
StorPool:基于纠删码技术实现防范更多存储设备和节点故障
StorPool Storage在其块存储软件的v21版本中添加了纠删码,这意味着其数据应该能够在更多设备和节点故障的情况下存活下来。
该存储平台表示,它增加了云管理集成的改进以及提高了数据效率。StorPool构建了一个基于标准服务器节点的多控制器、可扩展的块存储系统,可以运行应用程序和存储。它是可编程、灵活、集成和始终在线的。该公司声称,其纠删码实现在几乎不影响读/写性能的情况下,可以保护免受驱动器故障或损坏的影响。
StorPool首席执行官Boyan Ivanov告诉我们:“与人们普遍认为的相反,大多数供应商只在同一机箱中复制RAID,而不是在多个节点或机架之间进行纠删码。”
StorPool制作了下面的图表,从其角度研究了纠删码竞争格局:
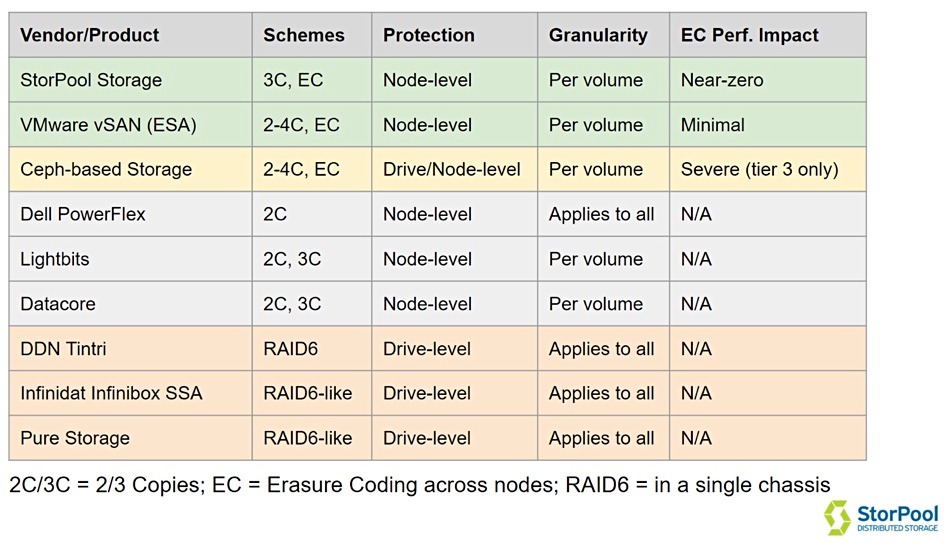
StorPool的纠删码需要至少五个以上的全NVMe服务器节点上才能提供四个功能:
跨节点数据保护—信息通过两个奇偶校验对象跨服务器进行保护,因此任何两个服务器都可能发生故障,数据保持安全和可访问性。
按卷策略管理--可以使用三重复制或擦除编码来保护卷,并在数据保护方案之间进行按卷实时转换。
延迟批处理编码–传入数据首先以三个副本写入,然后批量编码,大大减少数据处理开销,并最大限度地减少对用户I/O操作延迟的影响。
始终运行—在整个存储系统保持运行且所有数据都可用的情况下,最多可以重新启动或关闭两个存储节点进行维护。
现在,客户可以为每个工作负载选择更精细的数据保护方案,根据每个单独的用例调整数据占用空间。在大规模部署中,客户可以执行跨机架纠删码, 使其存储系统能够从数据效率的提高中受益,同时确保最多两个机架的故障存活。
v21版本还包括:
改进了iSCSI可扩展性:允许客户每个节点最多导出1000个iSCSI目标,特别适用于大规模部署。
CloudStack插件改进:支持CloudStack的卷加密和部分区域范围存储,从而实现计算主机之间的实时迁移。
OpenNebula附加组件改进:支持多集群部署,其中多个StorPool子集群表现为具有统一全局命名空间的单个大型主存储系统。
OpenStack Cinder驱动程序改进:支持StorPool存储集群的部署和管理,这些集群支持Canonical Charmed OpenStack和使用kolla ansible管理的OpenStack实例。
与Proxmox虚拟环境深度集成:通过集成,任何使用Proxmox VE的公司都可以从端到端自动化中受益。
额外的硬件和软件兼容性:增加了经过验证的硬件和操作系统的数量,从而使StorPool Storage更容易在客户的首选环境中部署。
该公司的StorPool VolumeCare备份和灾难恢复功能现在安装在群集中的每个管理节点上,以提高业务连续性。VolumeCare始终在每个管理节点中运行,只有在活动管理节点上的实例才会主动执行快照操作。
好文章,需要你的鼓励


雷克萨斯LFA电动超跑2027年量产,将搭载固态电池
丰田旗下豪华品牌雷克萨斯正以纯电动版本复活经典跑车LFA。新车已在古德伍德速度节亮相,预计2027年量产,将采用丰田期待已久的固态电池技术。该技术承诺更高能量密度与更快充电速度,但丰田已多次推迟相关计划。新款LFA搭载电动动力系统,内饰配备Yoke方向盘与沉浸式数字座舱,车身尺寸与阿斯顿马丁DB12相近。面对比亚迪腾势Z等1500马力级竞品,雷克萨斯能否追上电动超跑赛道,值得关注。

慧眼难辨“何时何处“——慕课里AI通才的专业盲区,庆应义塾大学新出的这套考卷让15个顶级模型集体翻车
庆应义塾大学与英伟达推出AnyGroundBench,测试15个顶级视觉语言模型在手术、工业等五大专业领域的时空定位能力,揭示当前AI在专业场景下的系统性空间定位瓶颈。

科学家研究证明:我们并非生活在模拟现实中
加拿大不列颠哥伦比亚大学奥卡纳根分校的研究人员通过数学方法,对"模拟现实"理论给出了否定答案。研究人员米尔·法扎尔在《物理全息应用期刊》上指出,基于不完备性与不可判定性数学定理,现实无法仅通过计算来完整描述,它需要非算法性的理解,而这超出了算法计算的范畴,因此无法被模拟。尽管如此,"模拟宇宙"的观念短期内仍难以从公众讨论中消失。

清华大学与蚂蚁集团联合打造“数据科学AI考官“:AgenticDataBench如何给数据智能体打出一张精准成绩单?
清华大学与蚂蚁集团联合推出AgenticDataBench,含344道真实数据科学任务和433个精细技能标签,系统评测12种主流数据智能体配置的能力边界与短板。
2023
10/19
09:47
分享
点赞

科学家研究证明:我们并非生活在模拟现实中
苹果与博通签署高达300亿美元芯片采购协议
零信任网络访问如何从根本上消除隐性信任
Crusoe扩展AI平台:推出无服务器微调与自助推理部署
Oratomic完成3亿美元融资,仅需2万个量子比特造出实用量子计算机
Anthropic将Claude Cowork智能体扩展至网页端与移动端
OpenAI发布延迟模型,美国AI监管混乱引发企业隐忧
微软押注企业AI需要工程师而非庞大销售团队
Anthropic揭开Claude AI黑箱:J-space技术带来模型内部可见性突破
英格兰银行获授权监管亚马逊、谷歌等科技巨头
酷睿Ultra战力Plus,英特尔携九大合作伙伴亮相Bilibili World 2026
iOS 26.5.2正式发布,包含逾20项安全修复,Claude协助发现漏洞
