
鏖战双11 必看巨量引擎双11作战全景图
双11在即,早布局的商家,得先机。如何成为大促中的赢家?很多商家都已经开始谋划:
· 都在想种草,那种草如何更高效,甚至带动全域的销量攀升?
· 年年双11大促,电商都有行业爆款,我的爆款什么时候能出现?
· 大促流量争夺,新的流量蓝海到底在哪里?
鏖战双11,在抖音双11好物节的布局,必不可少。到底巨量引擎这次有哪些新玩法?话不多说,先收下这份最最最最最最全的双11作战全景图!

为了让商家“抢先解锁新增量”,巨量引擎率先发布了丰富的大促策略和激励政策:以“人群、货品、流量”三大营销势能,帮助商家在大促中找到更多增长可能。
势能1:人群做稳三波种草,全面促收
大促成交,主要集中在三个时间点爆发:10月中旬、10月下旬以及11月初到双11当天。集群效应明显的决策周期背后,是值得深入研究的消费者习惯。
巨量引擎根据用户需求变化,探索消费者最新驱动因素,结合商家经营目标,聚焦双11全周期,详细解读不同波段的客群消费路径,并推出“三波段种收策略”。
第一波:做好种收(10.9-10.19)“抢量CP”电商开屏 x IP + 深种链路“星推搜直”
要有交易,先要有交情,大促爆发前的种草蓄水成为斩获好感的重点动作。品牌商家可以在这一阶段加大曝光力度,借助爆品种草激活老客的同时拓展新客。
为此,巨量引擎双11推出“抢量CP”组合及“星推搜直”链路,助力商家极致种草。
“抢量CP”,包含“开屏”+“IP”两大类曝光利器。这种组合能够独占高价值人群,保障商家在双11前期拥有绝对优势的曝光,提前吸引用户目光。
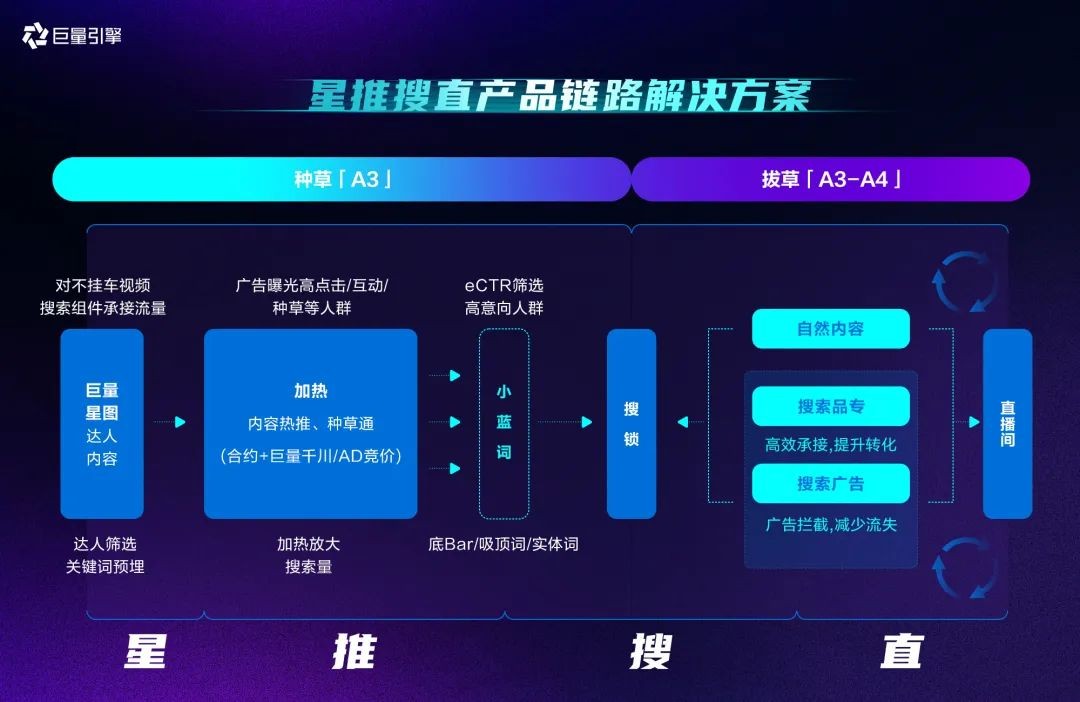
除此之外,巨量引擎首推的“星推搜直”种收链路,提供了种收一体的产品链路解决方案:
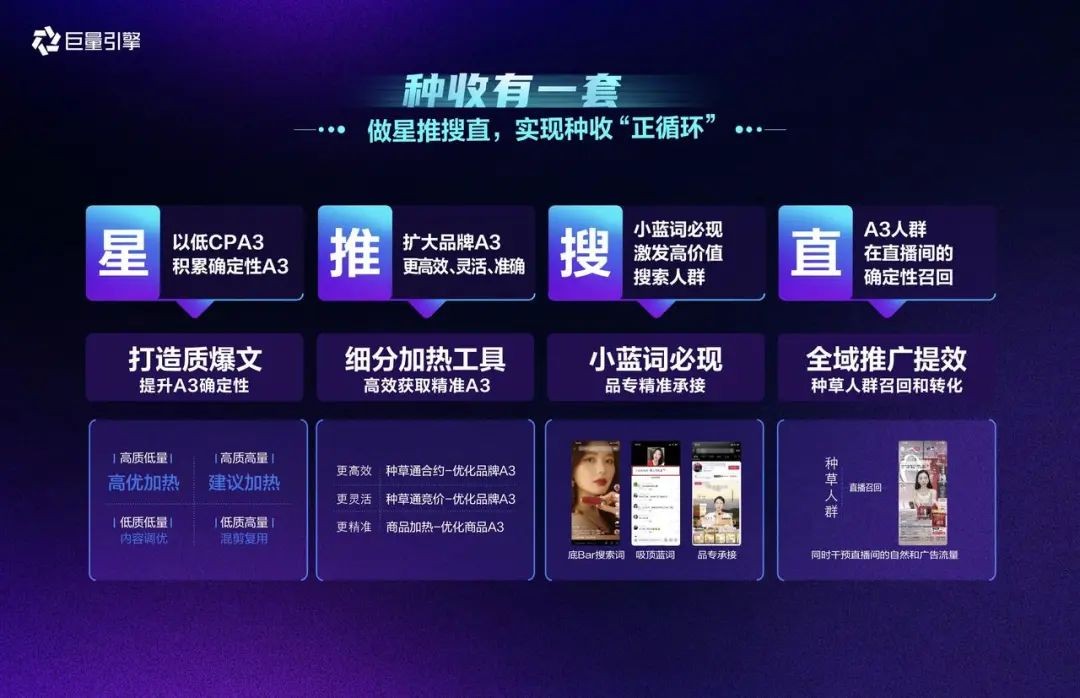
「星推搜直」以A3人群为轴心,通过星图、热推、搜索、直播,四大产品全新组合,构成了提升种收确定性的营销链路,大大降低种草成本。
