
基于合作伙伴产品,戴尔构建Data Lakehouse智能湖仓
戴尔使用第三方合作伙伴的软件,配合自家服务器、存储和网络硬件/软件,共同构建起一套数据湖/智能湖仓参考架构设计方案。
与Databricks、Dremio、SingleStore和Snowflake等同类厂商一样,戴尔建立的也是统一的智能湖仓架构。其中的基本思路,就是提供一套统一的通用存储,无需运行提取、转换和加载(ETL)流程就能选择原始数据,再以合适的形式存储在数据仓库内以方便使用。总体来看,这就像是在数据湖内又建立了一个虚拟数据仓库。
戴尔ISG解决方案营销总监Chhandomay Mandal还专门为此撰写博文,表示“传统数据管理系统,例如数据仓库,几十年来一直负责存储结构化数据以供分析使用。但数据仓库在设计上无法承载体量愈发庞大的数据集合。戴尔此次设计的参考架构使用第三方合作伙伴的软件,配合自家服务器、存储和网络硬件/软件,共同建立起数据湖/智能湖仓。这套方案能够直接支持文本、图像、视频、物联网等多种数据,还支持需要直接访问数据的人工智能与机器学习算法。”
他提到,“如今,很多组织已经将数据湖与数据仓库结合使用——将数据存储在湖内,之后再复制到仓库里以降低访问难度。但这无疑增加了分析环境的复杂性和使用成本。”
最好能在单一平台上解决所有需求。而戴尔Data Lakehouse提供的分析验证设计能够直接支持商务智能(BI)、分析、实时数据应用、数据科学及机器学习。这套方案基于PowerEdge服务器、PowerScale块/文件统一存储阵列、ECS对象存储及PowerSwitch网络。该系统可以安装在本地或托管设施当中。
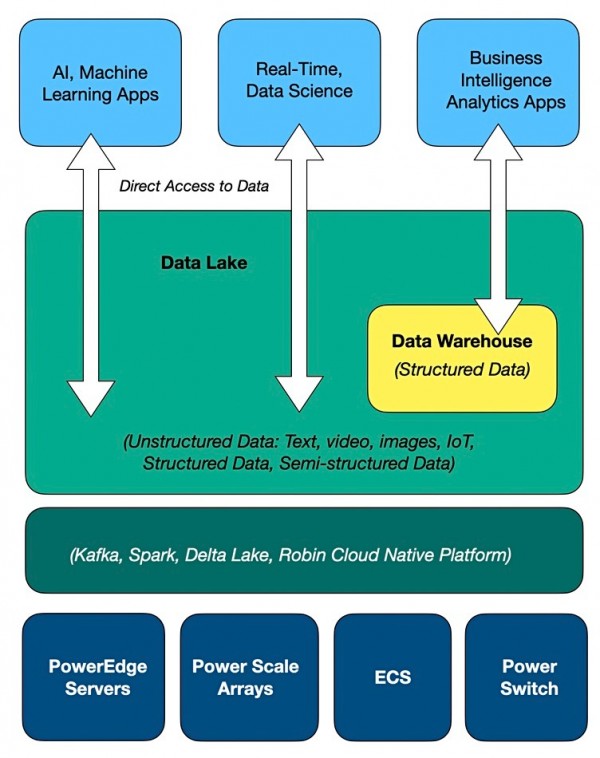
块/文件存储示意图
其中采用的软件技术包括Robin Cloud Native Platform、Apache Spark(开源分析引擎)、Kafka(开源分布式事件流平台)以及Delta Lake技术。Databricks的开源Delta Lake软件以Apache Spark为基础,戴尔之前就一直在内部智能湖仓中使用。
戴尔最近还与乐天集团收购的Roin.IO及其开源Kubernetes平台开展合作。
戴尔最近宣布与Snowflake达成外部表访问协议,并表示此次Data Lakehouse智能湖仓的设计概念也用到了这一协议。据推测,未来Snowflake外部表将可以直接引用戴尔智能湖仓中的数据。
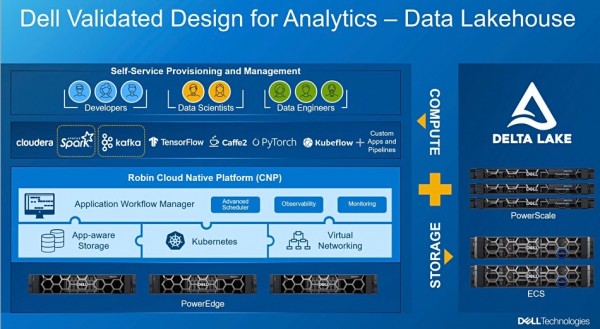
戴尔还发布了上面这张演示文稿,看起来是相当复杂。该解决方案的具体信息参见下表:
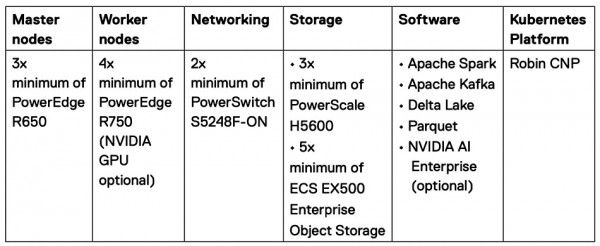
很明显,这不是那种能拿来即用的系统。在跟戴尔签订协议之前,客户还认真研究自己到底要使用哪些组件和选型。
有趣的是,HPE也推出了颇为相似的产品Ezmeral Unified Analytics,其中同样使用到Databrick的Delta Lake技术、Apache Spark和Kubernetes。HPE本周将举办Discover活动,预计届时将发布更多消息。从这个角度看,戴尔好像是故意要抢先一步。
来源:至顶网存储频道
好文章,需要你的鼓励


