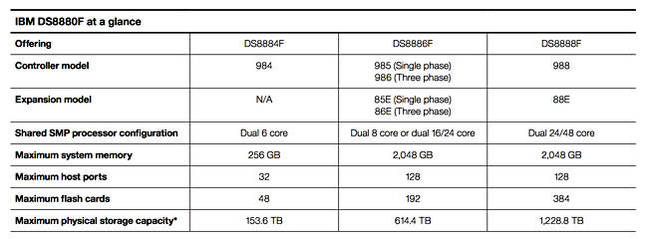
IBM DS8880F参数表
IBM公司还将其最新“认知”计算营销成果引入上述系统,表示其“考虑到认知工作负载对于高可用性及系统可靠性的严格要求,其非常适合由大型机与Power Systems加以承载。”
蓝色巨人同时告诉我们,该系列阵列可通过专利软件提供数据保护、远程复制以及中端及大型企业业务优化,从而同z Systems大型机产品顺利进行对接。

DS8880F机架设计示意图
IBM公司存储与软件定义基础设施总经理Ed Walsh指出:“DS8880全闪存阵列家族主要面向存在高延迟、低服务器利用率、高能耗水平、低系统极性及高运营成本等问题困扰的客户。”
他同时也提到了认知计算这一宣传元素,表示:“在刚刚到来的一年中,我们预计将有更多企业意识到认知型应用所带来的巨大发展机遇,同时利用云计算资源在数据驱动型市场上为其带来助力。”
IBM公司甚至进一步表示,“DS8880F基于同创新型IBM沃森解决方案同样的基础系统架构。”嗯,单从硬件角度来看,沃森采用的是一套包含90套Power 750系统的集群,各系统分别采用四块POWER7芯片,每块芯片拥有8个计算核心,意味着其计算核心总数为2880个(每个核心能够运行8个线程),外加16 TB内存。看起来两者的相同点并不多。DS8880F既没有使用沃森的DeepQA软件,也没有使用沃森中的Apache UIMA(即非结构化信息管理架构)构架。
总体而言,与沃森类似这样的说法似乎并不先说。也许我们应该直接问问沃森本“人”……或者说本“机”?
每套DS8880F系统标准配备加密驱动器,且能够支持密钥管理互操作协议(简称KMIP)。DS8880F还能够与VAAI(即阵列集成用VMware vStorage API)及vCenter站点恢复管理器进行交互,同时内置有一款vCenter插件用于存储管理。
新的DS8880全闪存阵列将于2017年1月20日正式通过IBM自身及其业务合作伙伴在全球市场销售。
好文章,需要你的鼓励



腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
作者对Chrome、Edge和Firefox三款主流浏览器的内置AI功能进行了实测对比。Chrome依托Gemini提供搜索摘要与提示词保存功能;Edge集成Copilot,可针对网页、PDF及多标签页进行问答;Firefox则支持多款AI聊天机器人,并提供更强的隐私保护。综合体验后,作者最终选择Edge作为AI辅助浏览的首选,但仍以Firefox作为默认浏览器。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2017
01/13
15:24
分享
点赞

当数据库开始为Agent重写,OceanBase如何再造AI数据库?
Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
Firefly宇航公司首次在月球轨道运行NVIDIA Jetson平台
超越数据驱动美学:计算与审美的跨世纪探索
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
Chamath Palihapitiya 为 AI 编程初创公司融资 1.35 亿美元并出任 CEO
Gemini 个性化 AI 图像生成功能现向美国用户免费开放
HP与OpenAI达成合作,共同部署企业级AI智能体平台
Windows 10 用户最长可免费获得安全更新至 2027 年
Raise Us:AI巨头联合出资5亿美元帮助劳动者应对AI时代冲击
MIT首届音乐科技研究展:AI与音乐共创的跨学科探索
特斯拉"完全自动驾驶"集体诉讼引用Electrek报道作为证据
