
戴尔科技财报出炉:整体营收利好!传统存储业务除外
伴随着第四季度营收再度走低,EMC全年营收缩水11%。
戴尔科技集团在各大业务领域都交出了一份令人满意的2018年第四季度答卷——当然,存储业务除外。没错,EMC的加入让巨头戴尔的存储业务营收同比缩水达11%。
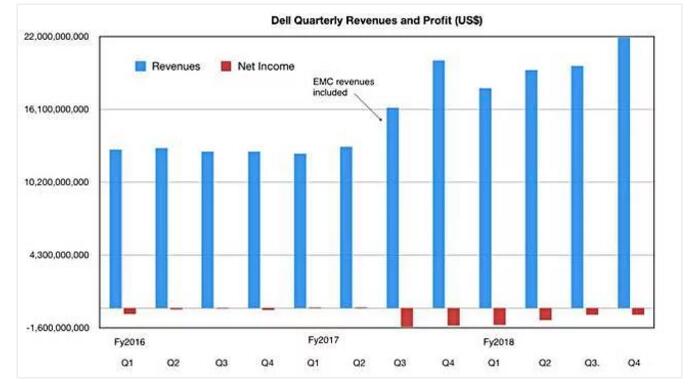
戴尔科技集团公布本季度整体营收为219.4亿美元,较上年同期增长9%。净亏损为5.33亿美元,情况同样远好上年同期的14亿美元亏损额。
下面来看具体数字:
|
|
2018年第四季度 |
2017年第季度 |
变化 |
|
终端客户解决方案集团 |
106亿美元 |
98亿美元 |
+8% |
|
基础设施解决方案集团 |
88亿美元 |
83.8亿美元 |
+5% |
|
VMware |
23亿美元 |
19亿美元 |
+20% |
|
其它 |
4.92亿美元 |
4.777亿美元 |
+3% |
为什么基础设施解决方案业务的增长率仅为5%?
|
|
2018年第四季度 |
2017年第季度 |
变化 |
|
存储 |
42.36亿美元 |
47.83亿美元 |
-11% |
|
服务器与网络 |
45.76亿美元 |
36.12亿美元 |
+27% |
|
总体 |
88.12亿美元 |
83.95亿美元 |
+5% |
其中存储一项就严重拉低了整体表现,并与服务器及网络业务高达27%的增幅形成鲜明对比。
在服务器方面,戴尔易安信的PowerEdge与Cloud服务器(服务器产品平均售价有所提升)都实现了两位数的增幅,继续保持着良好的增长势头。事实上,服务器与网络营收在本季度首次超越了存储收入。
戴尔科技集团产品与运营副总裁Jeff Clarke作出了以下说明,而我们能够从其言下之意中领会到其它线索:
我们的所有细分领域都取得了增长,特别是在商业客户与服务器及网络领域展现出强大的实力。此外,我们第四季度中在超融合基础设施营收方面迎来三位数增长,全闪存产品也实现两位数增长。我们认为,2019财年亦将成为传统存储业务的重要复苏机遇。
超融合基础设施与全闪存阵列确实发展势头喜人,纵观整个2018财年,全闪存营收已经逼近50亿美元大关。不过这同时意味着,磁盘与混合阵列、软件定义存储以及数据保护产品的表现则不太令人满意。
PC业务再度蓬勃发展
戴尔科技集团表示,其PC业务部门已经连续第二个季度实现销量同比增长。随着笔记本电脑与工作站产品平均售价的提升,再加上显示器营收的两位数增长,商业客户类营收顺利实现9%的同比涨幅。
移动工作站与Latitude业务在出货量与营收方面双双实现两位数提升。根据IDC发布的统计数据,戴尔公司目前已经成为全球工作站产品的龙头老大。
消费级营收亦凭借着笔记本电脑与XPS产品平均售价的上涨实现了6%的同比营收增长。
全年统计数字
2018财年全年营收总额为787亿美元,较上年全年的616.4亿美元增长27.6%。净亏损额为38.6亿美元,略好于上年的37.4亿美元亏损。
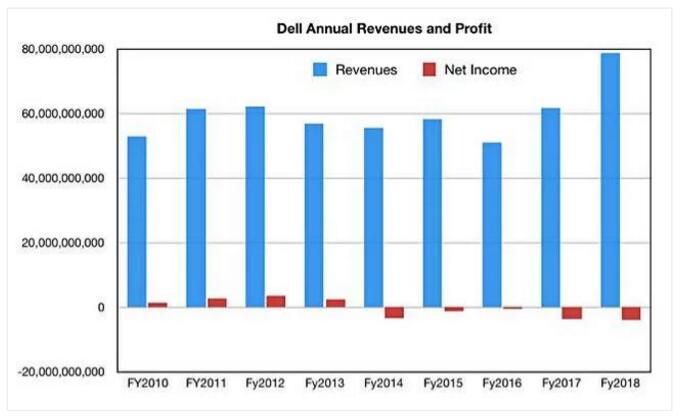
然而,戴尔科技集团指出:“上一年的历史财报数据并不包含EMC公司2017财年第一、第二季度全季以及第三季度的部分收入,因此全年统计数据并不确切。EMC的营收贡献仅有2017财年第四季度被完整计入,所以只有第四季度具备比较意义。”
戴尔科技集团指出,自EMC收购交易完成以来,其已经偿付了100亿美元债务,且目前手中掌握着68亿美元运营现金流。
戴尔科技集团CFO Tom Seet表示:“我对2018财年的表现感到满意。我们以良好的收入与盈利势头结束了这一财年,且非GAAP营收同比增长15%。我们的提升速度达到或超越了市场上各业务领域的平均水平,并带来了强劲的运营现金流。”
着眼于2019财年,戴尔科技集团表示其希望能够进一步超越市场发展速度并实现股价上涨,特别是在存储与客户解决方案层面。其希望通过“平衡服务器销售与利润空间的方式提高基础设施解决方案部门的盈利能力,同时加快存储与数据保护业务的增长速度。”
我们也将在2019财年当中持续关注戴尔科技集团如何着力推动其传统存储业务重回增长正轨。
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

当AI“管家“学会分工协作:卡内基梅隆大学研究团队如何让电脑操作智能体突破单打独斗的瓶颈
卡内基梅隆大学提出MACU框架,让经理AI统筹多个员工AI并行完成复杂电脑操作任务,通过动态调整任务图,在四个基准上均超越单智能体。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

康奈尔大学造出“会看图纸的AI设计师“:一张照片,自动还原可编辑的3D场景
康奈尔大学提出SEIG框架,让视觉语言模型通过分阶段重建几何、材质、构图和灯光,从单张图片自动生成可编辑的Blender 3D场景。
2018
03/09
12:23
分享
点赞

Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
Infineon Live Lab正式发布:全球首个实时云端实体硬件评估平台
Serve Robotics携手NoScrubs,自主配送机器人跨界拓展洗衣服务
Workr Robotics CEO:工业机器人自动化应按小时付费
专访CreateMe CEO:从缝纫到粘合,实体AI如何重塑服装制造
AI浪潮为集成商带来全新连接挑战
