
华为应用市场:创造纯净安全环境 守护用户隐私安全
如今隐私安全问题正在受到广泛关注,解决用户的隐私安全问题刻不容缓。为保障用户的信息安全与个人隐私,国家监管部门已出台各种政策与规定,华为公司也明确将网络安全和隐私保护作为公司的最高纲领。3月22日,华为应用市场2023年度安全隐私报告发布,华为应用市场在应用管控和安全保障方面不断提升,为开发者创造纯净安全环境,让更多好的应用被看见,为用户加强安全保障机制,守护好用户的隐私安全。

一款应用在上架前、下载前、使用中都会产生隐私安全风险,无一不在挑战用户识别和规避风险的能力,鱼龙混杂的各种权限获取,恶意诱导,导致用户无法真正享受一款应用带来的优质体验,甚至也很难让很多真正优秀的应用被用户看到。此刻一个能够识别所有隐私风险的安全守护“卫士”十分必要。
应用管控三道关卡 全生命周期监管应用风险问题
面对全球海量应用上架申请,华为应用市场在应用管控方面不断完善审核规则,优化审核检测体系,所有应用都要经过上架审核、使用期间的定期复测以及全民监督反馈在内的全生命周期的安全管控体系。作为用户可信赖的安全守护“卫士”,它能够精确识别并排除潜在的安全威胁,确保在架应用的安全、可靠。
以一款广告违规应用为例,应用上架时合规,但在成功上架后,应用通过云端控制更新,开始进行广告宣传“成语玩的好,红包天天拿”,华为应用市场通过复检发现,下载广告内的应用后,仅为正常答题类应用,无领红包、提现等功能,与其广告宣传内容不符,遂对该应用予以下架处理。除此之外,华为应用市场提倡用户进行全民监督,欢迎用户积极反馈问题。2023年期间,华为应用市场经用户反馈渠道累计复测应用1.5万余款次。

