
数据安全法表决通过,神州数码TDMP全面推进数据安全建设
近几年,以数据为新生产要素的数字经济蓬勃发展,数据安全作为保障数字经济稳步发展的基石,相关的法律法规和监管制度也日益严格。2021年6月10日,《中华人民共和国数据安全法》由第十三届全国人民代表大会常务委员会第二十九次会议通过,作为数据领域的基础性法律,也是国家安全领域的一部重要法律,数据安全法进一步明确了企业在保障数据安全中的责任与义务,强调要建立健全全流程数据安全管理制度,采取相应的技术措施保障数据安全。
面对数据安全法提出的更高要求,神州数码独立设计研发的TDMP数据脱敏系统,基于灵活的脱敏策略、精准的隐私数据发现、多样化的脱敏方式和高效的脱敏算法等优势,为企业的数据隐私保护提供高安全性、高可用性、高可靠性、高稳定性、高效率的专业数据安全方案。
数据安全防护面临多重难点,数据识别能力亟需提升
当前,越来越多的企业正在通过引入专业的数据脱敏工具完善数据安全防御体系,提高数据安全管理和治理水平。但随着业务扩展、以及大数据、云计算等新技术的应用,企业数据安全防护的要求越来越高,防护的难度也越来越大,原有的安全防护模型逐渐难以满足现实的安全需求。
一方面,由于企业业务变更迭代和人员流动等问题,导致新的敏感数据未被数据脱敏系统及时识别和脱敏处理,造成敏感信息泄露的风险;另一方面,业务系统中经常存在非规范化敏感数据,这些数据的特征不够明显,无法使用正则和编码校验等方式去匹配,系统通过基于数据特征的方法很难识别到这类非规范化敏感数据,或者识别有误。
面对这类防护难点,数据脱敏系统需要加强自动化识别和动态变更的能力,同时也要提升非规范化敏感数据的识别能力。神州数码TDMP数据脱敏系统,通过采集元数据、采集样本数据、样本数据清洗和标准化、对样本数据识别并归类,可有效提升非规范化敏感数据识别率。

提升非规范化敏感数据识别率,为数据安全保驾护航
首先,数据脱敏系统需要采集业务系统数据库中的元数据,包括模式名、表名、字段名、字段类型、注释信息,系统会根据字段类型对数据的类型进行初步的判断。随后,数据脱敏系统会采集业务系统的样本数据,对每张数据表进行随机抽样,抽样时需要剔除噪声数据,包括空字符、null对象等,从而提高数据样本质量。
样本采集后,系统会对样本数据进行清洗和标准化处理。如果样本数据是规范且具有某种数据特征,数据脱敏系统会对样本数据进行精准识别。但通常会有一些样本数据并不规范,会导致系统识别出现误差。比如客户在录入电话号码的时候,可能将“88188286”写成“02888188286”、“028-88188286”、“(028)-88188286”、“88188286”。对此,系统需要对样本数据进行清洗和标准化处理,比如:将影响识别的字符诸如空格、非常用特殊字符、括号、中横杠等去掉;将全角类字符自动转换为半角字符;将乱码字符替换成汉字或剔除等。
最后,数据脱敏系统会对获取的样本数据进行分类与识别。在初步的分类中,系统会根据样本数据的数据类型进行归类,比如字符类型的数据通常不会存储金额类数据;数值类型的数据不会存储名称、地址类数据;日期类型的数据只能是日期时间类数据;大对象字段通常存储有文本、图片、报文等特殊的数据。
在对样本数据的识别上,数据脱敏系统会进行三轮识别。首轮识别中,系统根据数据的词汇特点进行初步匹配,对数据进行敏感信息大类划分,例如,全是汉字或汉字占比较高的可能是名称、地址等敏感信息类,全是数字或数字占比较高的可能是电话、账号等敏感信息类。首轮的识别和分类,可以减少数据脱敏系统对敏感数据识别的总体时间,提升识别效率;第二轮精确识别中,系统通过内置的高级识别算法对样本数据特征进行词法分析,并完成敏感数据的精确识别,识别成功的数据根据分类自动归纳到某种敏感信息类,识别失败的数据则交给AI敏感数据扫描引擎处理;AI敏感数据扫描引擎会加载某敏感类型和训练模型,经过模型运算输出敏感信息识别率,通过敏感信息识别率与敏感类型阀值大小比较判断是否识别成功,完成第三轮深度扫描识别。
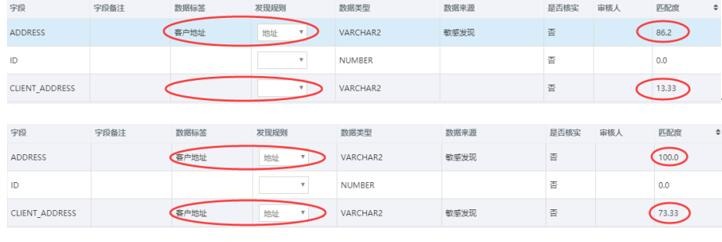
通过AI敏感数据扫描引擎识别非规范化敏感数据的精确度会远远高于非AI识别算法。以下面的扫描对比情况为例:ADDRESS的数据是规范化数据,CLIENT_ADDRESS的数据是非规范化数据,通过非AI识别算法,扫描CLIENT_ADDRESS的识别率仅仅13.33,而使用AI敏感数据扫描引擎后,识别率能达到73.33%。

基于强大的数据安全管理能力,目前,神州数码TDMP数据脱敏系统已在银行、保险、证券等领域多个头部客户的实际应用场景中落地。未来,以数据安全法提出的更高要求为目标,神州数码将继续积极探索,为企业的数据安全保驾护航,为数字经济发展提供安全稳定的保障。
来源:业界供稿
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

Upstage AI研究员揭示:当AI被要求填写一张完整的表格,它究竟在哪里翻车了?
Upstage AI构建韩语宽度搜索基准KO-WIDESEARCH,测试20个AI系统填写完整结构化表格的能力,揭示AI善于找成员却难以填对每格的核心缺陷。


阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。
2021
06/11
19:38
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
