
EDS存储摘两金,创新架构突破小文件性能瓶颈
近日,由百易传媒(DOIT)主办的“2022数据与存储峰会”在北京顺利举行,本次大会以“数据觉醒新时代”为主题,旨在探讨新时代数据存储的新方向和对优秀企业进行表彰,信服云企业级存储EDS凭借其优越性能,接连斩获“2022年度分布式存储金奖”“2022年度文件存储金奖”两项大奖。
信服云EDS为何能在这次峰会上连续获得两项大奖?在深信服存储解决方案总监王志成“存储如何应对GPU算力爆炸增长下的小文件性能挑战”主题演讲中我们或许能知道答案。
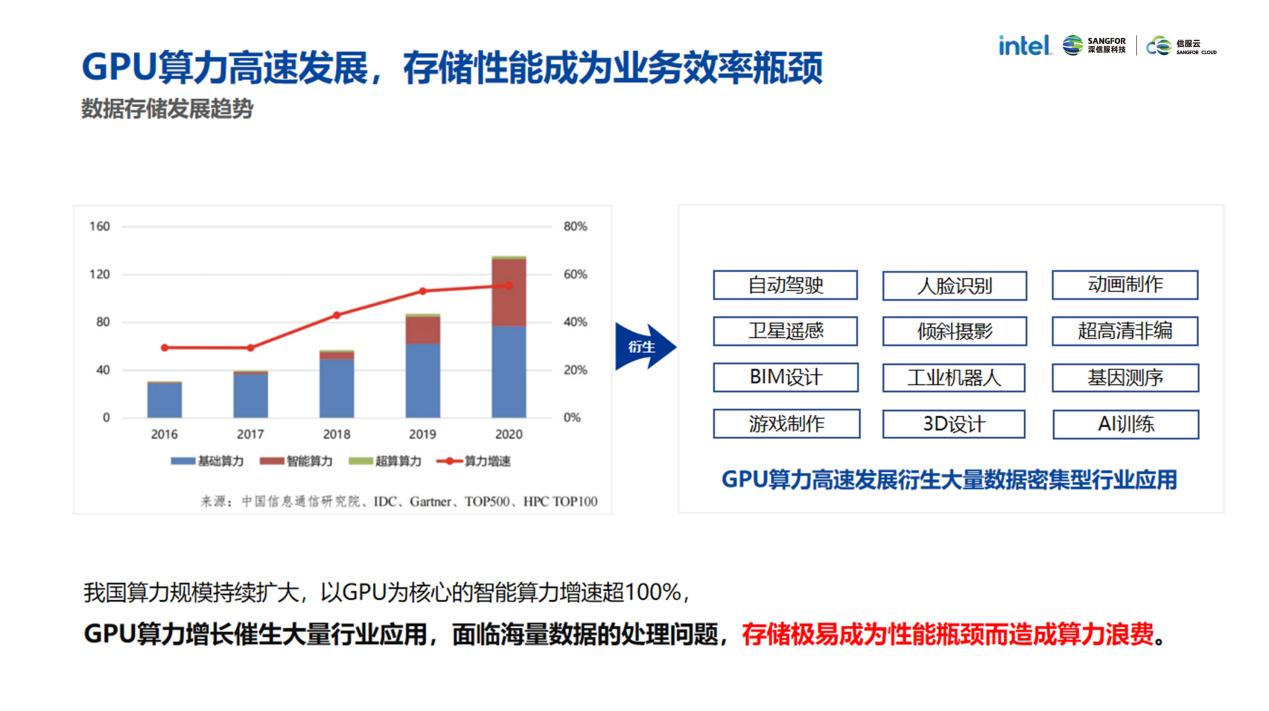
01 GPU算力爆发式增长下,存储面临哪些挑战?
王志成指出,以GPU为核心的智能算力比重由2016年的3%提升至2020年的41%,GPU算力高速发展衍生出大量数据密集性行业应用,这些应用数据的存储面临三大挑战:
存储架构受限,小文件处理性能差
很多业务生产过程都会产生海量KB级小文件,比如芯片设计的前端设计场景,实景三维建模场景等,但无论是传统NAS存储还是新兴的分布式存储,由于元数据处理架构、网络时延等限制,都难以有效解决小文件处理性能差的问题上。
数据量井喷,“存不下”成为主要挑战
以基因测序为例,受当下环境和人口老龄化的影响,一个基因测序服务企业每年新增的数据量就高达10PB级。传统存储跟不上现有业务的数据增长,想要扩展却要面临硬件与厂商绑定、成本高昂、扩展周期长等一系列问题。
各场景数据复杂,存储效率提高难
行业业务需求正在呈现多样化的演进趋势,对数据存储的大带宽支持能力、海量小文件访问延时和复杂场景的适应性都提出极高的要求,存储需要更高效的数据访问能力。
“在当下的环境,用户需要一套性能更高、扩展性更强的企业级存储系统,来提升业务数据生产效率。”王志成这样说到。
02 信服云分布式存储EDS,更高性能突破瓶颈
王志成引用Gartner报告中“软件定义是存储唯一变革性技术”的观点,点明未来存储的发展之道。相比传统存储,以软件形式定义存储可提供更优秀的场景适应能力、更高的性价比和更灵活的扩容能力,在软件定义的基础上,信服云EDS通过全自研高性能文件系统PhxDFS和五大核心技术提升存储综合能力:
多活元数据服务,性能再提升
为了解决性能不足的问题,EDS将一个完整目录分片后分发到各个存储节点处理,充分利用起所有节点的CPU算力,从而突破元数据性能瓶颈。对比Ceph架构的分布式存储,元数据处理能力可提升三倍以上。
元数据高效压缩算法,数据“存得下”