完善双项安全保障能力 双屏障杜绝风险优化用户使用体验
对应用管控的同时,用户下载使用过程中的安全守护也毫不松懈。2023年,华为应用市场迭代了安装保护、运行保护两方面安全保障能力。部分被华为应用市场上架审核 “拒之门外”“的应用,常常以另外一种用户不易识别的方式出现。针对这一风险,2023年,华为应用市场新增了恶意应用渠道提醒和违法违规类应用提醒,未知来源的应用在安装环节,就会被华为应用市场检测并识别风险及时告警,保障用户安装应用的安全。同时,用户可以开启纯净模式增强防护功能,开启后,仅支持安装经过华为应用市场检测的应用,已安装但检测出存在风险的应用也将无法运行。
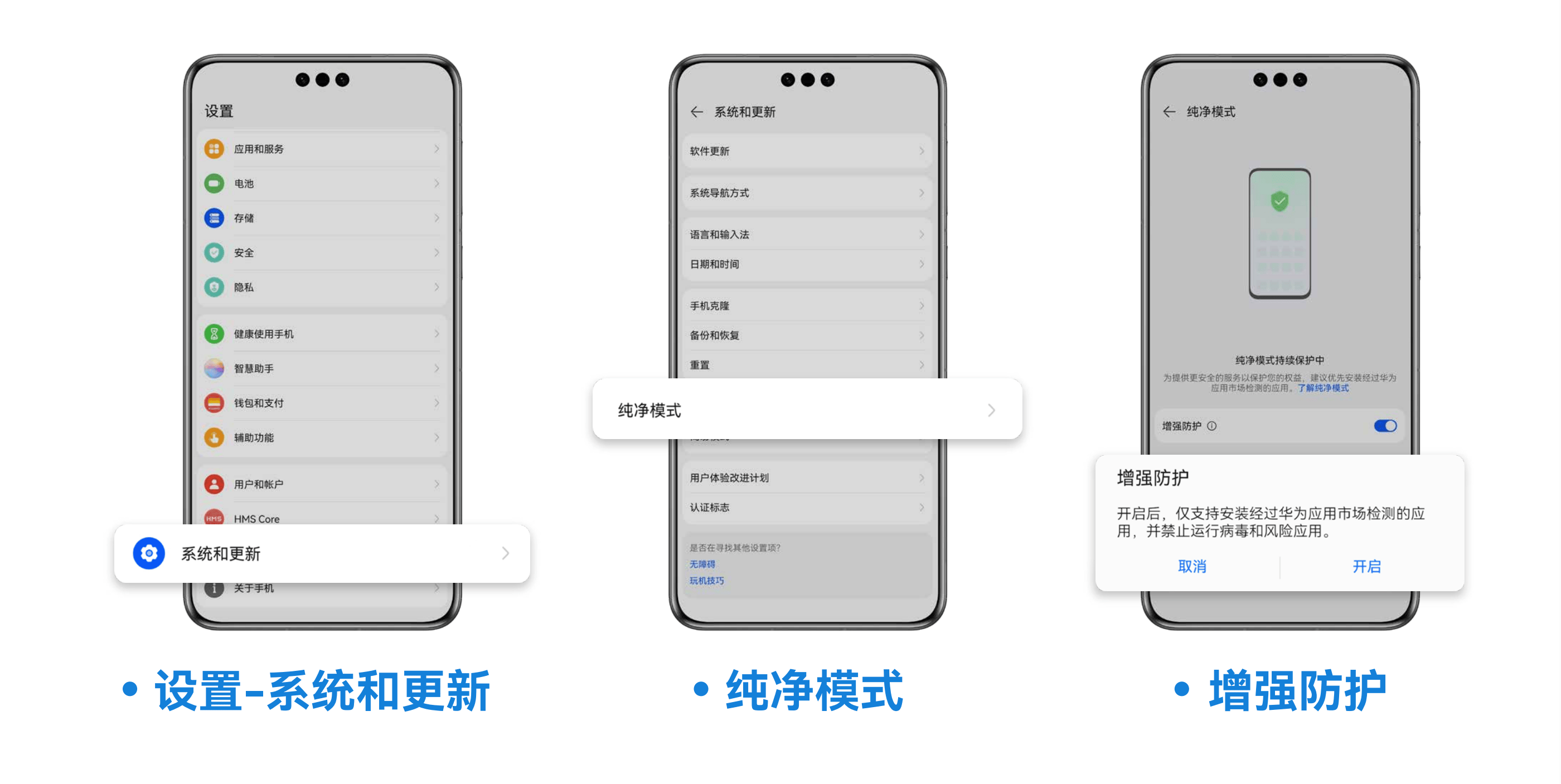
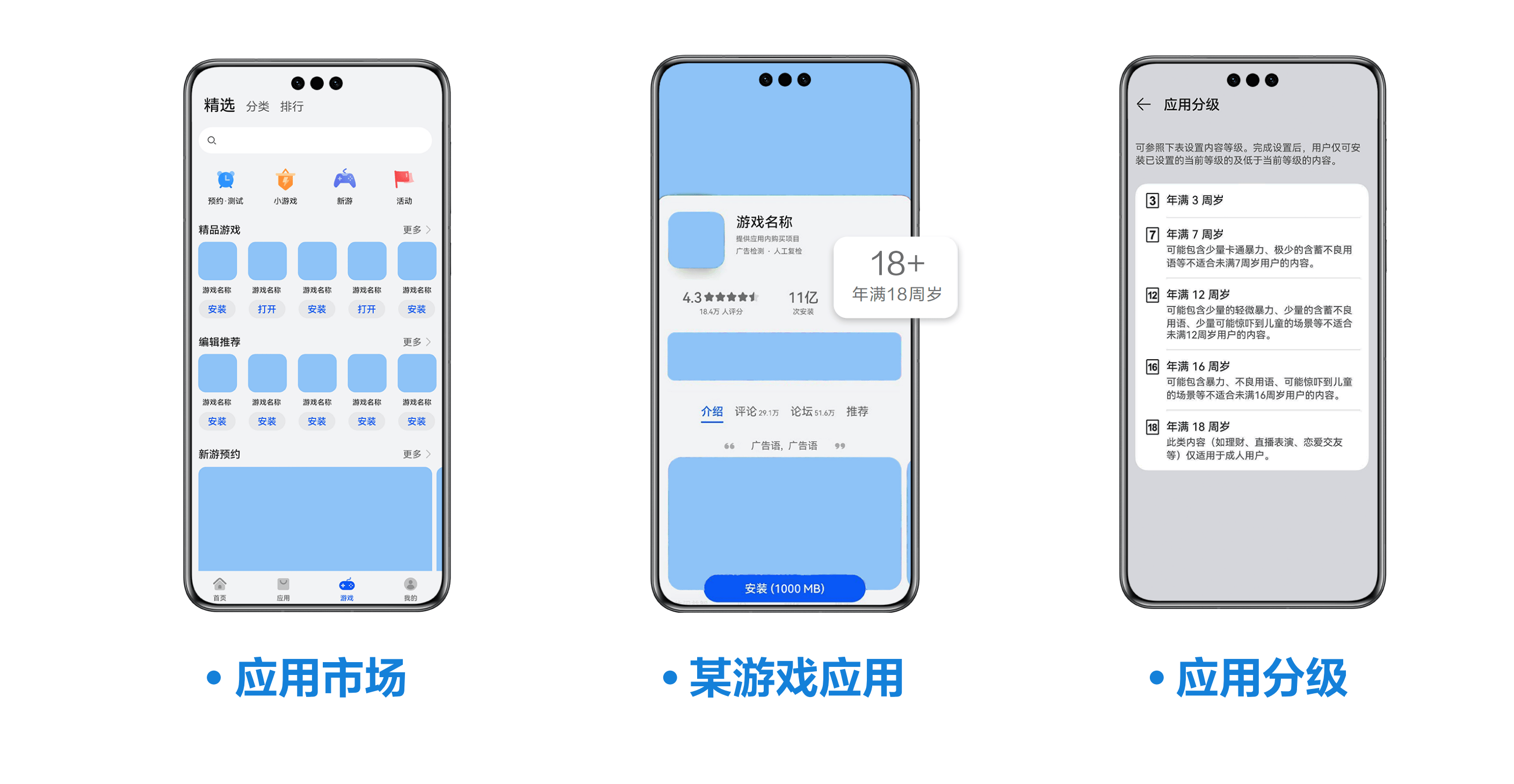
对于缺少风险辨别能力的未成年人,华为应用市场也有相应的应用年龄分级内容的管理,2023年,年龄分级能力再次优化提升,根据不同年龄阶段未成年人的身心发展特点和认知能力,对游戏应用进行精细分级管理。用户打开游戏详情页面,即可查看游戏适龄年龄,点击适龄年龄提示,查看年龄分级说明页面,选择适合未成年人的下载使用的应用,帮助家长管理管控好未成年人身心健康。
2023年,华为应用市场的卓越表现获得了广泛认可,被中央网信办评选为“年度清朗系列专项行动成效突出平台”,获得工业和信息化部授予“全国用户满意电信服务明星班组”。这些成就肯定了华为应用市场在安全和隐私保护方面的努力,和为用户和开发者创造了一个更加安全、更加纯净的数字生态环境。通过不断的创新和改进,华为应用市场正以实际行动守护着每一个用户的数字生活,为开发者提供一个公平、透明、安全的平台。开发者和用户可以放心地探索、分享和享受数字技术带来的无限可能。
来源:业界供稿
好文章,需要你的鼓励



