
澎湃算力 智见未来 | 万国数据 2024 AIDC Tech Day 成功举办!
6月18日,以“澎湃算力,智见未来”为主题,万国数据联合中国IDC圈共同主办的“中国智算生态发展大会—— 2024 AIDC Tech Day”活动,在深圳成功举办。活动汇聚中国信通院、清华大学的专家学者,中金公司、零一万物等领军企业代表,围绕智算产业机遇挑战、生态协作、技术创新、能源优化等话题,共论产业发展之道。

在开场致辞中,万国数据董事长兼首席执行官黄伟表示:“AI重塑各行各业所产生的影响,将超越任何一次工业革命对人类未来命运的改变。全球范围需求正不断向头部企业集中,数据中心向着规模更大、交付更快、距离核心城市及充足低价能源供应更近的部署趋势愈发显著。”
 万国数据董事长兼首席执行官黄伟
万国数据董事长兼首席执行官黄伟
黄伟提出:“万国数据通过推动国内国际‘双引擎’战略,在国内及海外形成了覆盖核心经济枢纽、满足低中延时及靠近能源供应的完善布局,逐步从亚洲迈向全球。同时我们也在围绕更大规模的资源能力、更快速度的交付能力、更强大的运营管理能力、更绿色的能源使用能力、更前瞻性的产品能力不断锐化自身核心竞争力,全面满足AI时代的广泛需求。”
中国信通院:算力互联
解决“找、调、用”三大痛点
 中国信通院云大所副所长栗蔚
中国信通院云大所副所长栗蔚
随着AI大模型参数呈指数级增长,我国对智能算力的需求将不断增加。活动上,中国信息通信研究院云计算与大数据研究所副所长栗蔚,发表了《智算和互联网融合发展趋势》演讲:“目前我国算力存在‘找、调、用’三大痛点,算力互联变得极其重要。各方需要积极联动,以建立算力互联互通标准体系为基础,通过规范算力标识,升级调度系统和算力网络,持续强化软硬统一适配来应对挑战,加速算力普惠发展。”
中金公司:关注竞争要素
把握AIGC时代机遇
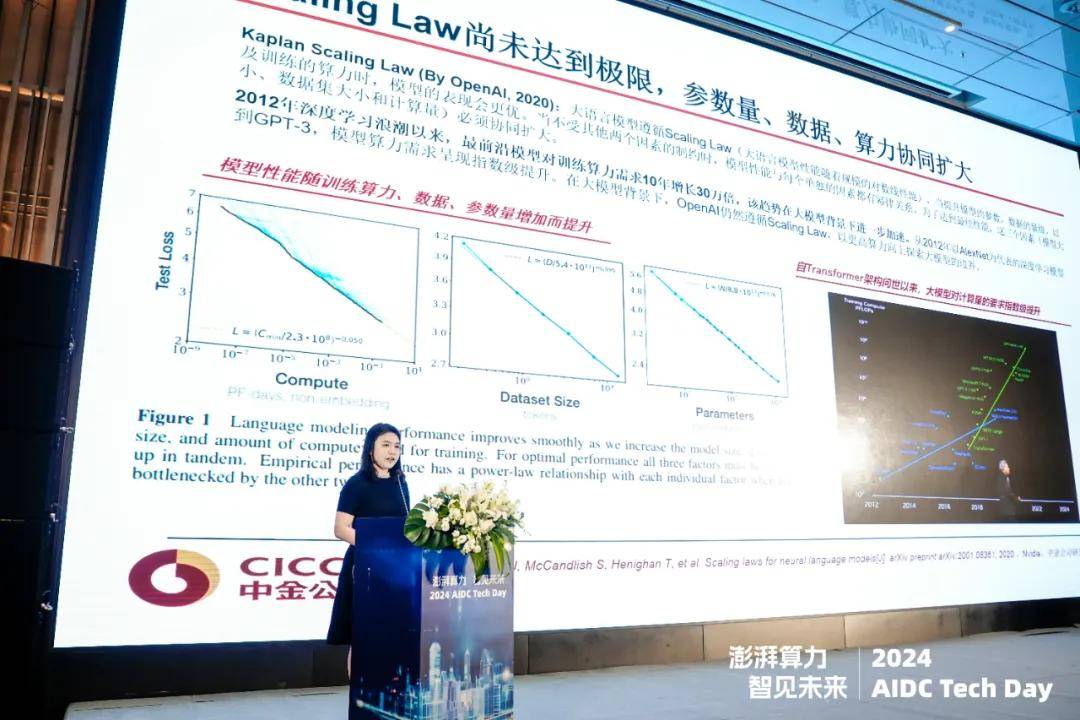 中金公司研究部执行总经理赵丽萍
中金公司研究部执行总经理赵丽萍
全球范围内,生成式AI的持续火热让智能算力的供需缺口越来越大。中金公司研究部执行总经理赵丽萍在《AIGC时代的中国智算产业发展趋势与机遇》演讲中谈到:“大模型已成为实现通用AI的重要方向,算力基础设施随之显现功率提升、制冷方式转变、选址靠近能源中心、更大电力需求等趋势。企业需要关注扩张规模和节奏、核心区位资源、电力成本及差异化服务等竞争要素进行布局优化,以把握AIGC时代机遇。”
零一万物:三位一体提升大模型能力
推进AI普惠
 零一万物联合创始人祁瑞峰
零一万物联合创始人祁瑞峰
大模型迭代速度与日俱增,推动AI 2.0 大模型时代有望成为迈向AGI最伟大的平台革命。零一万物联合创始人祁瑞峰在以《AI 2.0 平台级变革进行式》为主题的演讲中表示:“中国大模型赛道从狂奔到长跑,取决于有效实现 TC-PMF(技术成本-产品市场契合度)。零一万物如今正以模基共建、软硬一体、模应一体、AI-First等理念为核心,持续强化自身竞争力,并已成功跻身全球第一梯队,为推进AI普惠贡献力量。”
