
华为发布AI存储新品,天才少年剧透面向大模型时代的下一代AI存储方向 原创
AI大模型全面爆发,技术更新迭代加速,中国正迎来AI产业爆发的机遇窗口。根据Gartner分析,生成式AI将进一步加速企业创新,约26%中国用户已着手对生成式AI技术的部署。
AI走向大模型时代,算力、数据集、参数成正比增长,带来了IT基础设施的大变革。我们看到,在通用大模型与行业大模型的训练推理中面临着也面临诸多数据难题:海量数据跨域归集慢、预处理与训练中数据交互效率低、数据安全流动难。
今天,在大模型时代华为AI存储新品发布会上,华为公司副总裁,数据存储产品线总裁周跃峰博士介绍了两款AI存储新品,华为苏黎世研究所存储首席科学家(华为天才少年)张霁分享了面向大模型时代的华为下一代AI存储方向。

企业应用多模态大模型过程中面临挑战
大模型时代,企业在应用多模态大模型过程中,面临新的挑战和新的机会:
数据准备阶段的问题,包括数据归集慢以及数据预处理周期长。
数据归集需要从跨地域的多个数据源拷贝原始数据,这些原始数据不能直接用于AI模型训练,需要将多样化、多格式的数据进行清洗、去重、过滤、加工,大量的数据预处理工作需要耗用大量的GPU,我们知道100个GPU每小时的训练成本是几十万,所以我们认为可以用近存计算技术系统性地处理这个问题,从而让整个系统更高效。
训练集加载效率问题和训练中断处理。
相较于传统深度学习模型,大模型带来训练参数、训练数据集呈指数级增加,如何实现海量的小文件数据集快速加载,降低GPU等待时间都是需要认真考虑的问题。同时,主流训练模型已经有千亿级参数,甚至将发展至万亿级。AI大模型训练不稳定,频繁的参数调优、服务器故障或者网络的故障经常造成中断,我们需要Checkpoint机制确保训练能够快速返回。华为正在通过创新的AI存储,高带宽、大容量的存储设备,支持万亿参数大模型训练。
企业实施大模型门槛高的问题。
现如今企业非常关注AI大模型,但是对于绝大多数企业而言,使用大模型不仅需要专业的知识储备、人才储备和专业系统实施能力,这对业务与数据可靠性等要求都会提升。如何降低大模型实施门槛,普惠千行百业,让企业能够轻松部署AI大模型,是我们一直努力的方向。
OceanStor A310深度学习数据湖存储,加速AI全流程业务

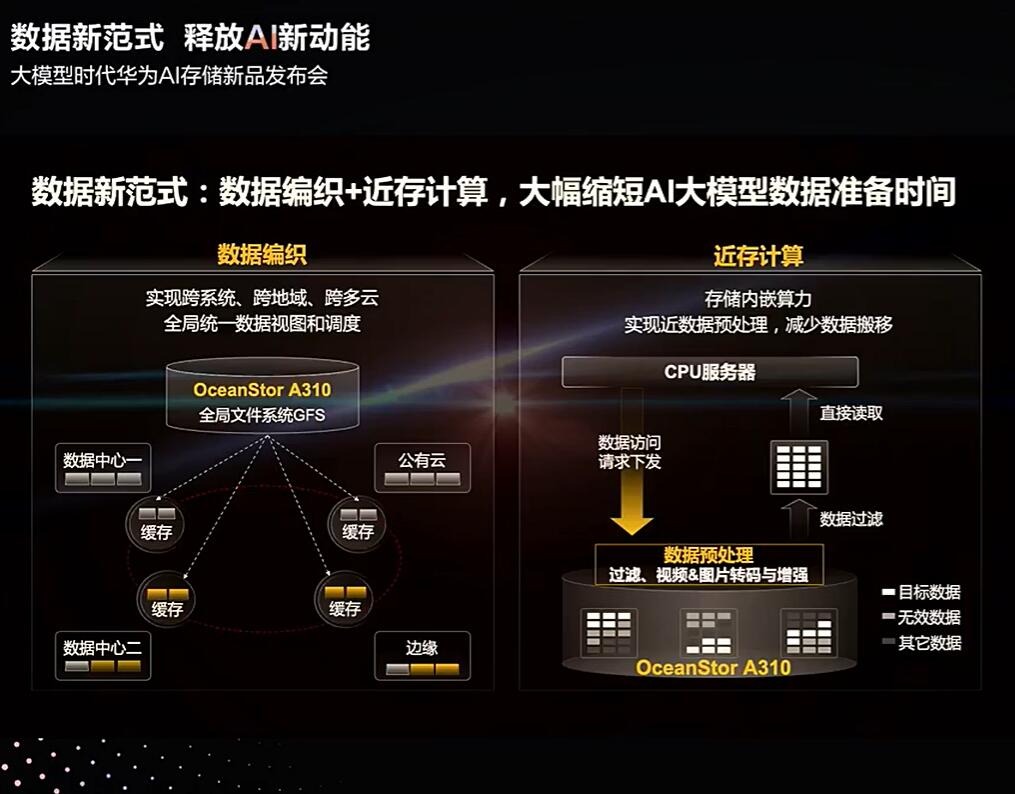
OceanStor A310深度学习数据湖存储,为智能数据而生,实现从数据归集、预处理到模型训练、推理应用的AI全流程海量数据管理。OceanStor A310提供5U 96盘位,带宽可达400GB/s和1200万IOPS,最大支持4096节点扩展。

