
选择道熵超融合的六大理由
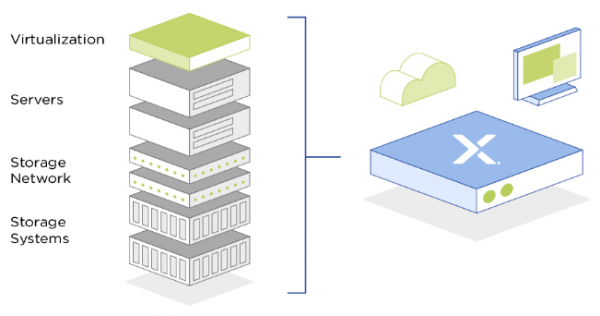
超融合基础架构(HCI)将具有本地存储资源的x86标准服务器硬件设备和虚拟化管理软件、分布式存储软件相结合,以创建灵活的IaaS基础架构,从而取代由单独服务器、存储网络和存储阵列构成的传统基础架构。其优势在于可降低总拥有成本、提高性能和 IT 团队的效率。
HCI 融合了整个数据中心堆栈,包括计算、存储、存储网络和虚拟化。运行于一站式行业标准x86服务器平台,取代了复杂且昂贵的传统基础架构,使企业能够从小规模起步,实现灵活扩展,可一次仅增加一个节点。在每个服务器节点上运行的软件可在集群中分配所有操作功能。超融合是服务器虚拟化技术的自然延伸和技术变革,通过分布式块存储实现对传统存储的替换,并可以支持第三方虚拟化平台或集成自有的虚拟化平台。超融合集成了软件定义、分布式和自动化运维带来的优势,形成了强大敏捷、可横向扩展的IT基础架构,是建设私有云的一种重要技术手段。
作为国内技术领先的磁盘阵列与分布式存储厂商,道熵旗舰产品---铁力士超融合采用了先进的双重RAID架构,将磁盘阵列的高可靠、高性能特点与分布式高扩展、易管理特性相融合,为企业提供超融合私有云与统一存储解决方案,满足用户数字化与智能化业务对IT能力的持续增长需求。
1业务更稳定、数据更安全
业务系统对连续性有极高要求,需要提供 7*24 的不间断服务,而数据中心一直面临着各种风险和挑战,包括停电、网络故障、硬件故障等问题,都有可能影响业务的连续性。铁力士超融合采用双重RAID架构,采用节点内RAID数据保护与节点间副本保护相结合的方式。每个节点采用RAID10或RAID50/60 实现节点内的本地数据保护、硬件故障隔离、与本地数据修护。每个节点相当于一个小型的“磁盘阵列”,可抵御节点内单个、甚至多个硬盘故障。这些“磁盘阵列”,通过网络连接与分布式副本技术管理,形成一个可扩展的分布式磁盘阵列,,保证在极端情况下,即当故障突破单台磁盘阵列的保护能力时,还可利用网络副本技术来恢复节点数据。正因为这种双层RAID保护机制,当节点硬件出现故障时,可以通过本地RAID对故障进行隔离,不影响业务正常运行。故障修复可以采用延迟修复的策略,自动避让业务,即当业务繁忙时,数据修复减慢数据;当业务空闲时,数据修复可以适当加快速度。
2业务更敏捷、资源交付更弹性
在传统的 IT 架构下,为满足业务系统的资源需求,用户需要独立采购软件和硬件设备;一般需要经历:预算-测试-招标-采购-部署-应用上线等流程,整个过程复杂、耗时,很难达到业务快速上线的目标。由于IT基础架构资源往往是基于某个业务系统上线而建立,与业务系统有比较强的耦合关系,资源之间无法流动,容易造成信息孤岛以及资源利用率较低等问题。此外,基于资源建设缺乏通盘的考虑,导致运维管理与扩展成本比较高。
铁力士超融合的显著优势之一就是业务更敏捷、资源交付更弹性。用户可通过虚拟机或容器,迅捷的上线业务,提高资源利用率。通过Web管理界面,将集群所有CPU、内存、网络、及存储等资源进行统一纳管,建设统一资源池,实现更灵活的资源划分与交付;上述资源具备“弹性伸缩”特性,可对资源进行生命周期管理,既可迅速扩展资源规模,也可及时回收“闲置”资源进行重分配。
3性能突出的统一数据存储平台
