
百度智能云发布新一代智能计算操作系统“万源”,革新AI原生应用开发体验
4月16日,Create 2024 百度AI开发者大会在深圳召开。期间,百度集团执行副总裁、百度智能云事业群总裁沈抖正式发布新一代智能计算操作系统——万源,通过对AI原生时代的智能计算平台进行抽象与封装设计,为用户屏蔽掉云原生系统与异构算力的复杂性,提升AI原生应用开发效率与体验。
沈抖表示,随着大模型技术的不断演进,通过自然语言进行编程正在成为现实。编程将不再面向过程或者面向对象,而是面向需求;编程的过程将成为开发者表达愿望的过程,并为操作系统带来革命性的变化。在操作系统的内核中,底层硬件从以CPU算力为主变成以GPU算力为主,并且新增了被大模型压缩的世界知识。操作系统管理的对象发生了本质的变化,从管理进程、管理微服务,进化为管理智能。

(百度集团执行副总裁、百度智能云事业群总裁沈抖)
“传统的云计算系统依然重要,但不再是主角,我们需要一个全新的操作系统,对新的计算平台,也就是智能计算做好抽象和封装,重新定义人机交互,为开发者提供更简单、更流畅的开发体验。”沈抖如是说。

(百度智能云发布新一代智能计算操作系统——万源)
本次大会上,百度智能云全新推出的“万源”智能计算操作系统,旨在“桥接”算力效能与应用创新。具体来讲,万源主要由Kernel(内核)、Shell(外壳)、Toolkit(工具)三层构成,底层屏蔽掉云原生系统与异构算力的复杂性,上层则为AI原生应用的敏捷开发提供支撑与保障。
首先,在内核层,在算力资源管理方面,百度百舸·AI异构计算平台针对大模型训练、推理等任务,对智算集群的设计、调度、容错等环节进行了专项优化。目前,百舸能够实现万卡集群上的模型有效训练时长占比超过98.8%,线性加速比、带宽有效性分别高达95%,算力效能业界领先。
此外,百舸还兼容昆仑芯、昇腾、海光DCU、英伟达、英特尔等国内外主流AI芯片,支持用户以最小代价完成算力适配。相比模型推理,“一云多芯”在模型训练场景中是极难攻坚的难题,主要包含两类细分场景:
1、智算集群中存在多个训练任务,单一厂商芯片只服务单一任务;
2、在每个独立的模型训练任务中同时使用不同厂商芯片。这就需要解决不同厂商芯片算力均匀切分、芯片间通信效率优化等问题,难度极高。
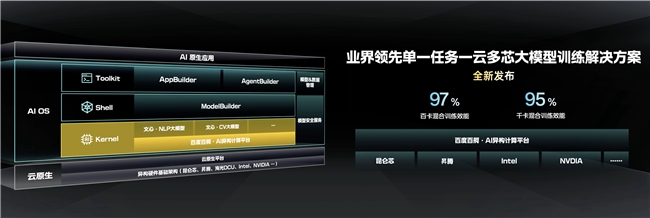
(业界领先的单一任务一云多芯大模型训练解决方案)
目前,百舸已经实现了单一训练任务下不同厂商芯片的混合训练,且百卡规模性能损失不超过3%,千卡规模性能损失不超过5%,业界领先。最大程度上屏蔽硬件之间差异,帮助用户摆脱单一芯片的依赖,实现更优成本,打造更具弹性的供应链体系。
万源内核中的另一个重要组成部分是大模型。大模型能够将巨量的世界知识进行高效压缩,并将自然语言的理解、生成、逻辑、记忆能力进行封装。目前,万源内核中既包含了业界领先的ERNIE 4.0、ERNIE 3.5大语言模型,也包括ERNIE Speed/Lite/Tiny等轻量级模型、文心视觉大模型和各具特色的第三方大模型,充分满足用户在不同业务场景下的多样化需求。
在内核层之上是Shell层,通过百度智能云千帆ModelBuilder解决内核中模型的管理、调度、二次开发等问题,屏蔽掉模型开发的复杂性,帮助更多人只投入少量的数据、资源和精力,就能快速精调出适合自己业务的模型。同时,在实际应用中,ModelBuidler提供的模型路由服务,能够自动为不同难度的任务选择合适参数规模的模型,给出平衡效果与成本的最优模型组合。经测算,在模型效果基本持平的情况下,模型路由平均降低推理成本多达30%!
在Shell层之上,千帆AppBuilder和AgentBuilder共同构成了工具层,为开发者提供强大的AI原生应用开发能力。尤其是AppBuilder提供的工作流编排功能,支持开发者使用预置的模板和组件,轻松定制自己的业务流程,还能够集成、扩建自己的特色组件,在不同节点上选用适合的模型,通过灵活的编排实现业务逻辑。
在AppBuilder上开发AI原生应用的过程中,还可以直接调用通过ModelBuilder精调过的模型,让整个开发过程变得极为流畅和便捷。在应用开发完成后,可以一键发布到百度搜索、微信公众号等平台,也可以通过API或SDK的方式直接集成到用户自己的系统中,真正做到极速开发、轻松上市。
万源作为开放的操作系统,未来还将进一步开放生态合作,为应用开发者提供更多能力和接口;助力企业打造专属的垂直行业操作系统;将万源部署在客户自有智算中心,提供稳定、安全、高效的智能计算平台服务;适配更多厂商异构芯片并发挥其最大效能。
当前,大模型技术与AI原生应用正在促使云服务向以AI为核心的新一代智能计算操作系统方向发展,这一趋势不仅反映了技术发展的内在逻辑,也体现了市场需求的强劲推力,并开启一个由AI驱动的崭新的智能云时代。
来源:业界供稿
好文章,需要你的鼓励


