
向更高画质时代进军 慧荣SM2708主控让SD卡媲美固态硬盘
如今一提到8K 10bit HDR这类的视频录制,最先考虑的就是只能使用价格昂贵的CF express存储卡。因为CF卡如今已经可以支持PCIe总线和NVMe协议,和我们使用的SSD固态硬盘在同一起跑线。反观SD存储卡还正处在最高UHS-II阶段,两者在性能上有着非常大的差距。
为了补足SD存储卡在性能方面的短板,SD协会就开始布局新的SD Express规范,以达到提升SD存储卡性能的目的。随即SMI慧荣科技针对该规范发布了旗舰型SM2708 SD Express控制器解决方案,该解决方案支持最新 SD 8.0 规范并兼容UHS-I规格,用户可以与最新的SD Express卡技术无缝衔接。
SM2708 SD Express控制器解决方案采用PCIe Gen3 x2 接口及NVMe 1.3规范,并支持最新一代 3D NAND,搭载慧荣科技独有的 NANDXtend® ECC 技术、数据路径保护和可编程固件,可大幅提高3D NAND 的可靠性和耐用性,完美提供超高性能来满足各行业对数据存储性能要求严苛的应用需求。
目前威刚科技已经与慧荣科技进行了深度定制,推出了基于SM2708主控的ADATA 512GB SD Express存储卡,接下来笔者就通过测试来看看SM2708主控的性能如何。

为了能够彻底发挥出SM2708主控的性能,我们选择了瑞昱半导体RTL9211DS主控制芯片的读卡器,也是最新一代支持SD8.0/SD7.1协议的读卡器,由于还未上市,所以笔者拿到的也是工厂内测款。

据了解,瑞昱RTL9211DS主控制器是业界唯一支持PCIe ASPM主动电源状态管理协议的方案,能有效降低SD8.0/SD7.1记忆卡使用时所产生的热功耗,提供系统更加稳定、可靠的存储环境。
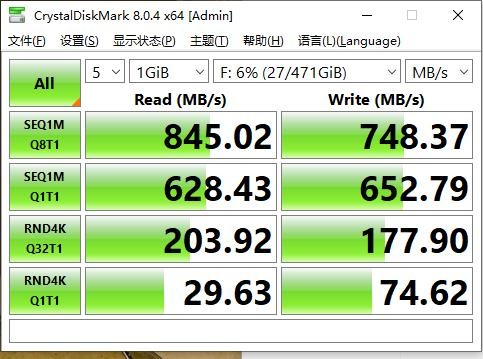
通过大家都比较熟悉的CrystalDiskMark测试,能够看出基于SM2708主控的威刚ADATA SD Express存储卡顺序读取速度达到845MB/s,顺序写入速度也高达748MB/s,性能表现非常优秀。

AS SSD Benchmark是测试固态硬盘的专用软件,相对传统SD卡很少用该软件。不过目前SD Express存储卡同样也是基于PCIe总线和NVMe协议,所以还是有很大参考意义的。从测试成绩来看,总分1358分已经与主流桌面SSD性能不相上下,尤其是小文件的4K 64队列深度下,写入性能达到740MB/s,完全可以作为笔记本的扩展硬盘使用。
在实际文件拷贝测试中,分别测试了威刚ADATA 512GBSD Express存储卡的读取和写入能力。测试文件为《星际穿越》的高清蓝光版片源,容量大小接近18GB。
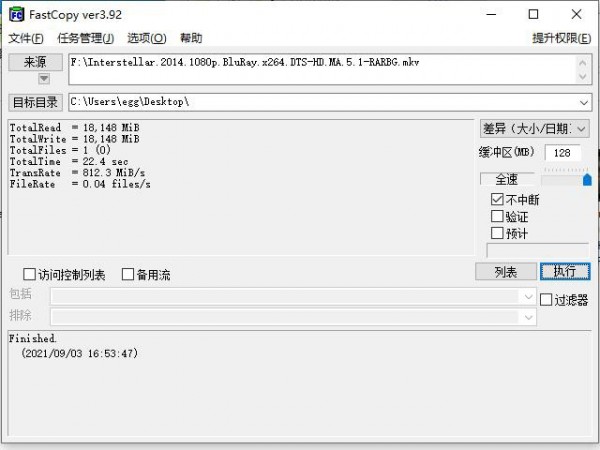
当文件从存储卡拷贝到电脑桌面时,反映的是存储卡的读取性能。使用FastCopy软件完成拷贝后,看到读取速度达到812MB/s,仅用时22秒就完成了拷贝,这样的性能确实令人大跌眼镜。
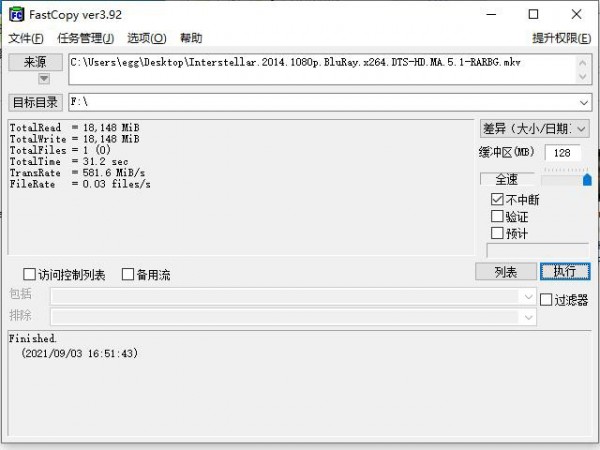
再降文件从桌面拷贝到存储卡后,FastCopy软件显示为拷贝速度581MB/s,写入时间为31秒,同样性能出众。
观点总结:
通过测试不难看出,慧荣科技发布的SM2708主控新品将SD存储卡的性能提升到前所未有的新高度,可以媲美固态硬盘的读写速度可以应对未来更高端的相机、汽车存储及其它需要超高数据存储等应用。
并且SD Express存储卡也给移动硬盘领域提供了新的方向,能够将产品更加迷你化,提升便携性,同时又具备很高的读写速度,相信未来基于SM2708主控的存储卡会很快获得市场认可,不断引领SD存储介质向更高速和更大容量发展。
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2021
09/17
14:14
分享
点赞

从芯片基础创新,看AI存储性能未来演进
发热不再是问题 慧荣台北电脑展展出SM2508 PCIe 5.0主控
开启AI存储时代慧荣企业级SM8366主控亮相CFMS2024
多元化发展 盘点SMI慧荣2023年有哪些SSD新技术、新产品
铠侠发布 2TB microSDXC 存储卡
三星推出新款PRO Ultimate 系列存储卡,提供更高的速度和可靠性
FMS 2023再现慧荣企业级PCIe 5.0,现场演示服务器首配ZNS QLC固态
2023 COMPUTEX:SMI现场实测MonTitan Gen5企业级SSD
慧荣科技于2021年OCP全球峰会上展示全系列企业级SSD存储解决方案
向更高画质时代进军 慧荣SM2708主控让SD卡媲美固态硬盘
