
英特尔存储业务高速增长:傲腾技术发挥关键作用 原创
当今世界正在以惊人的速度产生数据,从这些数据中获取价值的能力将是决定成败的关键。基于此,英特尔公司的战略转向“以数据为中心”,构建了以数据为中心的“三驾马车”,进行了从云到网络到边缘的全面布局,从传输、存储和处理三个维度真正驱动以数据为中心的未来。
在赋能用户存储更多数据方面,英特尔提出了“数据存储金字塔”(亦称内存和存储层级)的战略模式,并通过傲腾技术 + 3D NAND存储技术组合拳的形式,实现了内存和存储业务的高速增长。如今,内存和存储已成为与英特尔处理器业务同等重要的产品线,最新数据显示,2020年Q1英特尔的存储业务销售额同比增长46%。
2020年6月,英特尔公司非易失性存储解决方案事业部副总裁,兼数据中心傲腾存储事业部总经理David Tuhy在英特尔内存和存储业务发展的最新进展线上活动中表示,2020年Q1的市场成绩之所以如此突出,傲腾存储技术起到了关键的作用。“相对内存来讲,DRAM并没有按照摩尔定律的成本/性能进行演进。相对存储来说,我们看到即便是最先进的产品——NAND SSD也开始放慢其性能增长的速度,所以基于3D Xpoint介质的傲腾技术成为内存和存储层级内新的增长引擎,一举打破了内存和存储瓶颈,使数据更靠近计算,并弥补了DRAM以及NAND SSD在容量和性能上的不足。” David Tuhy表示。
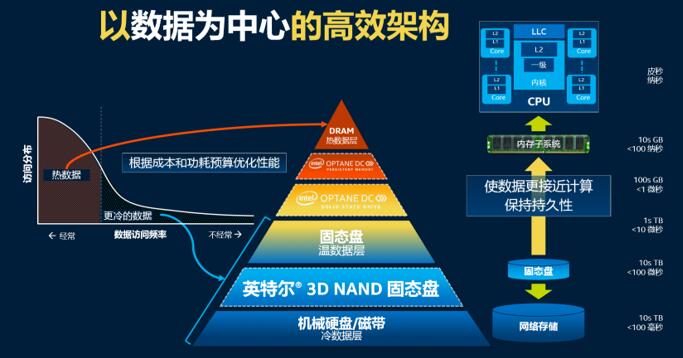
傲腾和3D NAND满足了对内存和存储层级结构中的新存储层的需求
在整个计算系统中,数据的存储金字塔一直存在瓶颈。介于内存和NAND之间的延迟、性能和容量等差距过于悬殊,让数据的价值不能有效发挥。特别是随着AI、5G、边缘计算的发展和落地,大量数据需要实时分析才能发挥数据的价值,这些需求凸显了目前在内存存储层级结构中存在的一大空白——其中,DRAM容量不够大,固态盘速度又不够快。所以英特尔提出的“数据存储金字塔”概念,并推出傲腾战略来弥补这一空白。籍此,介于DRAM和3D NAND之间的新技术——英特尔傲腾持久内存将大有作为。

目前,英特尔正在努力让傲腾持久内存在几乎所有的数据库里得到使用,并根据不同的应用和不同的数据库形式,进行大量的开发和优化。
据英特尔公司数据中心事业部产品管理高级总监Kristie Mann表示,“傲腾持久内存自发布以来,发展势头十分强劲,目前已有85%以上的概念验证转化成实际的应用部署,产生了超过200次的概念验证,同时也在诸多世界500强企业、云服务提供商以及OEM厂商和新兴服务提供商等中得到部署。”
比如说Oracle的数据库Exadata X8M应用英特尔傲腾数据中心级持久内存,在于Exadata采用复杂的远程直接内存访问(RDMA)技术,使数据库能够直接访问部署在智能共享存储服务器中的持久内存,从而绕过整个操作系统、网络和IO软件堆栈。与之前的Exadata版本相比,这可将Exadata X8M中的IO延迟减少十倍。
百度用于支持其基于云的信息流服务中的数据存储和信息检索的“Feed-Cube”的高级内存数据库,通过部署英特尔傲腾数据中心级持久内存和第二代英特尔® 至强®可扩展处理器,百度能够确保Feed-Cube的高并发性、大容量和高性能,同时降低总体拥有成本(TCO)。
百度推荐技术架构部主任架构师汪瑫表示:“通过在Feed-Cube数据库中采用英特尔傲腾数据中心级持久内存,百度能够节省成本效率,扩展内存容量,并始终能够帮助我们的信息流服务发展。”
同时在沟通会上英特尔发言人也透露代号为“Barlow Pass”的第二代英特尔傲腾数据中心级持久内存,代号为“Alderstream”的基于PCIe 4.0的第二代英特尔傲腾固态盘和用于数据中心级固态盘的144层QLC(四级单元)NAND产品也将也将于2020年下半年陆续推出。
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2020
06/22
13:48
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
