
3D NAND为实现四级单元提供了可行性
关于四级单元闪存纠错问题的潜在解决方法。
与此前的平面NAND相比,3D NAND技术的运用将使得错误检查代码更易于实现,这也进一步确定了容量提升的四级单元技术的可行性。
错误检查代码(ECC)技术的使用范围包括通过采用算法以计算为存储数据添加冗余所需添加与使用的位数,在固定大小区域内工作的分组代码与Reed-Solomon编码即是此类技术的应用实例。并且与该技术能够完成的纠错量相比,其可检测到的错误数量更多。
低密度奇偶校验(LDPC)编码是ECC技术的一种较新版本。BCH(Bose-Chaudhuri-Hocquenghem)编码则是另一项纠错技术,这种二进制BCH编码可被设计用于多位数纠错。通常而言,客户希望能够完成的纠错位数越多,则需要添加到数据中的冗余ECC位数就越多。
由于读取单元无法提供明确的1或0,因此在这种情况下,一个或多个字节的值可能会因错误而失真,所以NAND闪存需要配有ECC。
而ECC编码则能够检测并纠正以上所提及的错误。
随着NAND读取难度的增加,需要添加的ECC位数与ECC算法的复杂程度也随之提高。其中,“读取难度”一种概括性说法,其具体是指单元可读性随着单元尺寸与其所存储的位数增加而降低。
举例而言,小单元之间可能存在跨区效应,具体表现为一个单元内的设置值可能会对相邻单元内的设置造成一定影响。而其中所涉及的设置值还包括电子——其数量与稳定性会随着单元尺寸缩小而降低。
因此,与SLC(一级单元)相比,MLC(二级单元)与TLC(三级单元)闪存的读取固然会更困难。当然,尽管QLC(四级单元)在技术上已具有一定可行性,但由于单元可读性以及ECC编码与算法仍是亟待解决的两大难题,所以直到现在QLC还尚未具备实用性。
SanDisk公司曾于2009年试图采用43纳米几何平面结构实现QLC NAND的生产,但在经历了一年左右的研究后即选择了放弃。
同样,与25纳米单元以及35纳米单元相比,20纳米的MLC闪存单元更难实现读取。此外,16纳米的MLC闪存单元则是很难实现再次读取,而在此级别上所采用的ECC已经实现了BCH与LDPC ECC技术的融合。
根据Objective Analysis公司的Jim Handy简要报告可知,选择采用3D NAND将会让这些难题简化。
其中的两大主要原因如下:
首先,当3D NAND闪存芯片建成之后,单元尺寸将从15纳米恢复至40纳米左右,尔后即可在该芯片上采用最先进的2D或平面NAND技术。
其次则是源于3D NAND的构建方式。“3D NAND的浮栅或电荷捕获将在作为通道的接杆附近形成一个圆圈,从而让其面积增加了三倍以上。故而现在3D NAND芯片的面积大致相当于一款90纳米的平面NAND芯片。”
另外,Jim Handy还提供了一张图表以展示MLC与TLC闪存在不同单元尺寸条件下通常所需的ECC位数。
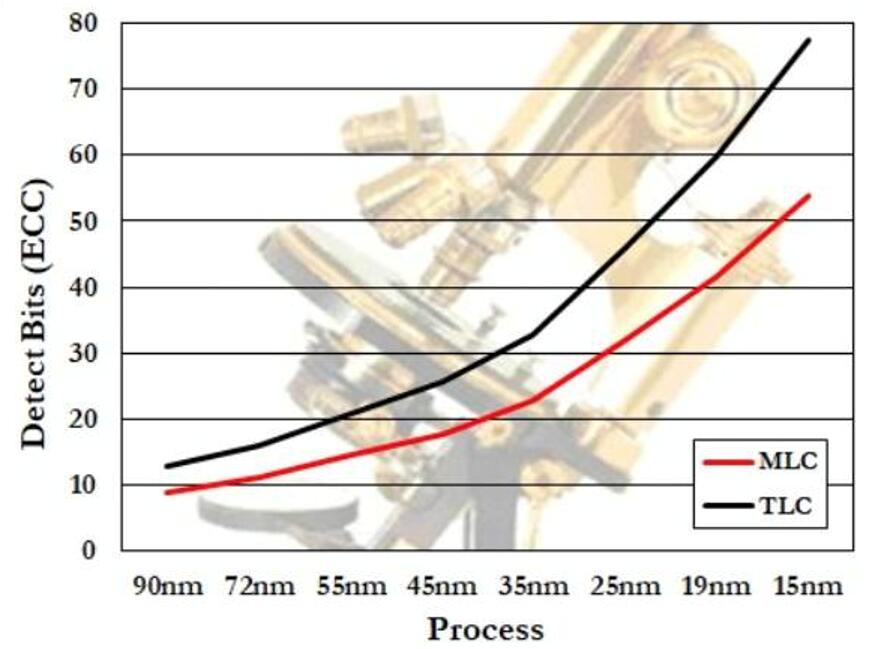
根据图表显示,TLC NAND闪存的单元尺寸在15纳米工艺几何尺寸时所需ECC位数已超过75比特,而当芯片的几何尺寸为90纳米时,ECC的位数需求则在15以下。
对此,Handy在其报告中写道:“我们据此即可推断QLC 3D NAND所需的位数将少于20。这也是为何与以往的平面NAND相比,采用3D NAND能够提升QLC可行性的原因。”
此外,Handy还描绘了每单元拥有更多位数的前景。“从长远看来,我认为大多数3D NAND控制器将会采用LDPC以确保每单元存储4字节以上的数据。当然,实现这一目标需要一些时间。而在短期内,3D NAND将能够通过使用简单的BCH算法完成其向QLC转变。”
试想每单元能够存储5比特字节的闪存——或称之为五级单元或PLC闪存?由于QLC已经用于代表四级单元闪存,所以我们不能将五级单元按quintuple level cell首字母缩写命名,并且其将比QLC闪存增加25%,每单元存储为5比特而非4比特。因此,一款容量为1 TB的QLC SSD或将可能变为1.25 TB的PLC SSD。恩,此番前景的确令人欣喜,但或许仍需数年才能得以实现。
目前看来,QLC闪存似乎已具备一定的可行性,我们或将于今年年底便可见其真身。
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。

