
IBM Storage Scale被采用于Blue Vela AI超级计算机
IBM的Vela AI超级计算机功能已经不足以满足IBM研究院的AI训练需求。于是2023年开始研发的Blue Vela旨在满足GPU计算能力方面的重大扩展,用以支持AI模型训练需求。截至目前,Blue Vela正被积极用于运行Granite模型训练作业。

IBM Blue Vela示意图。
Blue Vela基于英伟达的SuperPod概念打造,并采用IBM自家的Storage Scale设备。
Vela被托管在IBM Cloud之上,但Blue Vela集群则托管在IBM研究院的本地数据中心当中。这意味着IBM研究院拥有全部系统组件的所有权及责任,涵盖从基础设施层到软件技术栈的整个体系。
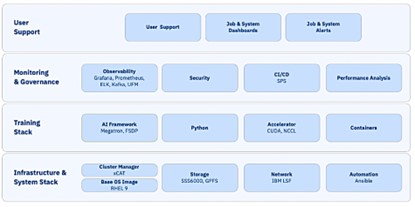
Blue Vela系统中的各层。
随着训练体量更大、连接更紧密的模型所需要的GPU数量的增长,通信延迟成为影响结果的关键瓶颈。因此,Blue Vela的设计从网络起步,围绕四种不同专用网络构建而成。
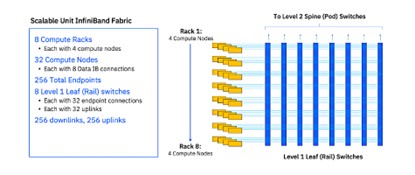
- 计算InfiniBand结构,促进GPU到GPU之间的通信,如下所示;
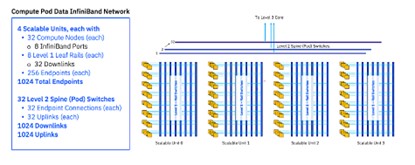
- 存储InfiniBand结构,提供对各存储子系统的访问,如下所示;
- 带内以太网主机网络,用于计算结构外部各节点间的通信;
- 带外网络(也称管理网络),提供对服务器和交换机上的管理接口的访问。
Blue Vela基于英伟达的SuperPod参考架构。其采用128节点计算Pod,其中包含4个可扩展单元,每单元又包含32个节点。这些节点均采用英伟达H100 GPU。英伟达的Unified Fabric Manager统一结构管理器(FCM)则用于管理由计算和存储结构组成的InfiniBand网络。该管理器有助于识别并解决单个GPU限流或者不可用问题,而且无法兼容以太网网络。
各计算节点基于戴尔PowerEdge XE9680服务器,具体组成包括:
- 双48核第四代Gen英特尔至强Scalable处理器;
- 八英伟达H100 GPU加80 GB高带宽内存(HBM);
- 2 TB RAM;
- 十英伟达ConnectX-7 NDR 400 Gbps InfiniBand主机通信适配器(HCA);
-其中八个专用于计算结构;
-两个专用于存储结构
- 八块4 TB Enterprise NVMe U.2 Gen4 SSD;
- 双25G以太网主机链路;
- 1G管理以太网端口。
IBM“修改了标准存储结构配置,旨在集成IBM新的Storage Scale System(SSS)6000,我们自己也成为首家部署该系统的公司。”
这些SSS设备属于集成化的纵向/横向扩展存储系统,可容纳1000台设备,且安装有Storage Scale。其支持自动、透明的数据缓存以加快查询速度。
每个SSS 6000设备均可通过其InfiniBand和PCI Gen 5互连提供高达310 GBps的读取吞吐量及155 GBps的写入吞吐量。Blue Vela最初拥有两个满配SSS 6000机箱,每机箱配备48 x 30 TB U.2 G4 NVMe驱动器,可提供近3 PB的原始存储容量。每台SSS设备最多可额外再容纳七个外部JBOD机箱,每机箱最多可提供22 TB的容量扩展。此外,Blue Vela结构最多可容纳32台SSS 6000设备。
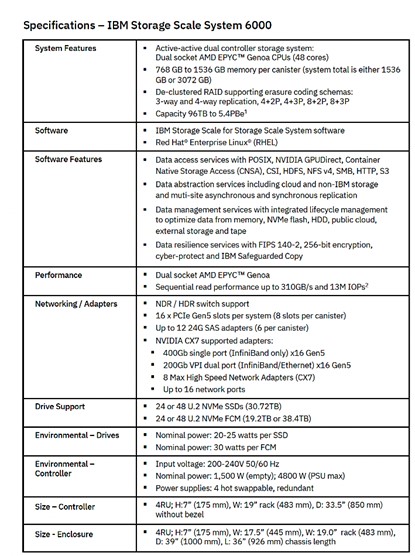
IBM表示,基于FCM驱动器及3:1压缩比率,其最大有效容量可高达5.4 PB,具体取决于存储在FCM当中的数据特性。
Blue Vela使用戴尔PowerEdge R760XS服务器以建立单独的管理节点,可用于运行身份验证与授权、工作负载调度、可观察性及安全性等服务。
在性能方面,论文作者表示“从一开始,这套基础设施也表现出了良好的吞吐量潜力。与同等配置的其他环境相比,其开箱即用性能提高了5%。”
“集群的当前性能显示出良好的吞吐量水平(每天90至321B,具体取决于训练设置与实际训练的模型)。”
Blue Vela性能统计。
IBM研究论文中列出了关于Blue Vela数据中心设计、管理功能以及软件堆栈的更多详细信息,感兴趣的朋友可以点击此处(https://arxiv.org/abs/2407.05467)查看。
来源:至顶网存储频道
好文章,需要你的鼓励


