
选择道熵分布式存储的六大理由
Q1、什么是分布式存储?
分布式存储将具有本地存储资源的标准服务器硬件,用高速网络连接,并通过分布式软件,聚合多个物理机上的存储空间并对外提供具有大带宽、并行 I/O、水平扩展、容错以及强一致性的数据存储系统。
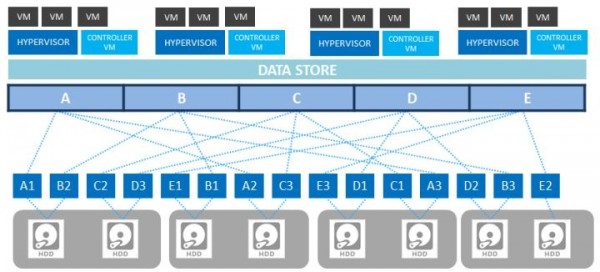
典型的分布式存储具有三大技术特征:一、使用通用x86或ARM存储服务器;二、使用固体硬盘(SSD)以提升IO性能;三、软件定义存储(SDS),即采用分布式多副本/纠删码技术,实现数据保护、资源智能调配调、自动化运维和监控功能,实现存储资源的抽象、池化和自动化管理。其优势在于可显著降低总拥有成本、提高性能和 IT 团队的效率。
Q2、分布式存储与传统磁盘阵列的对比?
分布式存储与传统的集中式共享存储,俗称磁盘阵列,存在明显的技术差别。磁盘阵列,最主要的技术特征是RAID,即Redundant Arrays of Independent Disks,通过多个独立磁盘构成的具有冗余能力的阵列来实现数据保护。传统的RAID磁盘阵列,采用冗余的硬件控制器架构,具有延迟小、性能高、稳定性好的特点,但横向扩展能力较差;当硬件逼近生命期限时,需要更换全套设备并迁移数据。而分布式存储扩展能力更强,可方便地进行在线扩展或更换存储节点。但分布式存储存在延迟较大、性能较差、稳定性不够好的缺陷。
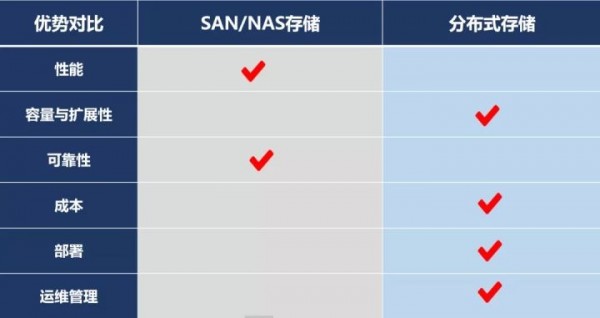
Q3、分布式存储市场的现状?
分布式存储是一个技术难度被显著低估的领域。随着HDFS、Lustre、GlusterFS、Ceph等开源分布式软件项目的兴起,一个普通软件工程师可以在一天或一周时间内搭建一个PoC分布式存储系统。包括华为、新华三、以及一些初创公司,在开源项目上优化,推出各自分布式存储产品,同质化现象严重,同时给行业带来假象,似乎分布式存储没有什么技术门槛。然而,无论是互联网公司,还是在企事业单位,由于使用分布式存储导致的业务中断、甚至数据丢失的报导屡见不鲜。

为什么(分布式)存储是一个技术壁垒很高的行业?这是由于存储最基本的核心诉求是数据不丢失、业务不中断。一个典型的存储系统包含上百万个电子元器件、上亿行软件代码,里面任何一个元器件老化失效、电子信号干扰、软件Bug、系统意外掉电,都有可能导致数据丢失。由此可见,要打造一个高可靠、高性能的分布式存储系统绝非易事。
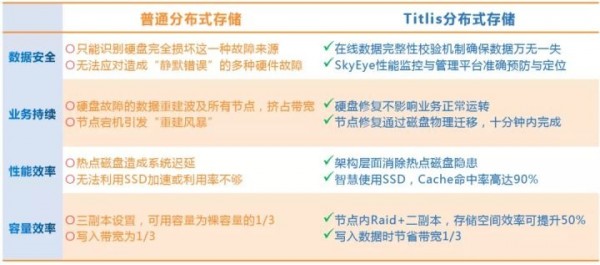
三副本和EC纠删码是分布式存储中常见的两种数据保护机制。由于EC纠删码存在比较严重的写放大问题,小块数据的写性能严重不足,通常仅适用于视频、备份、容灾等对IO性能要求不高的业务场景。在虚拟化、私有云、数据库等块存储场景,最常见的是三副本机制,即数据块按某种随机规则,保持在三个不同节点上的不同磁盘上。
