
如何选择超融合(一)稳定性与数据安全性考虑
什么是超融合:论到当今企业级IT市场最火热的产品,非超融合莫属。超融合已成为企业数据中心及私有云IaaS层最重要的选择。
百度百科对“超融合基础架构”的定义:是指在同一套x86单元设备中不仅仅具备计算、网络、存储和服务器虚拟化等资源和技术,而且还包括备份软件、快照技术、重复数据删除、在线数据压缩等元素,而多套x86单元设备可以通过网络聚合起来,实现模块化的无缝横向扩展(scale-out),形成统一的计算与存储资源池。
作为近几年来IT市场上风头正盛的新产品,超融合的年市场增长率高达20-30%以上,从最早的备受质疑,到后来逐渐被市场接受,再到今天的大放异彩,超融合的发展轨迹同历史上那些里程碑式的产品何其相似,这也侧面说明了超融合的诞生是具有颠覆性意义的。
硬件层面:超融合基础架构实现了计算、存储、网络等资源的统一管理和调度,具有更弹性的横向扩展能力,可以为数据中心带来最优的效率、灵活性、规模、成本和数据保护。使用计算存储超融合的一体化平台,替代了传统的服务器加集中式存储的架构,使得整个架构更清晰简单,极大简化了复杂IT系统的设计。
软件层面:“虚拟化”是超融合技术的重要组成部分。超融合设备通常会充分使用计算、网络、存储和服务器虚拟化技术,使得这些资源池化成为云资源,更好地适应云计算的需求。使用虚拟化技术以后,虚拟化层就会把用户的应用和物理设备隔离开,从而使硬件的无缝扩展和超强容错成为了可能。
开箱即用、无缝扩展、超强容错、高性价比以及一站式服务,构成了超融合设备的核心客户价值。
超融合的灵魂在于分布式存储:超融合的核心功能是分布式存储系统和统一的存储资源管理平台。Google采用GFS建立了云计算数据中心场景下的分布式存储系统;在企业端也存在IT扩容升级的需求,虽然计算可通过服务器虚拟化容易实现,但基于传统SAN和NAS存储的性能与容量扩展与升级非常困难。而超融合采用分布式存储技术,同传统存储最大的不同就是可扩展性更强。毫不夸张地说,分布式存储是超融合的灵魂。
传统SAN和NAS存储采用多控制器共享架构和RAID技术实现数据保护与业务高可用,具有稳定性强、IO性能高的特点,但扩展困难,容易形成数据孤岛。此外,SAN和NAS存储的硬件生命周期为3到5年,到期需要执行繁琐的数据迁移操作,运维管理十分困难。超融合采用通用x86硬件和分布式存储技术,通过随机哈希(Hash)算法将数据的多个副本均匀分布在各个节点上,因此容易扩展。当磁盘损坏或服务器硬件老化时,可分批次逐渐更换,具有可持续的硬件生命周期管理,而无需执行繁琐的数据迁移。
国内市场上主流的超融合厂商有VMware、华为、新华三、深信服、道熵、SmartX等。VMware采用VSAN 三副本保护机制,只能在VMware的虚拟化环境中使用;华为/新华三的分布式存储属于Ceph路线,采用三副本;深信服的分布式存储建立在GlusterFS基础上,属于三副本范围;而道熵的铁力士分布式存储则采用双重RAID架构,在接口层兼容Ceph块、对象和文件系统协议,底层采用具备存储虚拟化的RAID技术,因此兼具分布式高扩展和传统磁盘阵列的高稳定性和高性能的特长。SmartX采用了类似GFS分布式文件系统的架构,采用三副本数据保护。
三副本vs双重RAID:
超融合的核心在于分布式存储,而对存储最基本、最首要的要求,就是稳定性与数据安全性。
以Ceph为代表的三副本分布式存储,采用无中心分布式元数据管理的CRUSH算法,将每个数据块的三个副本(一主两从)随机保存在三个存储节点上。当某个硬盘损坏时,CRUSH算法可以自动再平衡(re-balance)数据,以最快的速度确保每个数据块都有三个副本。
上述三副本工作机制带来以下几个问题:
- 每次数据写操作需要写到三个不同的存储节点,导致跨节点网络开销大,以及较大迟延,拉低系统IO整体性能