利用全局文件系统GFS构建智能的数据编织能力,接入分散在各地域的原始数据,实现跨系统、跨地域、跨云的全局统一数据视图和调度,简化数据归集流程;OceanStor A310通过存储内嵌的算力实现近数据的预处理,减少无效数据传输,同时降低预处理服务器等待时间,预处理效率提升30%。
FusionCube A3000 训/推超融合一体机,降低AI大模型部署与使用门槛

FusionCube A3000训/推超融合一体机,面向十亿级模型应用,集成存储节点、训/推节点、交换设备、AI平台与管理运维软件,可实现一站式快速部署,通过预置AI大模型,2小时即可完成开局,真正做到开箱即用。并且整柜采用存算分离架构设计,存算完全可以灵活独立扩展,最终降低企业部署AI大模型的实施门槛。
高性能容器实现GPU共享,提升资源利用率。客户可以在边缘部署全流程的推理业务,并且每周或每月进行一次模型调优,这就需要多应用融合调度,大模型小模型融合调度。传统的IT系统,会为每一个应用预留GPU资源,也就意味着应用独占GPU,资源利用率仅40%。通过容器应用共享GPU资源池,资源利用率可以达到70%以上。
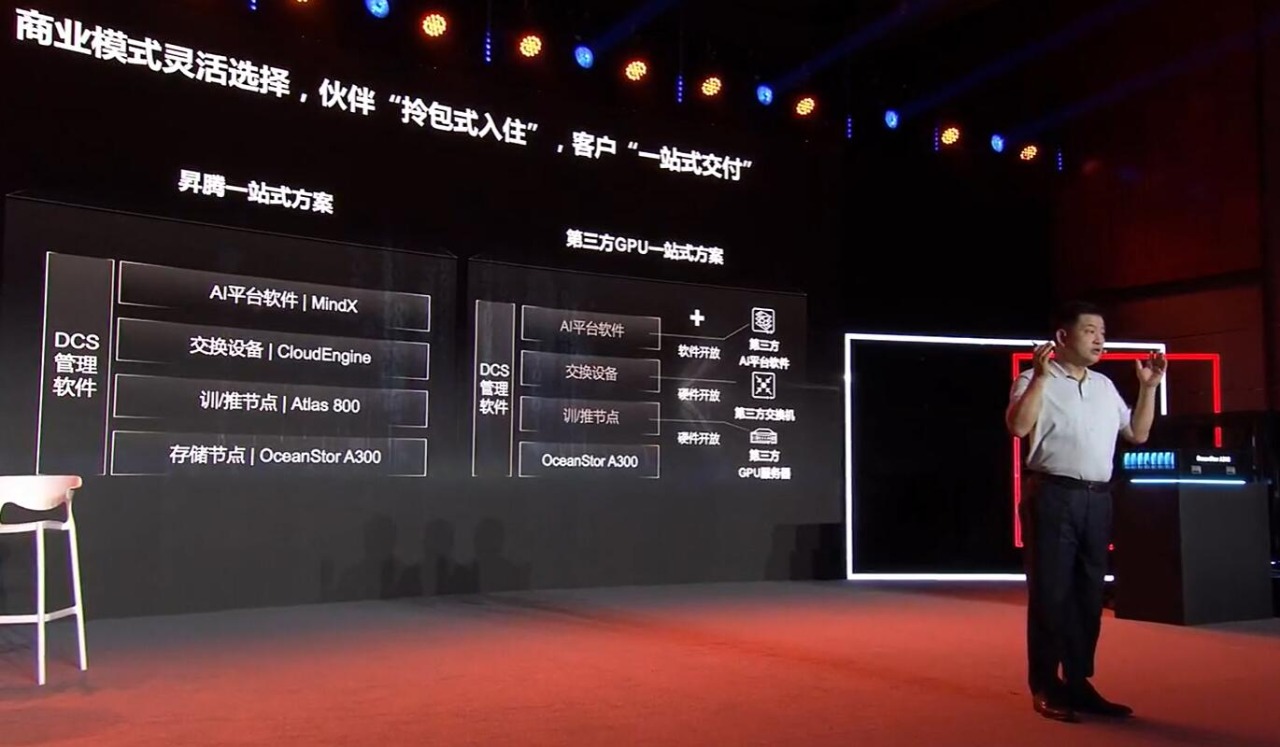
同时我们提供灵活的商业模式,让伙伴“拎包式入住”,让客户“一站式交付”。第一种昇腾一站式方案,集成了华为自研的存储、网络、计算、AI系统软件与管理运维软件,交付给客户快速部署。同时还有第三方GPU一站式方案,为伙伴提供拎包式入住能力。
比如数据归集需要从跨地域的多个数据源拷贝原始数据,这些原始数据不能直接用于AI模型训练,需要将多样化、多格式的数据进行清洗、去重、过滤、加工,大量的数据预处理工作需要耗用大量的GPU,我们知道100个GPU每小时的训练成本是几十万,所以我们认为可以用近存计算技术系统性地处理这个问题,从而让整个系统更高效。
华为天才少年谈未来华为研发方向