北大学者带你拖拽3D物体,像玩拼图一样让虚拟世界动起来
北京大学团队开发的DragMesh系统通过简单拖拽操作实现3D物体的物理真实交互。该系统采用分工合作架构,结合语义理解、几何预测和动画生成三个模块,在保证运动精度的同时将计算开销降至现有方法的五分之一。系统支持实时交互,无需重新训练即可处理新物体,为虚拟现实和游戏开发提供了高效解决方案。

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——模型推理
AI硬件的竞争才刚刚开始,华硕Ascent GX10这样将专业级算力带入桌面级设备的尝试,或许正在改写个人AI开发的游戏规则。

达尔豪斯大学团队重磅研究:为什么AI社会模拟需要从“沙盒游戏“升级为“开放世界“?
达尔豪斯大学研究团队系统性批判了当前AI多智能体模拟的静态框架局限,提出以"动态场景演化、智能体-环境共同演化、生成式智能体架构"为核心的开放式模拟范式。该研究突破传统任务导向模式,强调AI智能体应具备自主探索、社会学习和环境重塑能力,为政策制定、教育创新和社会治理提供前所未有的模拟工具。
2024
03/25
13:28
分享
点赞

据说算力高达1000 TOPS,华硕Ascent GX10深度评测——模型推理
上交联手阿里团队打造"AI记忆管家"ReMe,像人类一样从经验中学习
意大利航空携手ESA部署卫星通信技术提升飞行效率
苹果TV急需PoE支持以释放企业应用潜力
Google Translate为所有耳机带来实时语音翻译功能
生成式AI在心理健康咨询中的时间规律与人类使用习惯分析
回顾我们的2025年AI预测:准确性如何?
ServiceNow斥资10亿美元收购Veza 加速智能体权限管理
除英伟达和台积电外,其他AI公司都需要靠量补利
2025年数据中心芯片领域最热门发展趋势
自动化技术领导者揭示企业对AI认知的关键误区
五分之三企业对Wi-Fi投资信心增强