- 在数据再平衡过程中,容易导致重建“风暴”,导致性能下降25%-75%,甚至产生OSD flapping等不稳定现象
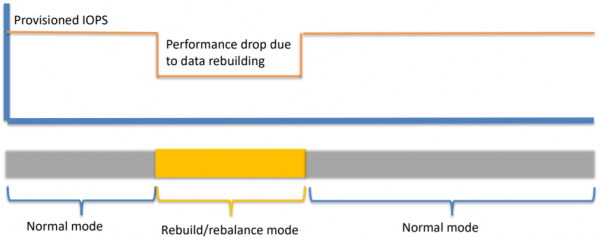
- 三副本最大可容忍2个机械硬盘同时损坏,当系统出现第3个硬盘故障时,极有可能导致数据丢失、系统崩溃
为应对三副本分布式存储面临的问题,道熵铁力士超融合创造性提出了双重RAID机制,既保留了Ceph无中心分布式元数据管理带来的高扩展性特征,又通过节点内RAID解决了Ceph所面临的稳定性及数据安全性的缺陷。其基本原理是:每个存储节点通过存储虚拟化技术,把节点上的所有磁盘构成一个具有RAID功能的存储池,在其上构建多个虚拟卷vOSD,通过CRUSH分布式数据管理,产生跨节点两副本。这种节点内RAID与跨节点的网络副本相结合的方式,构成了对数据的两重RAID保护,因此简称为双重RAID机制。
双重RAID机制与三副本相比,具有以下优势:
- 每次数据写操作仅需要写到两个不同的存储节点,节约跨节点网络开销1/3,可显著降低写延迟,提升系统IO性能
- 当硬盘损坏时,可通过本地(节点内)RAID功能对数据实现修复,无需消耗宝贵的网络资源,因此可消除网络重建风暴。在重建过程中,vOSD仍然保持健康状态,可避免OSD flapping等不稳定现象
- 由于本地RAID的存在,每个节点最大可容忍一个或多个硬盘故障,仍然保证数据安全。随着节点数增加,整个存储系统可同时容忍的最大硬盘故障个数随之增加。因此,其故障容错能力与数据安全能力,显著优于三副本机制
总结:超融合的灵魂在于分布式存储。主流的超融合建立在Ceph、vSAN、GlusterFS等分布式存储技术基础之上。超融合的分布式存储可分为随机哈希控制下的三副本数据机制和双重RAID机制,其中,以道熵铁力士超融合为代表的双重RAID机制,在稳定性与数据安全性方面具有得天独厚的技术优势。
来源:业界供稿
好文章,需要你的鼓励


OpenClaw 智能体正式登陆 iOS 与 Android 平台
开源AI智能体OpenClaw今日宣布正式推出iOS和Android应用。用户可通过手机连接OpenClaw Gateway路由层,调用AI智能体及其工具完成各类任务,涵盖编程、餐饮规划等场景。OpenClaw此前因MoltBook社交媒体实验走红,其创始人Peter Steinberger已于今年2月加入OpenAI。尽管MoltBook事件后来被揭露部分由真人假扮智能体,此次移动端上线标志着AI智能体正加速渗透日常生活。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2021
06/08
17:13
分享
点赞

智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
软件定义汽车时代:从“年”到“周”,研发团队如何高效驾驭复杂度?
美国消费品安全委员会拟出台电动自行车电池安全新规
五年16次迭代,云易捷超融合架构的进化与突破
Gartner 2024 年存储技术成熟度曲线发布,SDS不再是唯一变革性技术
IDC发布2023年中国整体超融合市场报告,深信服第一
超融合架构创新升级 开启企业应用现代化新篇章
面对瞬息万变的市场,Nutanix拿下创纪录营收
PowerFlex4.5:以不受约束的软件定义架构,实现不受限制的存储即服务能力
创新不息,更新无限 青云云易捷成就强大技术底座
Forrester发布超融合基础设施报告,VMware与Nutanix双雄并立
思科与Nutanix携手推出首款超融合产品,为合作伙伴提供更多机会
思科和Nutanix升级合作伙伴关系:带来的不仅仅是超融合基础设施