在海量小文件场景下,元数据的规模可能达TB级,为了将更多的元数据缓存到有限的存储内存空间,EDS自研元数据压缩算法,该技术最大可支持7:1的压缩比。在百亿小文件场景下实现元数据、热数据百分百命中内存缓存,让数据“存得下”“找得快”。
数据三级缓存机制,数据访问更快一步
EDS追求高性能的同时,同样注重数据读取效率。在专有客户端模式下,EDS将客户端内存、存储节点内存和大容量NVMe固态盘构建成三级缓存,实现数据和元数据就近访问,命中即返回,该技术将热数据的访问时延降低到us级别。相比过去,数据访问更快、效率更高。
高性能RDMA网络,网络时延再降低
EDS在存储业务网和存储私网均支持以RoCE v2协议替代TCP/IP协议,可将网络时延降低90%以上,业务联通仅需9-16us,可大幅缩短业务数据的联通时间。
数据智能聚合追加写,效率再提升
EDS将文件IO在高性能层(NVMe或SATA SSD)聚合后追加写入容量层(机械盘),可有效解决小文件写放大造成的容量浪费,利用机械盘本身顺序写性能优势,进一步降低EC写惩罚影响,提升写性能的同时可有效提升60%以上的回刷速度,进一步减少数据存储、调用的耗时,提高业务效率。
信服云企业级存储EDS保护数据也敬畏数据。在不断的技术创新中积极实践,现已累计参与交付超过20000个客户和300+例的PB级项目。在未来,EDS将持续打磨产品,与用户携手共创高性能存储时代的数据宏图。
来源:业界供稿
好文章,需要你的鼓励



Queen‘s大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。

医疗AI的“显微镜革命“:西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。
2022
11/17
16:00
分享
点赞

业界首款符合AEC-Q200标准额定电压高达1,000 VDC高压保险丝
数据中心的智算挑战,英特尔要如何应对?
下一代智能工厂怎么建?开放自动化给出“解题思路”
跟随西门子,在工博会感受沉浸式的工业AI体验
苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
OpenAI将发布类似TikTok的社交应用,搭配Sora 2视频模型
微软推出Office智能体模式让用户"氛围办公"
AI助手现在能帮你创建高质量Word文档和Excel表格
高通新一代骁龙平台将推动智能体AI时代到来
SAPx阿里云,开启一条通往中国市场与全球化发展的全新路径
微软推出"氛围工作"模式,为Office套件加入AI智能体
OpenAI推出智能购物系统挑战谷歌亚马逊