万国数据:洞察全球趋势
强化智算中心建设运营能力
 万国数据解决方案副总裁滕峰
万国数据解决方案副总裁滕峰
AI的巨大需求在全球范围激发了智算中心建设热潮。万国数据解决方案副总裁滕峰在以《全球视野下的智算中心建设》为主题的演讲中表示:“通用算力中心正向智能算力中心快速升级,超大规模、超高密度、风液融合、以能源为中心及绿色低碳成为重要特点及未来发展趋势。万国数据近年来积极探索AI智算中心的设计与运营,不断迭代容量设计、集群规模、业务网络、空间布局、风液配比、绿色运营并积累大量经验,强化了AIDC从前期规划到最终交付的整体能力。”
清华大学:校企共研AI算法
驱动暖通系统极致能效
 清华大学智能产业研究院 助理研究员詹仙园博士
清华大学智能产业研究院 助理研究员詹仙园博士
能耗始终是IDC行业的核心议题之一。清华大学智能产业研究院(AIR)助理研究员詹仙园博士,在现场分享了《数据驱动AI方法在数据中心优化问题中的应用与实践》:“数据中心能耗优化存在诸多技术挑战。目前,我们正与万国数据合作开发针对暖通系统控制的AI算法,经过实测,与传统PID方法相比(控制4台空调),已达最多降低18%的ACLF (空调耗电量/服务器耗电量) ,后续随着进一步优化,有望达成更佳的效果。”
圆桌对话:智算产业未来展望
在以“智算产业未来展望”为主题的圆桌对话中,零一万物联合创始人祁瑞峰、清华大学智能产业研究院(AIR)助理研究员詹仙园博士、万国数据高级副总裁张克兢分别从产业链不同视角,发表自己对于AI及智算产业当下困境与未来发展的观点,并对中国智算产业发展需要更加完善健全生态的支持这一方向达成了共识。

独行快,众行远,面向AI时代,万国数据将持续完善自身能力,巩固行业领先地位,并期待与更多合作伙伴携手,共同构建更加完善的生态,把握潜力无限的智算行业。
来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
06/20
14:52
分享
点赞

NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
蝉联第一!万国数据强势领跑“中国算力中心服务商十强”榜单
澎湃算力 智见未来 | 万国数据 2024 AIDC Tech Day 成功举办!
连续三年上榜!万国数据浦江数据中心获选2023年度国家绿色数据中心
万国数据发布2024年第一季度财报——国内新增使用面积创三年新高,国际业务布局再提速
万国数据进军日本东京市场,开启东北亚业务布局
获5.87亿美元股权融资,万国数据国际业务独立运营开启新篇章
万国数据发布2023年第四季度及全年财报——年净收入超99亿元人民币,国际业务将实现独立运营
万国数据发布2022年度ESG报告,可再生能源使用比例提升至35.9%
万国数据发布2023年第三季度财报——再获两笔超大规模订单,净新增签约面积超16,000平方米
万国数据发布2023年第二季度财报——新获三笔超大规模订单,上半年新增签约及预签约总面积近28,000平方米
