
面对瞬息万变的市场,Nutanix拿下创纪录营收
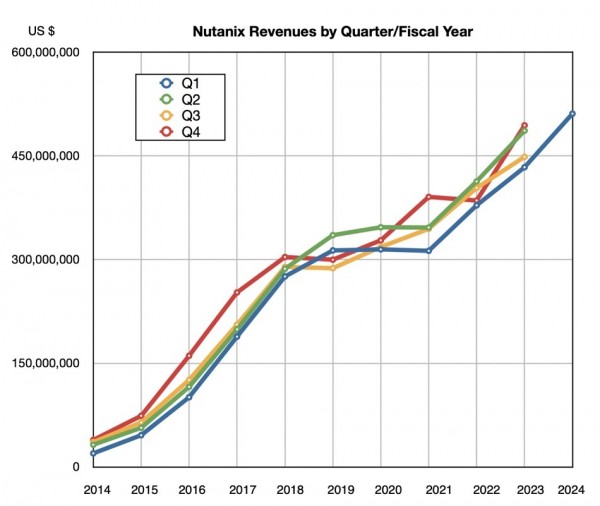
超融合基础设施软件提供商Nutanix宣布,其最近一个季度的营收创下历史新高、连续第八年保持增长,并首次达到20亿美元的年化收入水平。
截至10月31日的上季度,该公司收入为5.111亿美元,同比增长18%,亏损额为1590万美元,大幅低于去年同期的9910万美元亏损。新增客户380家,累计客户达到24930家。此外,Nutanix还启动了股票回购计划以提振其股价。
Nutanix公司总裁兼CEO Rajiv Ramaswami表示,“我们第一季度的业绩表现强劲,结果也超出了我们的预期。第一季度充满不确定性的宏观背景基本没有好转。”
公司CFO Rukmini Sivaraman也补充道,“2024年第一季度的表现相当不错,我们的所有指标都超出了预期上限。第一季度追加与扩展销售(ACV)额为2.87亿美元,高于2.6至2.7亿美元的预期区间,同比增长达24%。”
凭借件8月售出的GPT-in-a-box一体式系统,Nutanix在美国联邦政府业务方面的表现也强于预期。此外,Nutanix与思科的合作也迎来良好开端,思科已决定取消自家HyperFlex HCI产品,转而代售Nutanix方案。Ramaswami表示,Nutanix“在这款新产品上取得胜利,吸引到了那些原本打算购买思科HyperFlex的客户。”
但他在财报电话会议上也保持了谨慎的态度:“我们的渠道需要六到九个月时间才能完成交接。所以预计今年之内,由思科引流的客户可能不会太多。”
尽管宏观环境与上个季度相比无甚变化,但Sivaraman表示“与去年同期相比,我们发现平均销售周期略有延长。”
财务摘要
- 毛利率:84%,去年同期为81%。
- 自由现金流:1.325亿美元,去年同期为4580万美元。
- 运营现金流:1.455亿玩,去年同期为6550万美元。
- 现金与短期投资:15.7亿美元,去年同期为13.9亿美元。
Ramaswami希望“到2027财年,ARR复合年增长率能保持在20%左右,并在2027财年产生7到9亿美元的自由现金流。”
Nutanix 2024年第二财季的收入预期为5.5亿美元(上下浮动500万美元),年增长率预计为13.1%。目前全年预期营收为21.1亿美元(上下浮动1500万美元),比上年中位数增长13.3%。Sivaraman指出,“尽管宏观环境存在不确定性,但我们的解决方案仍然拥有新的扩展机会。”相应的,Nutanix已经上调了2024财年的所有预期指标,包括营收、ACV销售额、非GAAP营业利润率、非GAAP毛利率以及自由现金流等。
另一项利好消息,就是Red Hat OpenShift将运行在Nutanix之上。Ramaswami提到,Red Hat在应用业务层与VMware存在竞争关系,而Nutanix在基础设施层与VMware同样有所交集,所以Red Hat与Nutanix天然站在统一战线。部分Nutanix客户也在使用OpenShift,包括全球2000强银行。亚太地区的一家2000强银行就选择了Nutanix,希望借此避免VMware在加入博通后的业务不确定性。由此看来,Nutanix本季度的强劲业务表现也在一定程度上得益于这种不确定性。
但长远态势究竟是好是坏,目前还很难说。毕竟而且部分VMware客户也签署了长期协议,不得转投Nutanix的怀抱。
Ramaswami也在财报电话会议上提到了这一点,表示“在担忧情绪的推动下,我们获得了大量机会,能够与更多潜在客户接洽交流。但是,很难预测这种态势能不能长期保持下去。”
总体而言,VMware竞争力减弱与思科退出HCI市场给了Nutanix巨大的机会空间。只要能够妥善把握,相信Nutanix将在未来几个季度、甚至几年之内保持积极的业务增长幅度。
好文章,需要你的鼓励


人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
英特尔携手戴尔以及零克云,通过打造“工作站-AI PC-云端”的协同生态,大幅缩短AI部署流程,助力企业快速实现从想法验证到规模化落地。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
阿联酋阿布扎比人工智能大学发布全新PAN世界模型,超越传统大语言模型局限。该模型具备通用性、交互性和长期一致性,能深度理解几何和物理规律,通过"物理推理"学习真实世界材料行为。PAN采用生成潜在预测架构,可模拟数千个因果一致步骤,支持分支操作模拟多种可能未来。预计12月初公开发布,有望为机器人、自动驾驶等领域提供低成本合成数据生成。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2023
12/01
14:49
分享
点赞

人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
《2025 中国企业级 AI 实践调研分析年度报告》:深度剖析与价值洞察
Gartner:在中国构建AI软件工程技能的三大举措
阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
Anthropic披露首例Claude模型参与的AI网络间谍活动
Cadence首款系统芯粒架构成功流片,助力物理AI发展加速
百度发布定制AI加速器响应国产芯片需求
VasEdge试用火热招募,降本增效机遇来袭
Infinidat InfiniBox G4系列升级重塑高端企业存储格局
Avalonia为微软MAUI跨平台应用方案带来Linux和浏览器支持
谷歌DeepMind发布SIMA 2智能体:游戏世界中学习迈向AGI之路