铁力士超融合的数据底座是基于双重RAID架构的铁力士分布式存储平台,具备磁盘阵列的高稳定、高性能的特点,以及分布式存储的弹性和高扩展性。除了虚拟化管理功能,铁力士超融合可作为企事业单位的统一数据存储平台,替代传统的磁盘阵列。铁力士分布式存储平台支持几乎所有的主流存储协议和接口,包含FC、iSCSI/iSER、NFS、Samba、Openstack Cinder、VMware VAAI、K8s CSI、S3、FTP、SFTP等,以及大数据接口HDFS、高性能计算BeeGFS、并行文件系统CephFS等。
铁力士超融合采用分布式两级缓存加速技术,实现性能加速。一级缓存为延迟低的DRAM,二级缓存为大容量固体硬盘,最热的数据保存在一级缓存中,次热的数据保存在二级缓存中。采用自适应算法管理缓存中的数据,能自动适应复杂业务工作流的变化,智能识别业务中最近使用的数据和频繁使用的数据,将其保存在缓存中。每个节点可单独增加一级缓存容量,和二级缓存容量,也可通过增加节点来增加总缓存容量。铁力士超融合可管理的总缓存容量,可高达数百TB,是名副其实的分布式存储“缓存之王”,能满足用户对存储性能弹性、可扩展的需求。
4、具有内置备份与容灾功能、性价比高
道熵铁力士超融合具备内置的定时备份功能,可对虚拟机实现全量备份和持续增量备份,并支持备份数据压缩、去重以及数据加密。备份数据可保持在本地或异地的NFS存储中,同时支持备份数据保持在支持S3存储接口的公有云或私有云中。
道熵铁力士超融合支持伸展集群(Stretched Cluster)部署,即同城双活数据中心:将超融合从一个数据中心(站点)扩展到两个数据中心(站点),以实现更高的可用性和容灾恢复。伸展集群通常部署在同一城市或园区之内,两个数据中心之间的距离通常不超过100公里,且有专用(或租用)的高速低延迟通信线路相连接。拉伸集群可实现站点维护计划以及满足容灾需求,因为一个站点的维护或意外丢失,无论是通信故障、意外掉电、火灾还是其他灾害,不会影响集群的整体运行。在拉伸集群配置中,两个数据站点都是活动站点,同时提供存储服务。如果其中一个站点发生故障,存储服务将自动切换到另一个站点。
当数据中心之间的物理距离超过100公里以上时,道熵铁力士超融合支持两地或多站点之间,通过异步复制技术手段实现远程容灾与恢复。其原理非常类似数据库如PostgreSQL或Mysql的主从同步机制,基于日志回放(replay)实现本地站点和远端站点数据同步。基于异步复制的远程容灾与恢复方法,可实现RTO < 数分钟,RPO 约等于零的容灾保护级别。
道熵铁力士超融合还具备存储虚拟化网关功能,可针对异构存储系统,实现统一数据管理与容灾备份管理,并可实现连续数据保护功能。
5扩展性好、持续硬件生命周期管理
在分布式存储的演进过程中,系统中可能会同时存在新增硬件和老旧硬件,而老旧硬件的故障率通常远高于新增硬件,这对分布式存储的数据可靠性提出了更高的要求,即要求分布式存储具有更强的抵御硬件故障的能力。而常见的三副本分布式存储,在存储规模稍大,存在硬件老化现象的情况下,系统同时出现两个或以上硬盘故障的概率不可忽视,就可能导致系统崩溃或数据丢失。
双重RAID架构,由于每个节点都具有本地RAID数据保护,可容忍的故障硬盘数目随节点增加而增加,可持续对硬件生命周期进行有效管理。当系统需要扩容时,可以在不停止业务的前提下,通过增加节点给存储加增CPU计算能力,内存,SSD,机械硬盘,以及网络资源,且能够实现数据自动迁移与平衡。同时,系统可以在线对故障硬件或老化硬件进行更换,甚至剔除整个节点。通过持续增加新硬件,剔除故障或老旧硬件,从而提高硬件的生命周期,有效降低硬件采购成本。
6故障隔离与自动化运维能力强
