
Nutanix走向企业云战略,让超融合带上隐形翅膀 原创
Nutanix中国用户大会北京站本周举办,Nutanix 创始人兼CEO Dheeraj Pandey公布公司的发展目标,到2021年实现软件产品及相关支持营收30亿美元。为实现这一目标,仅仅靠超融合概念已经远远满足不了市场扩张需求。
在中国用户大会上,Nutanix传达出来的意愿是让市场认知到Nutanix不仅仅是超融合厂商,还将以超融合为基础打造适合多云环境的企业云解决方案。而明显的是在不久前,Nutanix宣布收购Frame,这样Nutanix就能够为客户将提供多云环境下的桌面应用即服务(DaaS)。
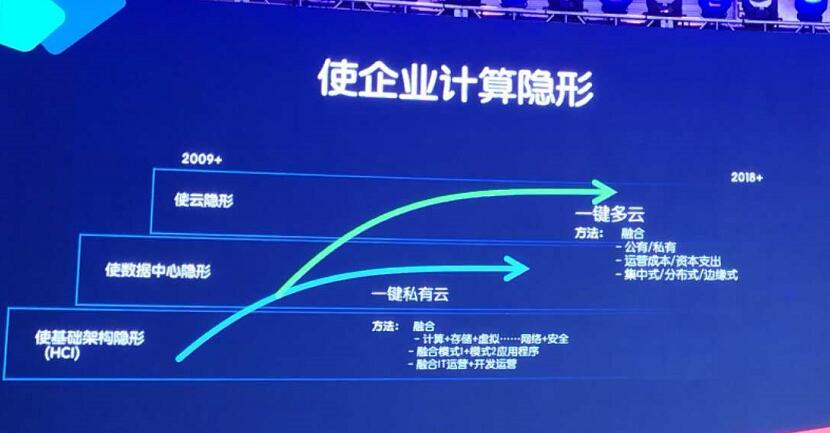
让企业计算隐形,让业务上云
从早期Nutanix希望让传统企业用上Google、AWS等互联网企业的数据中心架构理念,到现在为企业提供企业云服务。2018年Nutanix一直谈到概念是让企业计算隐形。“化繁为简,让计算隐形”成为Nutanix的发展方向,而通过超融合、分布式存储技术对基础架构和数据中心变革,能够实现运算隐形,从存储隐形到数据中心隐形再到云隐形,让复杂不可见。
在采访现场,Nutanix首席营收官Lou Attanasio谈到Nutanix服务转型,不是放弃硬件业务,而是根据用户的需求提供。
“我们所谓的从硬件向软件的改变,如果对我们客户而言,它有硬件的要求,我们仍然会向它销售硬件,对于软件这部分业务而言,我们是逐步地要采取订阅式,以及云的方式。所以,我们更核心的一个理念就是我们要提供给客户所要求的东西,他们究竟需要的是什么。”
Nutanix向云转型充满挑战和机遇
Lou Attanasio认为转型,需要整个团队对企业战略的理解以及为客户提供更好的完整的体验、
具体来讲:
第一让团队能理解Nutanix要提供的这种转变以及现在所提供的这些产品它究竟是什么,要赋能给销售团队和技术团队,让他们充分地理解我们赋能给他们的东西是什么。
第二点,关于科技方面的。要继续保持,能够让客户体验到他们过去之所以选择Nutanix作为一个硬件公司他们所体会到的特别喜欢的用户体验。要把他们非常认知和喜欢的用户体验继续延续到所提供的软件以及云的产品上面。
第三点,所提供的这些服务,包括云,我们一定要保证它是整合性的。“也就是说,无论它是在本地的,还是以云端呈现出来的,从用户的角度而言,它完全是属于一站式的,并且是可视化、简单易行的操作。也就是说,如果它是本地,无论是公有云,还是私有云,我们最终要在科技让它的操作是非常简易的。如果说想要在最终的客户端做到简单易行,我们在最终后台的程序端要做非常多的科技上的突破和努力,才可以做到客户端的简单易行。”Lou Attanasio分享到。
对中国市场增长要求高于全球
Nutanix 中国区总经理David Chan表示,中国在过去这一年的时间有着非常健康的增长。总部给我的要求就是比全球增长高。我们在不同地区都会加强投入,不管是从销售,对代理销售的覆盖、培训,还有我们的售后服务,因为售后服务是重中之重。
Lou Attanasio也表示出对于中国区的期待。他认为在中国市场,无论是从机会的角度,还是从营收的角度,在这里以后是蕴藏着巨大潜力的。因此Nutanix要做的是持续的在中国区雇佣更多的员工,更加密切地和业务合作伙伴一起工作,保持与最终的用户有着很好的关系。未来,我们期待我们的团队能够以全球每个季度50%的增长率继续保持增长。
同时对于包括在国内市场与联想等厂商的合作,Lou Attanasio表示,中国市场整体规模将超过100亿美元,在这样一个巨大的市场上有足够的空间容纳不只一个竞争者,Nutanix要在中国市场上继续发展自己的合作伙伴关系,此次中国行和联想已经见了面,今后和联想的合作要比现在还要更深入、大很多。同时,我们也继续和戴尔、惠普、Ctrix合作,因为我们可能会发展更多的卖方的合作伙伴。这是我们今后的一个战略。
“所以我们会建设一个大的生态,在这生态圈中,有时我们是合作伙伴,但同时我们也是竞争对手。”Lou Attanasio最后谈到。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。


清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2018
09/21
16:02
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
