
分析师:永久内存技术很酷,但价格过高
有分析师表示,XPoint和其他永久内存技术成为服务器设计标准的前景正在受到阻碍,因为这些部分成本太高。
因为这是小批量生产的,所以不会出现规模经济使其成本更低一些。
Object Analysis分析师Jim Handy在1月份的SNIA闪存高峰会上解释了这一点,并从内存层开始分析。
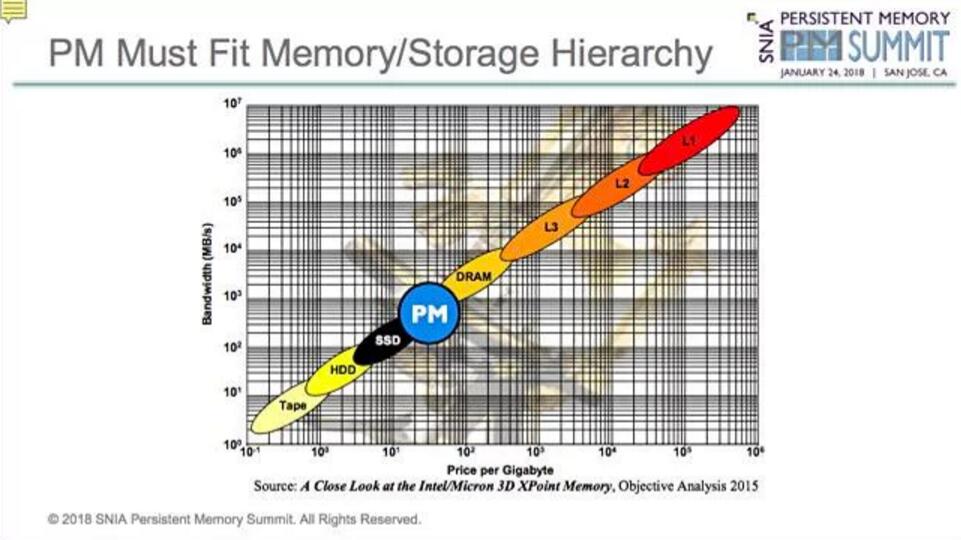
Objective Analysis内存层的幻灯片
这个图表显示了在一个以性能定义的领域的内存和存储技术,也就是带宽(垂直访问)和成本(横轴)。
从左到右有一个对角线,从底部的磁带(慢速低成本)到磁盘、SSD、DRAM和缓存层到L1缓存,这是图表上最快和也是成本最高的部分。
在任何时候任何点想要冲入内存层的新技术都要比它之下的技术性能更高,比其上的成本更低。
我们已经看到NVDIMM试图填补SSD-DRAM的差距,但普遍失败了——例如Diablo Technologies。
Handy表示,在2004年前后NAND也遭遇了同样的问题,在此之前SLC(1位/单元)规格下,要比DRAM(每GB成本)成本更高,尽管一个100毫米模片采用了44纳米工艺、可保存8GB的数据,相比之下同样的DRAM模片可保存4GB数据。两倍的数量意味着成本减半,但实际上并没有——因为没有足够的产量来实现规模经济。
Handy表示,2004年,NAND闪存晶圆的数量达到DRAM晶片数量的三分之一,我们看到了一个交叉点:

自从NAND和DRAM价格曲线分开之后,MLC(2位/单元)、TLC(3位/单元)和3D NAND(更多位/芯片)也加速了分离。
后来出现的永久内存(PM)技术的制造成本很高,因为它涉及到新材料和新工艺,这使其更加昂贵,这就延长了获得制造规模经济所需的时间。
制造更多,支持更多
对于XPoint来说,NAND、NVDIMM-N以及其他针对填补DRAM-NAND空白的永久内存技术带来的经验教训,就是其制造产量需要足够高以提供一个能够填补内存层图表上空白的性价比:

Handy认为,其制造量需要接近DRAM,还需要软件支持,特别是永久内存,要支持运行在Linux、Windows和VMware上。最初的PM占用是针对性能的,并且要求比NAND性能更高的速度和低于DRAM的价格。
Handy认为,在XPoint实现这一点之前是不会普及的。他表示,英特尔有足够的动力来实现这一目标。
评论
如果三星能够使其Z-SSD价格足够便宜,那么它可以比XPoint更快地填补内存层上的DRAM与SSD之间的空白,并防止XPoint成为主流,而三星在开发自己的后NAND永内存技术以赶超XPoint。
其次,与XPoint竞争的技术,如STT-RAM、ReRAM和相变内存都还在开发中,除非有一个实际的路径来制造影响力。这是一个严酷的世界。
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。

