
面对瞬息万变的市场,Nutanix拿下创纪录营收
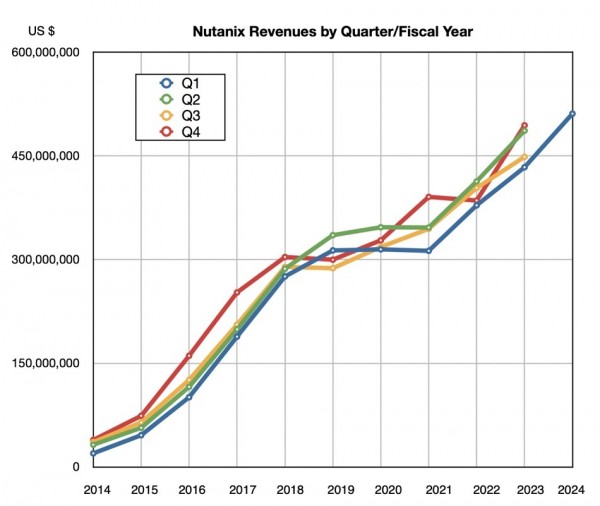
超融合基础设施软件提供商Nutanix宣布,其最近一个季度的营收创下历史新高、连续第八年保持增长,并首次达到20亿美元的年化收入水平。
截至10月31日的上季度,该公司收入为5.111亿美元,同比增长18%,亏损额为1590万美元,大幅低于去年同期的9910万美元亏损。新增客户380家,累计客户达到24930家。此外,Nutanix还启动了股票回购计划以提振其股价。
Nutanix公司总裁兼CEO Rajiv Ramaswami表示,“我们第一季度的业绩表现强劲,结果也超出了我们的预期。第一季度充满不确定性的宏观背景基本没有好转。”
公司CFO Rukmini Sivaraman也补充道,“2024年第一季度的表现相当不错,我们的所有指标都超出了预期上限。第一季度追加与扩展销售(ACV)额为2.87亿美元,高于2.6至2.7亿美元的预期区间,同比增长达24%。”
凭借件8月售出的GPT-in-a-box一体式系统,Nutanix在美国联邦政府业务方面的表现也强于预期。此外,Nutanix与思科的合作也迎来良好开端,思科已决定取消自家HyperFlex HCI产品,转而代售Nutanix方案。Ramaswami表示,Nutanix“在这款新产品上取得胜利,吸引到了那些原本打算购买思科HyperFlex的客户。”
但他在财报电话会议上也保持了谨慎的态度:“我们的渠道需要六到九个月时间才能完成交接。所以预计今年之内,由思科引流的客户可能不会太多。”
尽管宏观环境与上个季度相比无甚变化,但Sivaraman表示“与去年同期相比,我们发现平均销售周期略有延长。”
财务摘要
- 毛利率:84%,去年同期为81%。
- 自由现金流:1.325亿美元,去年同期为4580万美元。
- 运营现金流:1.455亿玩,去年同期为6550万美元。
- 现金与短期投资:15.7亿美元,去年同期为13.9亿美元。
Ramaswami希望“到2027财年,ARR复合年增长率能保持在20%左右,并在2027财年产生7到9亿美元的自由现金流。”
Nutanix 2024年第二财季的收入预期为5.5亿美元(上下浮动500万美元),年增长率预计为13.1%。目前全年预期营收为21.1亿美元(上下浮动1500万美元),比上年中位数增长13.3%。Sivaraman指出,“尽管宏观环境存在不确定性,但我们的解决方案仍然拥有新的扩展机会。”相应的,Nutanix已经上调了2024财年的所有预期指标,包括营收、ACV销售额、非GAAP营业利润率、非GAAP毛利率以及自由现金流等。
另一项利好消息,就是Red Hat OpenShift将运行在Nutanix之上。Ramaswami提到,Red Hat在应用业务层与VMware存在竞争关系,而Nutanix在基础设施层与VMware同样有所交集,所以Red Hat与Nutanix天然站在统一战线。部分Nutanix客户也在使用OpenShift,包括全球2000强银行。亚太地区的一家2000强银行就选择了Nutanix,希望借此避免VMware在加入博通后的业务不确定性。由此看来,Nutanix本季度的强劲业务表现也在一定程度上得益于这种不确定性。
但长远态势究竟是好是坏,目前还很难说。毕竟而且部分VMware客户也签署了长期协议,不得转投Nutanix的怀抱。
Ramaswami也在财报电话会议上提到了这一点,表示“在担忧情绪的推动下,我们获得了大量机会,能够与更多潜在客户接洽交流。但是,很难预测这种态势能不能长期保持下去。”
总体而言,VMware竞争力减弱与思科退出HCI市场给了Nutanix巨大的机会空间。只要能够妥善把握,相信Nutanix将在未来几个季度、甚至几年之内保持积极的业务增长幅度。
好文章,需要你的鼓励


大众汽车推出两款平价电动车,加速欧洲电动化布局
大众集团旗下首款平价电动车ID. Polo与Cupra Raval已在西班牙马托雷利工厂正式下线。两款车型分别起售于24,995欧元和26,000欧元,同属"电动城市车家族"系列,基于MEB+共享平台打造,节省约6亿欧元成本。ID. Polo提供37kWh和52kWh两种电池选项,续航最高454公里;Cupra Raval续航约450公里。大众集团CEO表示,此举旨在加速欧洲电动化进程,应对比亚迪等中国品牌的市场竞争压力。

只需一次点击,AI就能认出所有同类细胞——首尔国立大学的这项新技术让病理分析效率提升百倍
首尔国立大学提出CoP框架,只需每种细胞点击一次,即可自动分割病理图像中所有同类细胞,比逐实例标注减少97%工作量,且无需任何额外训练。

模块化设计:数据中心建设加速的十大关键组件
施耐德电气在2026年Datacloud全球大会上探讨了数据中心模块化设计的未来。随着部署周期从5年缩短至18至24个月,加之GPU硬件刷新加速,数据中心运营商正加速采用模块化设计方案。通过标准化组件与固定配置,模块化设计可有效压缩交付周期、提升可扩展性。本文重点梳理了十大模块化数据中心设计核心组件,助力运营商优化设计与组装流程。

当扩散语言模型遇上强化学习,UCL、阿里巴巴等机构联合提出新训练方法,彻底绕开“估算陷阱“
扩散语言大模型强化学习因策略概率不可计算而受限,GDSD通过引导去噪器自蒸馏,完全绕开ELBO估算,消除训练-推理不匹配偏差,在多个基准上提升最高近20%。
2023
12/01
14:49
分享
点赞

大众汽车推出两款平价电动车,加速欧洲电动化布局
模块化设计:数据中心建设加速的十大关键组件
Dreambeans:谷歌推出最新AI应用,将你的生活变成动态故事
发那科发布11公斤"最轻"协作焊接机器人
Robotiq推出AI平台,大幅提速机器人工作单元集成效率
ABB与萨尔茨堡研究人员联合申请AI专利,助力工业机器人节能降耗
迅达扩充电梯安装机器人机队,建筑自动化需求持续攀升
AGI或将在三年内到来,DeepMind CEO发出警告
2026中国光网络研讨会开幕:产业链齐聚北京,共探AI时代光通信未来
Liftoff 宣布首次公开发行定价
Gemma 4 12B:谷歌推出可在16GB内存笔记本上运行的新模型
英国监管机构要求谷歌在AI搜索结果中明确标注来源并允许出版商选择退出
