
StorPool:基于纠删码技术实现防范更多存储设备和节点故障
StorPool Storage在其块存储软件的v21版本中添加了纠删码,这意味着其数据应该能够在更多设备和节点故障的情况下存活下来。
该存储平台表示,它增加了云管理集成的改进以及提高了数据效率。StorPool构建了一个基于标准服务器节点的多控制器、可扩展的块存储系统,可以运行应用程序和存储。它是可编程、灵活、集成和始终在线的。该公司声称,其纠删码实现在几乎不影响读/写性能的情况下,可以保护免受驱动器故障或损坏的影响。
StorPool首席执行官Boyan Ivanov告诉我们:“与人们普遍认为的相反,大多数供应商只在同一机箱中复制RAID,而不是在多个节点或机架之间进行纠删码。”
StorPool制作了下面的图表,从其角度研究了纠删码竞争格局:
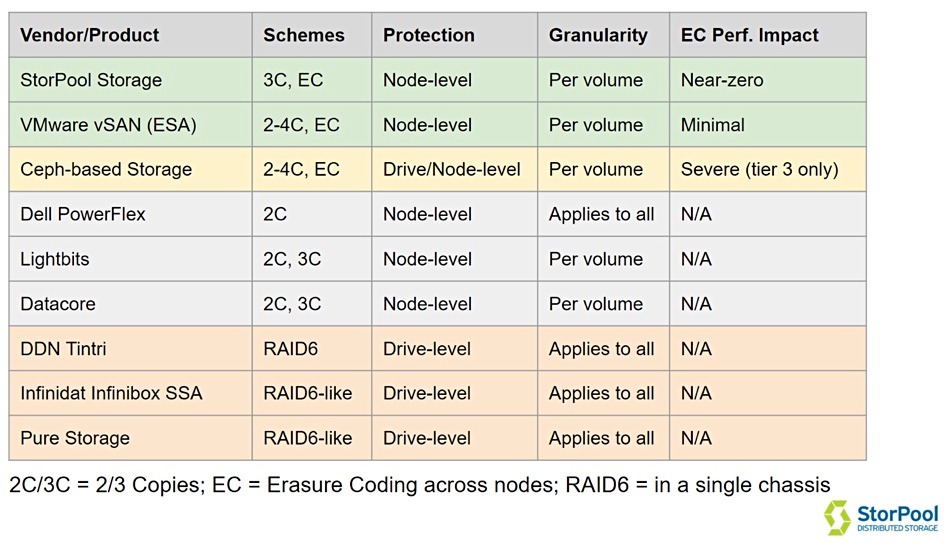
StorPool的纠删码需要至少五个以上的全NVMe服务器节点上才能提供四个功能:
跨节点数据保护—信息通过两个奇偶校验对象跨服务器进行保护,因此任何两个服务器都可能发生故障,数据保持安全和可访问性。
按卷策略管理--可以使用三重复制或擦除编码来保护卷,并在数据保护方案之间进行按卷实时转换。
延迟批处理编码–传入数据首先以三个副本写入,然后批量编码,大大减少数据处理开销,并最大限度地减少对用户I/O操作延迟的影响。
始终运行—在整个存储系统保持运行且所有数据都可用的情况下,最多可以重新启动或关闭两个存储节点进行维护。
现在,客户可以为每个工作负载选择更精细的数据保护方案,根据每个单独的用例调整数据占用空间。在大规模部署中,客户可以执行跨机架纠删码, 使其存储系统能够从数据效率的提高中受益,同时确保最多两个机架的故障存活。
v21版本还包括:
改进了iSCSI可扩展性:允许客户每个节点最多导出1000个iSCSI目标,特别适用于大规模部署。
CloudStack插件改进:支持CloudStack的卷加密和部分区域范围存储,从而实现计算主机之间的实时迁移。
OpenNebula附加组件改进:支持多集群部署,其中多个StorPool子集群表现为具有统一全局命名空间的单个大型主存储系统。
OpenStack Cinder驱动程序改进:支持StorPool存储集群的部署和管理,这些集群支持Canonical Charmed OpenStack和使用kolla ansible管理的OpenStack实例。
与Proxmox虚拟环境深度集成:通过集成,任何使用Proxmox VE的公司都可以从端到端自动化中受益。
额外的硬件和软件兼容性:增加了经过验证的硬件和操作系统的数量,从而使StorPool Storage更容易在客户的首选环境中部署。
该公司的StorPool VolumeCare备份和灾难恢复功能现在安装在群集中的每个管理节点上,以提高业务连续性。VolumeCare始终在每个管理节点中运行,只有在活动管理节点上的实例才会主动执行快照操作。
好文章,需要你的鼓励


据说算力高达1000 TOPS,华硕Ascent GX10深度评测——模型推理
AI硬件的竞争才刚刚开始,华硕Ascent GX10这样将专业级算力带入桌面级设备的尝试,或许正在改写个人AI开发的游戏规则。

北大学者带你拖拽3D物体,像玩拼图一样让虚拟世界动起来
北京大学团队开发的DragMesh系统通过简单拖拽操作实现3D物体的物理真实交互。该系统采用分工合作架构,结合语义理解、几何预测和动画生成三个模块,在保证运动精度的同时将计算开销降至现有方法的五分之一。系统支持实时交互,无需重新训练即可处理新物体,为虚拟现实和游戏开发提供了高效解决方案。


达尔豪斯大学团队重磅研究:为什么AI社会模拟需要从“沙盒游戏“升级为“开放世界“?
达尔豪斯大学研究团队系统性批判了当前AI多智能体模拟的静态框架局限,提出以"动态场景演化、智能体-环境共同演化、生成式智能体架构"为核心的开放式模拟范式。该研究突破传统任务导向模式,强调AI智能体应具备自主探索、社会学习和环境重塑能力,为政策制定、教育创新和社会治理提供前所未有的模拟工具。
2023
10/19
09:47
分享
点赞

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——模型推理
上交联手阿里团队打造"AI记忆管家"ReMe,像人类一样从经验中学习
意大利航空携手ESA部署卫星通信技术提升飞行效率
苹果TV急需PoE支持以释放企业应用潜力
Google Translate为所有耳机带来实时语音翻译功能
生成式AI在心理健康咨询中的时间规律与人类使用习惯分析
回顾我们的2025年AI预测:准确性如何?
ServiceNow斥资10亿美元收购Veza 加速智能体权限管理
除英伟达和台积电外,其他AI公司都需要靠量补利
2025年数据中心芯片领域最热门发展趋势
自动化技术领导者揭示企业对AI认知的关键误区
五分之三企业对Wi-Fi投资信心增强
