
打造数据存储的千里长堤,西部数据力推创新存储架构
一个厨师不研究菜谱改研究兵法了,这是因为上当受骗造成的,没有普遍意义。但是一个存储品牌的专业厂商开始研究存储架构又意味着什么呢?在这里,西部数据为我们给出了答案。
在2020中国数据与存储峰会上,西部数据公司副总裁兼中国区业务总经理刘钢的主题演讲的题目就是《创新存储架构,迎接数智未来》。刘钢指出:数据存储的应用场景正在经历从终端、边缘到云数据中心核心的快速演进,数据的特点是大数据、快数据的应用需求并存。
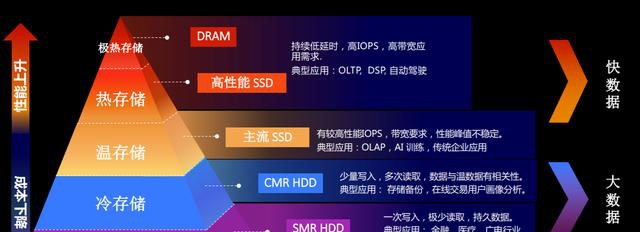
如何才能够满足两种不同应用状态的需求?从存储盘角度出发,并不存在一种单一产品可同时满足两种需求,而是需要通过闪存SSD、磁盘HDD分层存储,通过创新存储架构来满足需求。
在新的存储架构模型中,数据被分为了极热存储、热存储、温存储、冷存储和极冷存储共5种类型,根据数据类型的需求特点,它们又被分为快数据、大数据,其中快数据主要借助SSD盘提供支持,而通过CMR、SMR磁盘来满足大数据,也就是海量数据的存储需求。
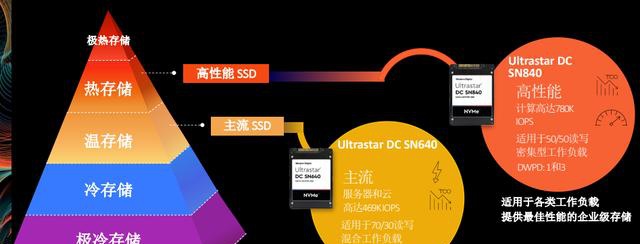
SSD盘在设计和技术被进一步细分,以西部数据Ultrastar DC NVMe固态硬盘为例,又进一步细分为SN640、SN840,其中,SN640适用于服务器和云,设计IOPS数值高达469K,适用于70%读30%写混合工作负载;相比SN840的IOPS为780K,适用于50%读50%写的工作负载,用于加速云计算以及关键业务应用的稳定运行。从SN640到 SN840,IOPS从469K到780K,表面差别并不大,但是在技术上,从NAND颗粒到控制器连接通道的数量,都有很大的差异。


<从左到右依次为:西部数据ultrastar dc="" sn640="" nvme="" ultrastar="" sn840="" ssd="">
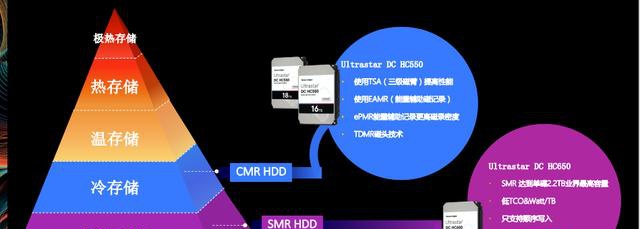
冷数据、极冷数据存储方面,西部数据建议采用16、18TB大容量CMR 磁盘和20TB SMR磁盘分别进行应对。

<从左到右依次为:西部数据ultrastar dc="" hc550="" hdd="" ultrastar="" hc650="" 20tb="">
需要看到,磁盘制造技术并没有减缓发展的步伐,也在不断升级换代种。其中氦密封(HelioSeal)、叠瓦式磁记录(SMR)和能量辅助磁记录(EAMR)是最值得关注和落地的技术,它们从不同的角度提升磁盘容量,追求TB/$成本最大化。
氦气密封硬盘,利用氦气密度是空气的1/7的特点,通过氦气填充降低功耗、抖动并增加磁碟密度;叠瓦式磁记录是通过在每个区域拼接更多的轨道,允许磁性位区域与相邻磁道重叠,从而像磁盘上的木瓦一样重叠,来提高磁盘表面的位密度;相比,能量辅助磁记录通过在写入磁头的主极施加电流并产生额外的磁场,达到减少干扰、降低写入抖动的目的。
技术手段不同,效果和局限也有所不同。更多时候,需要借助不同技术组合搭配来满足业务场景的需要。与此同时,需要兼顾到新技术的局限,扬长避短,最大程度发挥技术的潜能和效率。以叠瓦式磁记录为例,更倾向于按顺序生成(例如视频或传感器数据)的数据存储,非常适用于极冷数据存储。
都说生产力决定生产关系,经济基础决定上层建筑,作为存储最为基础的部件,存储盘的多样性,将决定存储系统的多样性,通过架构创新来满足数据存储多样性的需求。
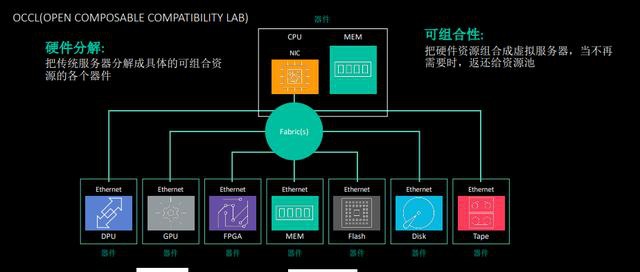
刘钢指出,未来存储系统发展将会呈现出一种开放可组合兼容的分解式架构,其中作为计算核心的服务器被分解为DPU、GPU、FPGA、Memory、Flash、Disk、Tape等器件于CPU内存的资源组合,这些资源可以全闪存阵列、混闪、磁带冷存储,通过虚拟化技术结合场景进行组合,需要的时候对外提供,不需要的时候返还给资源池,从而实现弹性伸缩的效果。这样一个特征与云的趋势完全吻合,通过云的形式对外交付。
从用户的角度来说,云服务屏蔽了底层技术复杂性,让用户可以专注业务创新。但是从云服务运营商的角度,通过不同技术组合,做大人尽其才,物尽其用才是其专业性的最佳体验。
对于行业云而言,私有云架构设计、运维管理都离不开对于从底层技术的细节的深刻把握,离开了这个前提,云服务的效率和优势将无法发挥。
而,其他的存储亦是如此。因此存储的问题很多时候还要回顾到最为本源,也就是存储盘这个环节,就像砖石、钢筋水泥一样,基础能力的地基,将会最终决定建筑的高度,因此应对快数据、大数据的挑战,还是需要从基础做起。千里之行始于足下,存储的脚步,要从存储盘开始。西部数据的创新存储架构势必会引起存储厂商和用户的高度关注!
来源:业界供稿
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2020
11/25
16:15
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
