
数据存储五大趋势:加速技术和数字主权时代到来 原创
在近日举办的Hitachi Vantara 2019中国论坛上,Hitachi Vantara在活动现场为参会者们展示了在NEXT 2019大会上最新推出的全球最快的Hitachi虚拟存储平台(Hitachi Virtual Storage Platform)VSP 5000。该产品能够提供每秒2100万IOPS,低至70微秒的时延以及高达8个9可用性。8个9是什么概念?就是说平均每年停机时间仅为0.3秒。保证了核心业务的业务连续性。
IDC中国副总裁兼首席分析师武连峰根据IDC数据分享了最新的存储发展趋势。为用户和企业发展和利用存储提供一个重要的参考。
数据存储趋势一:市场维持高速增长。2018年,基于各个存储厂商的销售额来看,中国存储市场规模达到了34.2亿美元。其中传统企业级存储19.7亿美元,占比60.9%,软件定义存储市场规模为7.2亿美元,占比22.1%。超融合存储占比17.0%。
IDC预测中国存储市场2018-2023年复合增长率10.3,其中软件定义和超融合存储增长率在20%以上。金融、电信、大型制造等对可靠性要求非常高的企业仍然偏好传统企业存储。
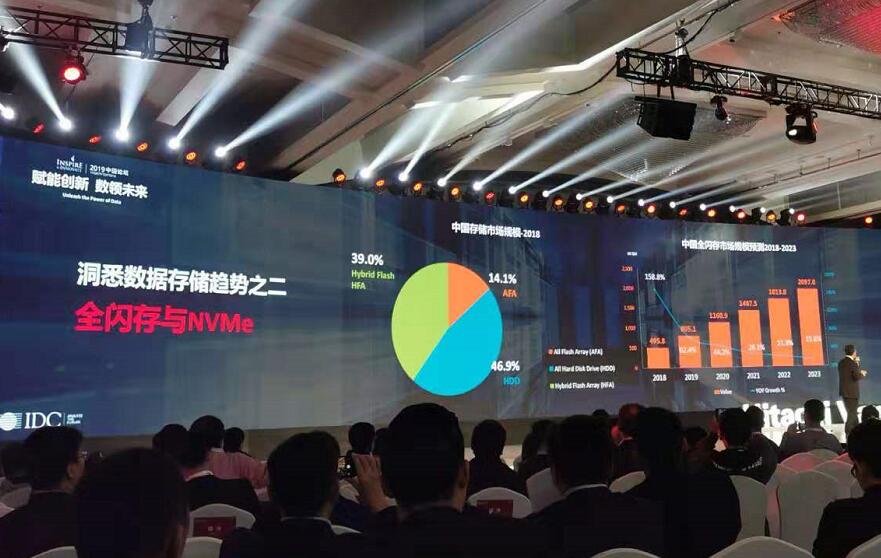
数据存储趋势二:全闪存与NVMe。2019年,目前主流存储设备厂商都已经进入市场,2019年全球NAFA超过20亿美元,到2021年全球NAFA将驱动50%的外部存储市场。其中2018年中国存储市场规模来看全闪存占比是14.1%。但是增长率很高。IDC预测2020年相比2019年增长率为44.2%,2021-2023年的复合复合增长也超过20%。
目前在全闪存上的创新领先厂商包括Hitachi Vantara、华为、和戴尔易安信。Hitachi VSP 5000能够提供每秒2100万IOPS,低至70微秒的时延以及高达8个9可用性。华为新一代oceanstor Dorado,是首款内置AI芯片的全闪存,提供2000万IOPS性能和0.1ms的稳定时延。
数据存储趋势三:多云环境的适应。多云管理成为存储上云考虑的问题。到2024年,70%的中国500强组织将实现跨公有和私有云的多云管理策略。
数据存储趋势四:人工智能融合。IDC2019年预测,到2023年,40%的企业的数据中心IT设施将利用嵌入式AI功能,拥有自主运转和控制的能力,到2021年,人工智能或自动化的分析驱动将取得50%的运维业务,节省20%以上的运营成本。人工智能将驱动设备的配置和修复的自动化,消除人为错误的手动过程并提高生产率。同时AI还能够通过提供IT综合效率、减少停机等实现运营成本的降低。

数据存储趋势五:安全与隐私匹配。IDC预测,到2022年,50%的IT基础架构平台将对静态和运行中的所有数据应用加密,这种加密需要是量子安全等新技术。到2020年,全球超过50%的跨国公司将实现云、IT基础架构和数据治理设置的安全和自动化,符合GDPR等法规需求。
数据存储的安全和隐私核心是数字主权的问题。华为任正非认为,“数字主权和过去物理主权同样重要,过去物理主权牵涉到地缘政治,信息化没有地缘,信息在全球流动,还是要有数字主权。每个国家都要建立自己数字主权的概念”华为坚决支持数字主权战略和诉求,为全球基础设施做出贡献。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。


清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2019
10/28
10:53
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