在传统架构下,随着 IT 规模增大,数据中心将引入更多不同的设备以及技术,这无疑增大了运维的复杂性,使得企业的 IT 人员经常上演“消防员”角色,即便是这样也难以达到“不间断”运行的目标。
道熵铁力士超融合的节点内RAID功能,并没有采用常见的硬件RAID控制卡来实现,而是通过功能更强大的存储虚拟化管理(Storge Virtualization Manager,SVM)来实现。SVM不仅实现了RAID10/50/60等RAID功能,而且具备池化管理和IO负载均衡能力,IO工作负载均匀分布在节点内所有磁盘上。SVM具备在线数据完整性校验和数据自修复功能,对硬件故障进行在线监测和有效隔离,即使在硬件老化时仍然能保证数据安全;功能强大的Web管理页面具有专门的自动化故障诊断模块,通过图形可视化收到实现监控各种运行状态,包括CPU、内存、网络、IOPS与带宽指标,同时具备对磁盘监控状态、网络、电源、主板等硬件的故障监控、报警、及自动化诊断功能,使得整个系统的运维与管理变得简洁直观。
来源:至顶网存储频道
好文章,需要你的鼓励


据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
当超级计算机被压缩进一个比书本还小的盒子里,这画面有多炸裂?想象一下,你桌面上摆着的不是什么花瓶摆件,而是一台能跑200B参数AI推理的"超算怪兽"——这就是我们今天要聊的主角:华硕Ascent GX10。

Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的“稀疏化魔法“
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。


不用再训练AI模型,香港科技大学团队发明“智能管家“,让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。
2021
04/22
15:42
分享
点赞

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
苹果发现:只需一个注意力层,就能让AI图像生成既快又好
YouTube推出基于Gemini 3的创作者游戏制作工具
英伟达是唯一能负担免费提供AI模型的厂商
OpenAI发布新旗舰图像生成AI模型GPT Image 1.5
脑启发算法可大幅降低AI能耗
Mac办公桌升级必备配件指南:提升工作效率的最佳选择
PTC Windchill+ 助力 HOLON研发全球首批符合汽车行业标准的 L4 级电动汽车
航旅行业的AI“乘法效应”:迈向指数级进化
OpenAI推出GPT Image 1.5模型加速图像生成竞争
Zoom推出AI Companion 3.0智能体工作流程
ChatGPT成为互联网最受阻止的爬虫机器人
五年16次迭代,云易捷超融合架构的进化与突破
Gartner 2024 年存储技术成熟度曲线发布,SDS不再是唯一变革性技术
IDC发布2023年中国整体超融合市场报告,深信服第一
超融合架构创新升级 开启企业应用现代化新篇章
面对瞬息万变的市场,Nutanix拿下创纪录营收
PowerFlex4.5:以不受约束的软件定义架构,实现不受限制的存储即服务能力
创新不息,更新无限 青云云易捷成就强大技术底座
Forrester发布超融合基础设施报告,VMware与Nutanix双雄并立
思科与Nutanix携手推出首款超融合产品,为合作伙伴提供更多机会
思科和Nutanix升级合作伙伴关系:带来的不仅仅是超融合基础设施