OpenAI联合创始人Greg Brockman:从游戏AI到通用智能,我们的创业一路意外,ChatGPT模式都是不得已的选择
OpenAI意外发现规模假说:Dota 2项目中计算资源翻倍带来AI表现翻倍,彻底改变行业轨迹。Greg Brockman揭秘GPT-3产品化困境:"我们不知道谁会为API付费",最终市场自己找到了出路。AI医疗突破只需超越WebMD,个性化咨询正在重塑多个领域。

AI如何成为蚊子“神探“:孟加拉国大学研究团队打造史上最强蚊子繁殖点监测系统
孟加拉国联合国际大学研究团队开发了VisText-Mosquito多模态数据集,这是首个集成视觉检测和自然语言推理的蚊子繁殖点识别系统。该系统包含1970张标注图像,能够识别五类繁殖容器并进行水面分割,同时提供人类可理解的判断解释。YOLOv9s等模型达到92.9%检测精度,为全球蚊媒疾病防控提供了AI技术支撑。

存储行业动态:多项技术突破推动数据管理创新发展
存储行业近期动态频繁,Arctera、Wasabi和TD SYNNEX联合推出渠道专属数据保护解决方案;AWS启用EC2环境SAN启动功能;Broadcom发布VMware Cloud Foundation 9.0版本;Commvault与Kyndryl合作提升网络弹性服务;CTERA成为首家支持模型上下文协议的混合云存储供应商;多家企业获得新一轮融资,推动AI基础设施和数据管理技术发展。

特拉维夫大学AI研究员惊人发现:越“万能“的AI攻击越善于“劫持“注意力
特拉维夫大学研究团队通过分析GCG攻击机制,发现越狱攻击的成功依赖于"注意力劫持"现象,即攻击后缀能占据AI注意力机制的主导地位。研究表明,攻击的万能性与劫持强度直接相关,并基于此开发了增强攻击效果和防御攻击的实用方法,为AI安全研究提供了新视角。
2024
08/06
14:50
分享
点赞

OpenAI联合创始人Greg Brockman:从游戏AI到通用智能,我们的创业一路意外,ChatGPT模式都是不得已的选择
存储行业动态:多项技术突破推动数据管理创新发展
亚马逊AI助手Alexa+用户突破100万,月费定价19.99美元
Salesforce发布Agentforce 3,提升AI智能体可见性和连接性
自动驾驶汽车加速落地,城市如何引领变革
Grok将推出电子表格编辑功能挑战微软谷歌
Hitachi Vantara获评GigaOm雷达报告面向AI工作负载优化的高性能存储“领导者”与“快速发展者”
智能芯片如何解决AI能耗危机
谷歌为Chromebook带来全新Gemini功能,首推设备端AI
光谱科技为鲁宾天文台500PB宇宙延时影像提供存储方案
欧洲卫星通信公司获得13.5亿欧元融资扩展卫星服务
自动驾驶汽车技术市场迎来发展机遇期