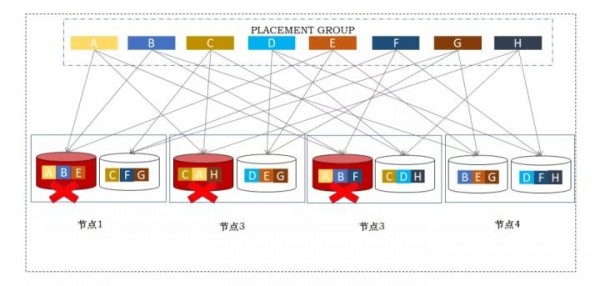 三副本分布式存储多节点硬盘损坏导致数据丢失
三副本分布式存储多节点硬盘损坏导致数据丢失
三副本分布式存储的数据可靠性可应对比较小的规模场景,但当存储规模扩大,或硬件老化时,系统可能出现两个、甚至多个磁盘同时发生故障的情况,可能导致业务中断和数据丢失。此外,由于数据修复依赖于网络带宽,网络的状态不稳定容易导致次生故障。因此,三副本分布式存储对运维的要求非常苛刻,隐形成本极高。
Q4、道熵分布式存储的技术路线?
针对三副本机制的弊端,道熵的铁力士分布式存储采用了双重RIAD机制,即节点内RAID与跨节点分布式两副本相结合,将磁盘阵列的本地恢复特性与分布式扩展特性融合,既有磁盘阵列的高可靠、高容错的特点,同时具备分布式横向扩展的优势。
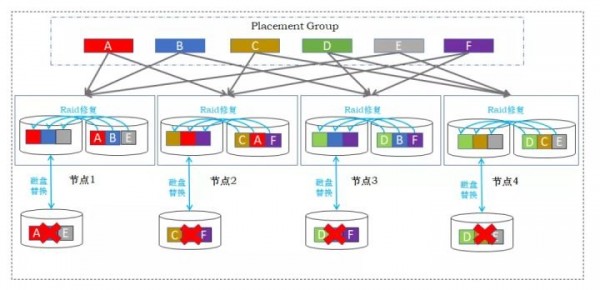
双重raid容忍多节点磁盘损坏
基于铁力士分布式存储的优越性能,道熵可为企事业用户提供更优的私有云与统一存储解决方案,满足用户数字化与智能化业务对IT能力的持续增长的需求。
选择铁力士分布式存储,有以下六大理由:
1、业务更稳定、数据更安全
业务系统对连续性有极高要求,需要提供 7*24 的不间断服务,而数据中心一直面临着各种风险和挑战,包括停电、网络故障、硬件故障等问题,都有可能影响业务的连续性。道熵分布式存储采用双重RAID架构,采用节点内RAID数据保护与节点间副本保护相结合的方式。每个节点采用RAID10或RAID50/60 实现节点内的本地数据保护、硬件故障隔离、与本地数据修护。每个节点相当于一个小型的“磁盘阵列”,可抵御节点内单个、甚至多个硬盘故障。
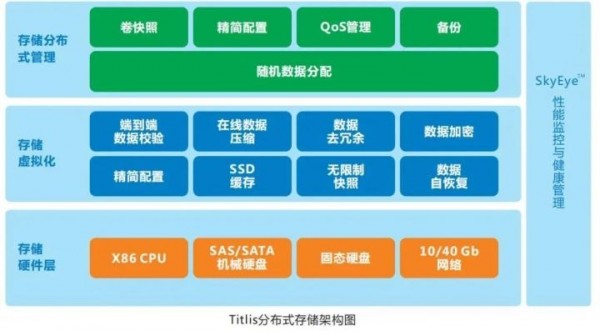
这些“磁盘阵列”通过网络连接与分布式副本技术管理,形成一个可扩展的分布式磁盘阵列,保证在极端情况下,即当故障突破单台磁盘阵列的保护能力时,还可利用网络副本技术来恢复节点数据。正因为这种双层RAID保护机制,当节点硬件出现故障时,可以通过本地RAID对故障进行隔离,不影响业务正常运行。故障修复可以采用延迟修复的策略,自动避让业务,即当业务繁忙时,数据修复减慢数据;当业务空闲时,数据修复可以适当加快速度。
2、业务更敏捷、资源交付更弹性
在传统的 IT 架构下,为满足业务系统的资源需求,用户需要独立采购软件和硬件设备;一般需要经历:预算-测试-招标-采购-部署-应用上线等流程,整个过程复杂、耗时,很难达到业务快速上线的目标。由于IT基础架构资源往往是基于某个业务系统上线而建立,与业务系统有比较强的耦合关系,资源之间无法流动,容易造成信息孤岛以及资源利用率较低等问题。此外,基于资源建设缺乏通盘的考虑,导致运维管理与扩展成本比较高。