针对如何解决数据安全流转和提升大模型训练效率这两个长期挑战。张霁分享了华为最新的工作。华为正在研究“数据方舱”技术来解决数据安全流转的挑战,基于向量存储来解决大模型训练效率的挑战。
张霁表示,AI大模型分为三个阶段,数据归集,模型训练和模型推理。可以看到第一步就是如何进行数据的采集与处理,更多、更丰富、质量更高的数据才可以为模型的训练和推理提供更高的体验上限。那么在数据归集阶段,大模型能力的基础是尽可能地收集企业散落在各分支、各地域的数据。但是,数据是企业的核心资产,因此在跨地域归集的过程中必须保证数据安全地流转,做到数据不泄露。因此我们正在研究一种称为“数据方舱”的技术。数据在流转的过程中,数据及其访问权限、凭证信息都被封装在一起进行流转,而数据到达归集地后,将在“数据方舱”安全执行环境中被安全地使用,从而保证数据的安全访问。
周跃峰补充到目前“数据方舱”在国内也已经开展了几个联合创新的试验局点,包括在中信银行、贵州大数据局等单位。帮助客户在保障大量数据流转效率的同时,数据被安全地访问与使用。
针对如何提升大模型训练效率,张霁表示目前是“万物皆向量”时代,华为将联合科研机构在向量存储方向来解决传统存储架构的训练效率。
张霁谈到当前计算机体系结构依然是以CPU计算芯片为代表传统的冯·诺依曼架构,而GPU是针对AI场景定制的芯片,CPU和GPU速度差可达4-20倍以上。这带来的最大的问题是大多数情况下CPU跟不上GPU的处理速度,这样就会长时间使得GPU处于饥饿状态,导致昂贵的GPU资源浪费。基于这样的问题,我们当前在研究如何利用近存计算/存内逻辑的能力,在海量AI数据存放的源头进行适当的计算逻辑的卸载,释放CPU的部分能力,降低CPU和GPU的效率差,进而提高GPU的处理效率。当然这并非易事,所以我们在海外研究所联合了海思冯诺依曼实验室芯片团队,还有苏黎世联邦理工,洛桑联邦理工等高校的顶尖教授进行合作,在算法-架构、软硬协同上进行协同设计,希望在此问题上有更大的创新和突破。
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2023
07/14
10:57
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
