
研究人员设计出比DDR5快30倍的3D DRAM
东京工业大学的科学家们设计出一种新型3D DRAM栈,其顶部配有处理器,可提供比高带宽内存(HBM)高出四倍的传输带宽与仅五分之一的访问功耗。
HBM通过中介层将小型DRAM栈接入至CPU,从而避开了受到CPU限制的DRAM插槽数量。在Bumpless Build Cube 3D(简称BBCube3D)概念中,单个DRAM芯片通过微凸块(连接器)与上方或下方的芯片相连,而连接孔(通过硅通孔,即TSV)穿过芯片将各个微凸块连接起来。
研究团队负责人Takayuki Ohba教授表示,“BBCVube 3D拥有良好的性能潜力,可实现每秒1.6 TB理论传输带宽,相当于DDR5的30倍、HBM2E的4倍。”
研究人员们削薄了每个DRAM芯片,同时消除了BBCube3D晶圆叠层(WOW)设计中的微凸块。与DDR5或HBM2E(第二代高带宽扩展内存)设计相比,这种新方案使得内存块拥有更高速度和更低的运行能耗。这是因为前者的运行温度更高,而且凸块的存在会增加电阻/电容和延迟。
HBM微凸块还会占用空间,且芯片的硬度也必须达标,否则无法承受堆叠层合并所带来的压力。通过消除微凸块,每个内存芯片都可以变得更薄、硅通孔更短,从而实现带好的散热效果。BBCube3D设计还不需要中介层,因为处理单元、CPU或GPU能够直接绑定至缓存芯片,而缓存芯片本身又可绑定至DRAM栈的顶端。
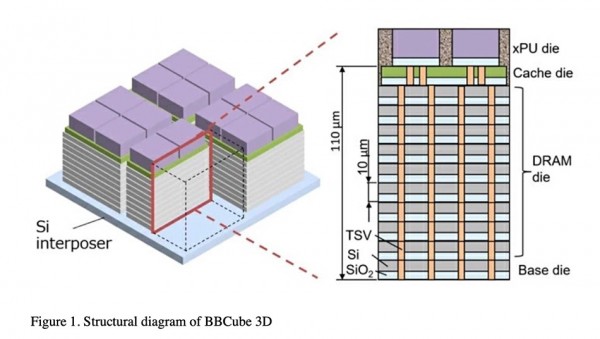
研究人员们解释道,“更短的硅通孔互连能够为CPU和GPU等高温设备提供更好的散热……高密度硅通孔本身就可以充当热管,因此即使是在3D结构当中,其预期运行温度也会更低。”
“由于硅通孔长度更短且信号并行度更高”,BBCube“能够实现更高带宽与更低运行功耗”。
通过调整相邻IO线的时序来确保其彼此异相,研究人员还成功减少了分层DRAM中的串扰。这种方法被称为四相屏蔽输入/输出,意味着IO线永远不会与其紧邻的线路同时发生值变化。
下图所示,为BBCube与DDR5和HBM2E内存技术的速度与能耗比较。可以看到,其带宽达到DDR5内存的32倍,速度相当于HBM2E的4倍。与此同时,BBCube 3D设计还实现了比DDR5和HBM2E更低的访问能耗水平。
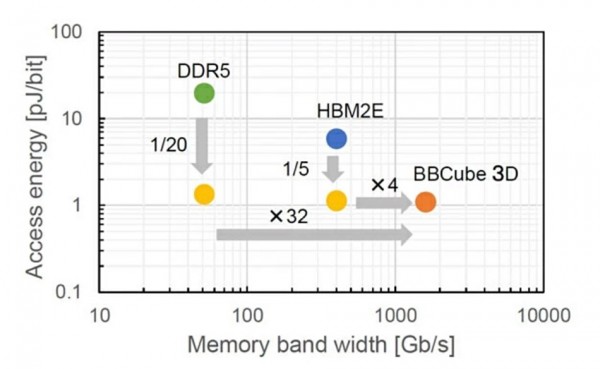
Ohba解释道,“由于BBCube的热阻和阻抗都更低,所以能够缓解3D集成设计中经常出现的热管理和电源问题。此次提出的新技术能够在达成可观传输带宽的同时,将每bit访问功耗降低至DDR5的二十分之一和HBM2E的五分之一。”
BBCube 3D属于高校主导的研究项目。关于该项目的详细背景信息,可以在MDPI Electronics论文《论使用晶圆上晶圆(WoW)与晶圆上晶片(CoW)实现兆级三维集成(3DI)的BBCube》(https://www.mdpi.com/2079-9292/11/2/236)中找到。论文提到,“BBCube允许将堆叠的芯片数量提升至HBM的4倍,意味着使用16 Gb DRAM裸片时内存容量可以达到64 GB。”
文章同时指出,“通过堆叠40层DRAM,即可实现Tb级别的3D内存。”
论文《Bumpless Build Cube (BBCube) 3D:使用WoW与CoW的异相3D集成实现TB/s级传输带宽与最低bit访问功耗》(Bumpless Build Cube (BBCube) 3D: Heterogeneous 3D Integration Using WoW and CoW to Provide TB/s Bandwidth with Lowest Bit Access Energy)对BBCube 3D概念也做了描述,文章发表于2023年6月的IEEE 2023 VLSI技术与电路研讨会。
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2023
07/06
09:59
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