道熵分布式存储的显著优势之一就是业务更敏捷、资源交付更弹性。用户可通过Openstack、VMware虚拟化平台,K8s容器,或物理机,迅捷地上线业务,提高资源利用率。通过Web管理界面,将集群所有CPU、内存、网络、及存储等资源进行统一纳管,建设统一资源池,实现更灵活的资源划分与交付;上述资源具备“弹性伸缩”特性,可对资源进行生命周期管理,既可迅速扩展资源规模,也可及时回收“闲置”资源进行重分配。
3、性能突出的统一数据存储平台
道熵分布式存储采用分布式两级缓存加速技术,实现性能加速。一级缓存为延迟低的DRAM,二级缓存为大容量固体硬盘,最热的数据保存在一级缓存中,次热的数据保存在二级缓存中。采用自适应算法管理缓存中的数据,能自动适应复杂业务工作流的变化,智能识别业务中最近使用的数据和频繁使用的数据,将其保存在缓存中。每个节点可单独增加一级缓存容量,和二级缓存容量,也可通过增加节点来增加总缓存容量。铁力士分布式存储可管理的总缓存容量,可高达数百TB,是名副其实的分布式存储“缓存之王”,能满足用户对存储性能弹性、可扩展的需求。
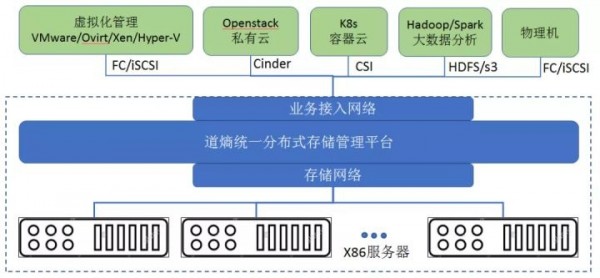
基于双重RAID架构的铁力士分布式存储平台,具备磁盘阵列的高稳定、高性能的特点,以及分布式存储的弹性和高扩展性,可作为企事业单位的统一数据存储平台,替代传统的磁盘阵列。铁力士分布式存储支持几乎所有的主流存储协议和接口,包含FC、iSCSI/iSER、NFS、Samba、Openstack Cinder、VMware VAAI、K8s CSI、S3、FTP、SFTP等,以及大数据接口HDFS、高性能计算BeeGFS、并行文件系统CephFS等。
4、具有内置备份与容灾功能、性价比高
道熵分布式存储具备内置的定时备份功能,可对虚拟卷实现全量备份和持续增量备份,并支持备份数据压缩、去重以及数据加密。备份数据可保持在本地或异地的NFS存储中,同时支持备份数据保持在支持S3存储接口的公有云或私有云中。
道熵分布式存储支持伸展集群(Stretched Cluster)部署,即同城双活数据中心:将数据从一个数据中心(站点)扩展到两个数据中心(站点),以实现更高的可用性和容灾恢复。伸展集群通常部署在同一城市或园区之内,两个数据中心之间的距离通常不超过100公里,且有专用(或租用)的高速低延迟通信线路相连接。拉伸集群可实现站点维护计划以及满足容灾需求,因为一个站点的维护或意外丢失,无论是通信故障、意外掉电、火灾还是其他灾害,不会影响集群的整体运行。在拉伸集群配置中,两个数据站点都是活动站点,同时提供存储服务。如果其中一个站点发生故障,存储服务将自动切换到另一个站点。
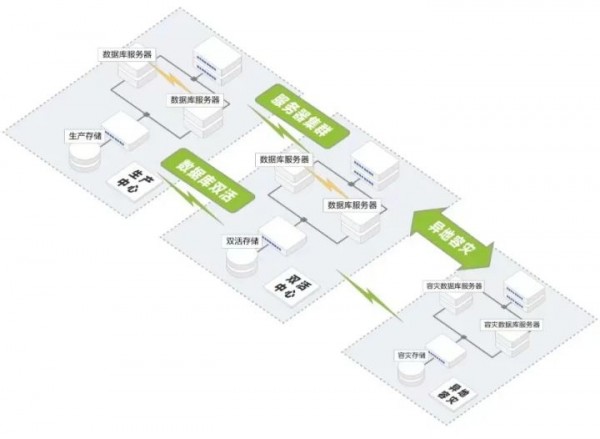