第二波:做好预售(10.20-10.30)用好预售激励+推广,做好尾款追踪
预售期,是大促正式开启的阶段,抖音今年10月20日就开启预售环节,真正做到了抢跑全渠道,且针对预售做了能力升级:
(1)新增全款预售投放工具,包括千川短视频推广、商品卡推广、商品加热、随心推-商品购买在内的投放工具均支持全款预售;
(2)升级尾款催付能力,对消费者大促期间决策链路进行全方位锁定。
第三波:全域转化(10.31-11.11)三大场域,全周期“流量+红包补贴”
在第三阶段,巨量引擎鼓励商家联动货架场、内容场及站外三大场域,360度饱和覆盖用户在抖音的购买场景。
巨量千川、商城搜索、原生广告等各个产品均为商家提供全周期激励政策,让商家从抖音域内到域外,实现全域破峰。
势能2:货品分级打爆货品,领跑大促
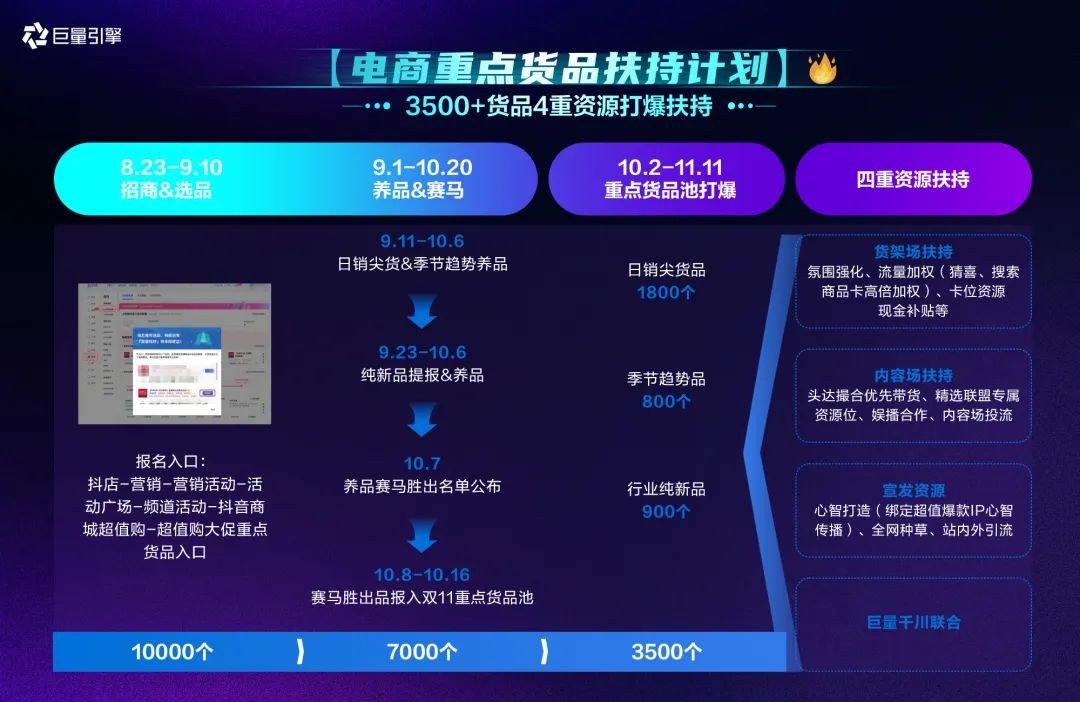