WordPress实验性AI开发工具Telex已投入实际应用
WordPress实验性AI开发工具Telex在9月发布几个月后已投入实际使用。在"State of the Word"年度活动中,WordPress联合创始人展示了Telex的多个应用案例,包括创建价格比较工具、价格计算器和实时营业时间显示等功能。该工具能够生成Gutenberg模块,让开发者在几秒内完成过去需要数千美元定制开发的功能。同时WordPress还推出了Abilities API等AI架构开发。

印度学者创新卫星图像识别:不靠“前人经验“也能达到97%准确率的新方法
印度学者在卫星图像识别领域取得突破,设计出无需预训练的神经网络架构,在EuroSAT数据集上达到97.23%准确率。通过三轮迭代优化,研究者发现卫星图像需要平衡空间和光谱两种特征,创新性地开发了可学习融合参数的双路径注意力机制。该方法证明了专用架构设计在特定领域的巨大潜力,为无法获得大规模预训练数据的应用场景提供了有效解决方案。

英国NCSC与BT联手阻止10亿次网络威胁攻击
英国国家网络安全中心与BT合作推出的Share and Defend服务成功拦截了近十亿次早期网络攻击和用户访问危险网站的尝试。该服务整合多方威胁情报数据,通过互联网服务商的DNS平台实时过滤恶意网站,大规模阻断钓鱼和虚假购物网站。目前已有TalkTalk、沃达丰等多家合作伙伴加入,政府计划在2026年1月发布国家网络行动计划以进一步提升英国网络安全防护能力。

UC伯克利团队:让AI更懂人心的秘密武器——从社交媒体学习用户真正想要什么
UC伯克利研究团队开发了ECHO框架,通过分析社交媒体上真实用户对GPT-4o图像生成的使用反馈,构建了更贴近实际需求的AI评测体系。该框架收集了超过31000个用户提示词,发现传统评测无法覆盖的复杂任务需求,并识别出用户关心的色彩偏移、身份保持等具体问题,为AI模型评估提供了全新的用户导向思路。