当数据中心之间的物理距离超过100公里以上时,道熵分布式存储支持两地或多站点之间,通过异步复制技术手段实现远程容灾与恢复。其原理非常类似数据库如PostgreSQL或Mysql的主从同步机制,基于日志回放(replay)实现本地站点和远端站点数据同步。基于异步复制的远程容灾与恢复方法,可实现RTO < 数分钟,RPO 约等于零的容灾保护级别。
道熵分布式存储还具备存储虚拟化网关功能,可针对异构存储系统,实现统一数据管理与容灾备份管理,并可实现连续数据保护功能。
5、业务更稳定、数据更安全
在分布式存储的演进过程中,系统中可能会同时存在新增硬件和老旧硬件,而老旧硬件的故障率通常远高于新增硬件,这对分布式存储的数据可靠性提出了更高的要求,即要求分布式存储具有更强的抵御硬件故障的能力。而常见的三副本分布式存储,在存储规模稍大,存在硬件老化现象的情况下,系统同时出现两个或以上硬盘故障的概率不可忽视,可能导致系统崩溃或数据丢失。
双重RAID架构,由于每个节点都具有本地RAID数据保护,可容忍的故障硬盘数目随节点增加而增加,可持续对硬件生命周期进行有效管理。当系统需要扩容时,可以在不停止业务的前提下,通过增加节点给存储加增CPU计算能力,内存,SSD,机械硬盘,以及网络资源,且能够实现数据自动迁移与平衡。同时,系统可以在线对故障硬件或老化硬件进行更换,甚至剔除整个节点。通过持续增加新硬件,剔除故障或老旧硬件,从而提高硬件的生命周期,有效降低硬件采购成本。
6、故障隔离与自动化运维能力强
在传统架构下,随着 IT 规模增大,数据中心将引入更多不同的设备以及技术,这无疑增大了运维的复杂性,使得企业的 IT 人员经常上演“消防员”角色,即便是这样也难以达到“不间断”运行的目标。
道熵分布式存储的节点内RAID功能,不是采用常见的硬件RAID控制卡来实现,而是通过功能更强大的存储虚拟化管理(Storge Virtualization Manager,SVM)来实现。SVM不仅实现了RAID10/50/60等RAID功能,而且具备池化管理和IO负载均衡能力,IO工作负载均匀分布在节点内所有磁盘上。SVM具备在线数据完整性校验和数据自修复功能,对硬件故障进行在线监测和有效隔离,即使在硬件老化时仍然能保证数据安全;功能强大的Web管理页面具有专门的自动化故障诊断模块,通过图形可视化收到实现监控各种运行状态,包括CPU、内存、网络、IOPS与带宽指标,同时具备对磁盘监控状态、网络、电源、主板等硬件的故障监控、报警、及自动化诊断功能,使得整个系统的运维与管理变得简洁直观。
来源:业界供稿
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2021
04/27
20:51
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