在今年的双11大促中,巨量引擎主张针对不同的货品进行分层运营:商家可以根据自己商品的属性对应选择合适的权益体系,此次针对货品,抖音电商重点推出货品扶持计划,通过赛马制,从10000个品中优选出3500个,给到重磅四重资源扶持,为重点商品保驾护航。
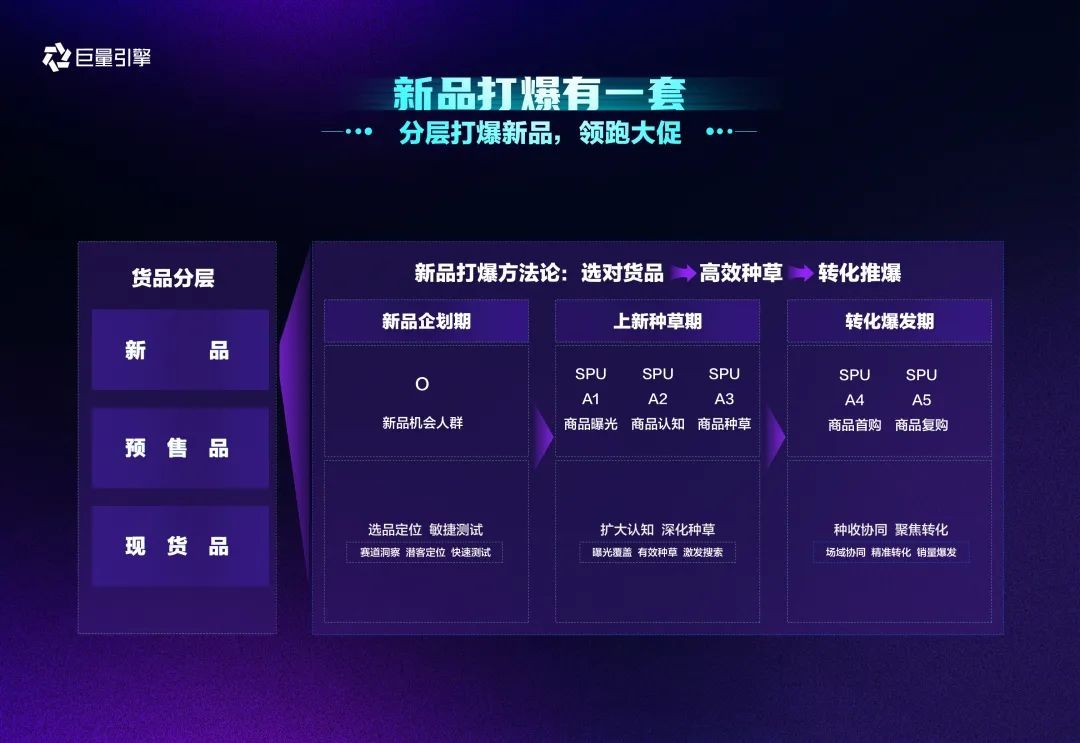
在新品支持方面,不少商家期待借助双11大促契机打出爆款。为此,巨量引擎提出了“双11新品打爆方法论”,提供从新品企划、上新种草到转化爆发的完整周期全链路营销方案。
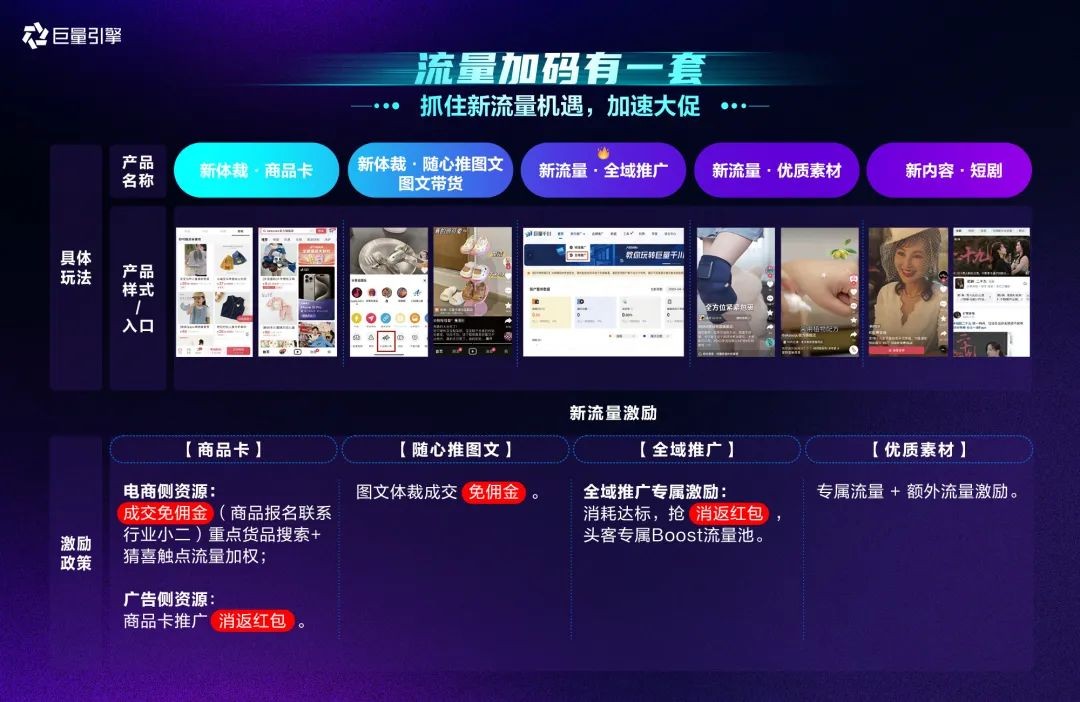
势能3:流量抓住新流量机会,加速大促
抓住新的流量,就等于有了新的机会。本次双11,巨量引擎也鼓励商家更多使用包含商品卡、随心推图文、短剧等在内的“新体裁、新流量和新内容”。
尤其是在挖掘自然流量的部分,巨量引擎全新推出全域推广产品,它能在更大的流量池中为直播间找到更高意向付费人群,让抖音的投放从局部最优升级到全局最优,持续带动品牌全渠道生意增长。
好生意,先人一步!
