
打破存储性能瓶颈,实现AI应用的腾飞 原创
经典的“木桶理论”告诉我们,决定桶能装多少水,是由最低的那块木板来决定的。
同样目前数据在整个IT系统中的运行过程,也有一个瓶颈一直存在,就是存储介质的性能。
互联网催生了海量应用,海量应用诞生了海量的不同种类的数据。要让多元的数据发挥价值,不仅需要更强的处理器,更快的网络还有最终数据存储的读写能力。
今天算力发展喜人,多元的数据,催生着多元的算力的出现,通用算力CPU、人工智能算力GPU、TPU、NPU等处理器的蓬勃发展,X86、ARM架构等算力的架构发展。
网络技术发展喜人,移动互联、视频、直播等对于海量的数据传输需求,催生了数据中心的网络带宽100G、400G端口的发展。华为早在2018年正式发布全新400G光网络商用解决方案,支撑运营商全业务场景的400G网络快速部署。
同样存储技术在性能方面的发展并不喜人,海量的数据催生了存储技术的发展,介质上从磁盘到NAND、3D NAND的固态盘,接口从SAS、SATA、PCIE、NVME传输协议的升级。但是我们看到存储在单位容量增长的速度,远远大于单位存储传输性能的速度。数据在存储介质和外界交换的传输速度成为整个IT系统的瓶颈。
在积极突破存储瓶颈的方向上,目前提出有三种方法,一、直接采用全新的架构和技术重新定义存储技术。二、采用分布式存储,让数据分散传输来提升整个IT系统的效率。三、研发新的存储介质,包括原子存储技术和DNA存储技术。
研发新的架构和技术。在不久前的2021华为全球分析师大会,华为发布了迈向智能世界2030的九大技术挑战与研究方向,其中就有针对IT架构中最后的挑战,存储性能提升给出了方向,包括构建提升存储性能百倍的新存储技术研究方向。
华为希望从突破冯诺依曼架构来提升存储能力。目前的IT架构基于冯诺依曼架构,数据在CPU、内存、存储介质之间移动,其中任何一个环境的性能差,都会对整个系统带来性能挑战。
我们看到CPU的性能一直在提升,内存的性能也在提升,网络的带宽也在提升,存储的容量也在提升,但是存储的性能却一直是瓶颈,包括当前的PCIE、NVME等存储接口的带宽速度远跟不上外部网络的性能增长。
华为的思路是要提升存储性能,需要突破冯诺依曼架构的限制,从以CPU为中心,转向以内存为中心、以数据为中心,从搬移数据转向搬移计算,打破性能墙。
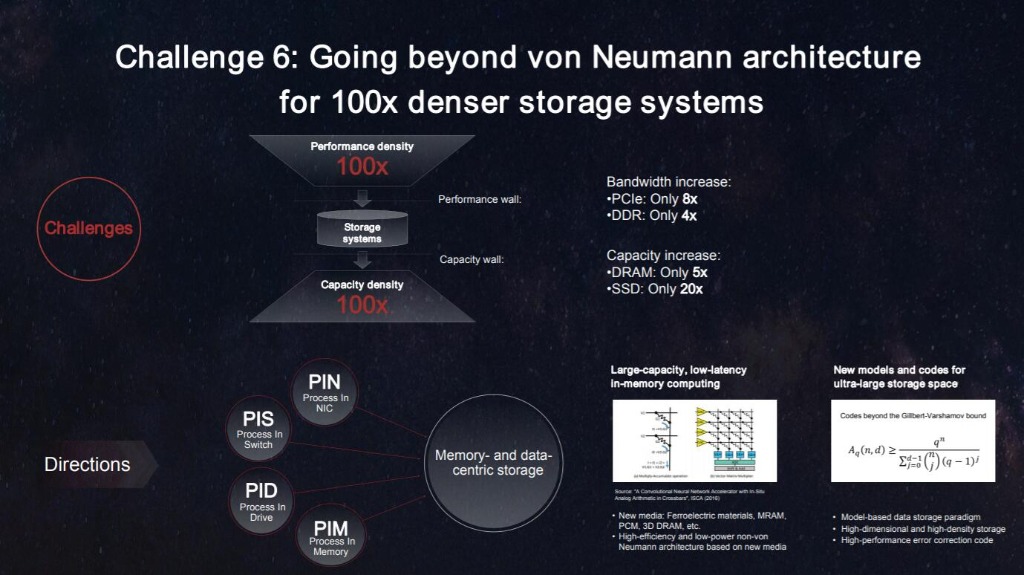
还有一种方案提高数据存取的效率,当面临海量数据存取的时候,用最少的存取,实现最大的应用。这就是是分布式存储。
比如现在火热的IPFS就是一种比较火热的分布式存储系统,其核心概念是基于内容寻址、版本化、点对点的超媒体传输协议。也就是数据存取直接指向资源,并确保这些数据都是来自最近的资源。而不是先找到存放的存储介质,在调取介质里的数据。这样就大大减少了存储介质性能对于数据存取的影响。比如一个10TB的文件,可以打散分布在1000个边缘端的存储介质上。而且调用的时候,不需要下载到本地,直接调用1000个边缘端的存储性能。从而实现数据的高效利用。
第三就是新的存储介质,包括原子存储技术和DNA存储技术,如果能够真正研发出来,就能够实现存储性能的千倍以上的提升,当然目前是理论阶段,距离真正落地商业还有还长的距离。
来源:至顶网存储频道
好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

当AI学徒“失控发疯“:中国科学院自动化研究所揭示强化学习崩溃真相,并找到了解决之道
本文介绍了中国科学院自动化所的研究,揭示了大型语言模型在多轮工具调用强化学习中崩溃的根本原因,并系统评估了五种监督信号对训练稳定性和泛化能力的影响。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津、MIT等顶尖机构联手揭露:当前最强AI智能体,在这些任务上表现堪比新手
牛津、MIT等机构联合发布GauntletBench,测试显示最强AI智能体完成率仅19%,而普通人类完成率超80%,揭示AI在时间感知、图形理解和三维推理上的真实短板。