微软质量控制问题愈演愈烈
微软近年来频繁出现技术故障和服务中断,从Windows更新删除用户文件到Azure云服务因配置错误而崩溃,质量控制问题愈发突出。2014年公司大幅裁减测试团队后,采用敏捷开发模式替代传统测试方法,但结果并不理想。虽然Windows生态系统庞大复杂,某些问题在所难免,但Azure作为微软核心云服务,反复因配置变更导致客户服务中断,已不仅仅是质量控制问题,更是对公司技术能力的质疑。

Meta的单字符革命:一个小符号如何颠覆AI评测体系
Meta研究团队发现仅仅改变AI示例间的分隔符号就能导致模型性能产生高达45%的巨大差异,甚至可以操纵AI排行榜排名。这个看似微不足道的格式选择问题普遍存在于所有主流AI模型中,包括最先进的GPT-4o,揭示了当前AI评测体系的根本性缺陷。研究提出通过明确说明分隔符类型等方法可以部分缓解这一问题。

开源 AI 及其在当今世界中的重要作用
当团队准备部署大语言模型时,面临开源与闭源的选择。专家讨论显示,美国在开源AI领域相对落后,而中国有更多开源模型。开源系统建立在信任基础上,需要开放数据、模型架构和参数。然而,即使是被称为"开源"的DeepSeek也并非完全开源。企业客户往往倾向于闭源系统,但开源权重模型仍能提供基础设施选择自由。AI主权成为国家安全考量,各国希望控制本地化AI发展命运。

香港中文大学团队推出STORM:让4B小模型挑战671B巨型模型的优化建模新方法
香港中文大学研究团队开发出CALM训练框架和STORM模型,通过轻量化干预方式让40亿参数小模型在优化建模任务上达到6710亿参数大模型的性能。该方法保护模型原生推理能力,仅修改2.6%内容就实现显著提升,为AI优化建模应用大幅降低了技术门槛和成本。
2024
04/16
14:24
分享
点赞

影翎A1即将亮相DDC2025!影石Insta360携手地瓜机器人重塑飞行大脑
Qorvo推出宽带高效功率放大器QPA9510,助力简化Sub-1GHz射频设计
关于现代化,我们真正需要讨论的是什么?
微软质量控制问题愈演愈烈
开源 AI 及其在当今世界中的重要作用
OpenAI Sora与谷歌Veo 3 AI视频生成对比测试结果出炉
iPhone卫星连接技术五大升级方向曝光
AI助力阿尔茨海默病治疗突破
测试智算性能!新一期国际排行榜AIPerf发布
ChinaSC 2025:产学研聚力,解锁智能算力经济新未来!
联想再登中国HPC TOP100第一,多元算力加速超智融合新进程 斩获多奖!联想多元算力布局引领产业新征程
Gartner:趋势不是终点,而是通往下一个时代的坐标