制胜双11,巨量引擎「星推搜直」全新种收链路、新品扶持计划、巨量千川双11激励等多样化工具和大促玩法,都将成为你的制胜法宝。
来源:业界供稿
好文章,需要你的鼓励


雪佛兰Equinox EV租赁价格大涨,月租金突破500美元
雪佛兰Equinox EV本月租赁价格大幅上涨。此前LT1车型月供仅需269美元,如今同等条件下已涨至554美元/月。与此同时,优惠力度也从最高1万美元缩水至1000美元,融资利率从0%升至2.9%。相比之下,2027款Bolt EV月供仅411美元,现代IONIQ 5最低259美元/月,特斯拉Model Y起步459美元/月,Equinox EV的性价比优势明显减弱。

清华大学研究团队揭示:机器人练武功,用3%的数据居然比用全部数据练得更好?
清华大学等机构提出LIMMT框架,通过三阶段数据筛选,用仅3%的动作数据训练人形机器人,追踪效果超越全量数据训练。

Decart发布Oasis 3世界模型,为机器人训练注入真实感
前沿AI研究机构Decart发布最新世界模型Oasis 3,旨在弥合虚拟仿真与物理AI之间的鸿沟。该模型将超写实交互图形能力与强大物理引擎相结合,可生成动作驱动的视频流,支持多视角环境模拟,延迟低于200毫秒。开发者能够借助自然语言提示,快速构建多样化极端场景,有效解决机器人和自动驾驶领域长期存在的"仿真到现实"差距问题,大幅降低物理AI训练成本。

中国人民大学AI团队揭开大语言模型的隐藏秘密:为什么你的AI助手不擅长“记住“文章含义?
研究发现大语言模型反嵌入矩阵的"边缘频谱"是导致文本嵌入质量差的根源,提出无需训练的EmbedFilter方法,最高提升MTEB得分14.1%并同步实现维度压缩。
2023
09/25
11:28
分享
点赞

逐代码星河 战算力之巅!2026第十三届并行应用挑战赛正式启航
九洲集团主动开拓越南供电项目,自研 HVDC 完成型式试验
Gartner划出五条赛道,中国AI正在集体提速
三一集团CIO许国强:数字化是必选项,AI是生存项
雪佛兰Equinox EV租赁价格大涨,月租金突破500美元
无锡(惠山)国产智算中心一期正式点亮,摩尔线程为具身智能及千行百业夯实算力底座
Decart发布Oasis 3世界模型,为机器人训练注入真实感
Visual Components 5.1发布:工厂仿真软件新版本支持大规模自主生产环境验证
AI既令人兴奋又让人焦虑,企业究竟该如何面对?
芬兰与瑞典联手推进6G韧性联合研究计划
微软公布智能体AI系统七大新型安全漏洞
GitHub Copilot推出桌面应用与画布功能,同步启用按量计费模式
