
打造AI as a Service新解决方案,看金山云携手英特尔释放平台新潜能 原创
随着AI技术高速发展,如何充分利用AI在公有云上搭建更高效的技术框架,显著加速AI运算过程,成为摆在大多数企业级用户面前的难题。随着金山云、英特尔共同打造的AI as a Service新解决方案“惊喜出现”,用户不仅可以充分发挥软硬件的优势,获得更高效的运行效率,还有效降低成本,并为更多终端用户,包括AI初创型企业提供了开放性选择。
大数据和人工智能技术的发展,越来越多的企业针对图片识别、人脸识别等AI应用选择了公有云上的AI应用。针对客户的不同需求,目前公有云会提供一个通用的深度学习平台,以Tensorflow、Caffe、MxNet等主流深度学习框架为基础,通过与Kubernetes和Docker容器技术相结合,为用户提供模型开发、模型训练、模型部署等一站式深度学习服务。
目前公有云上部署的AI技术和框架,主要的问题是以传统的云主机方式来运行深度学习等框架,即使在公有云上安装了TensorFlow、Caffe等深度学习框架,但是公有云服务商并没有去深度优化这个框架,这就造成了虽然用户购买了性能很好的云主机,但是运行起来Tensorflow、Caffe、MxNet等主流深度学习框架的时候效率并不算高。
可以看到,针对AI增强这类新的云服务模式,还需要基于底层架构进行优化,从而释放云主机的潜力。金山云作为英特尔长期的合作伙伴,拥有完备的云计算基础架构和运营体系。目前,金山云正在针对AI应用联合英特尔从底层架构对云主机进行优化,打造AI as a Service新解决方案,针对金山云三代云主机的镜像,一方面针对英特尔至强可扩展处理器优化过的TensorFlow和Caffe,通过调用Intel MKL-DNN来更好地使用英特尔AVX-512指令集,显著加速AI运算过程,尤其是加速深度学习的推理过程。同时使用该镜像用户可以免去下载、安装和配置的繁琐步骤,直接得到在英特尔至强可扩展处理器上的最佳运行性能。
将英特尔优化过的开源框架放入企业的至强服务器上面,可以充分发挥软硬件的优势,而且这样一种增强型的IaaS方式也给了很多AI初创公司,甚至AI爱好者一个非常开放的一个选择。金山云计算研发总监杨峰表示,“使用英特尔优化过的TensorFlow、Caffe,客户就不需要在底层框架优化上多费心思,可以更关注自己业务层。未来,也可以用这种方式去推新的AI增强云服务类型。”
金山云和英特尔是如何做深度学习框架优化的?
我们知道TensorFlow是目前在AI领域使用最为广泛的深度学习开源框架,可以很好地支持AI应用较为普遍的计算机视觉、语音识别、自然语言处理等纷纷做负载。Google在Tensorflow官方网站上原生Tensorflow并没有调用MKL/MKL-DNN 来加速在CPU上的运行,因此原生Tensorflow在英特尔至强处理器上运行时性能不够理想。英特尔与Google紧密合作,将基于MKL-DNN的优化代码集成到Tensorflow中,并发布到了Tensorflow官网。
用户下载针对英特尔平台优化过的Tensorflow可以很好地利用英特尔至强处理器的AVX-512指令集加速,相对于原生的Tensorflow性能有了很大提升。
Caffe也是一个使用十分广泛的开源框架,主要是针对计算机视觉方面的应用做了针对性的开发,尤其是在国内的很多安防类企业,目前来看使用的范围还是比较广泛。
相比Tensorflow,Caffe并没有版权方面的限制,英特尔在开源网站github上面有专属的分支(https://github.com/intel/caffe),针对英特尔的x86 CPU 架构做了许多有针对性的优化,比官方版本的BVLC caffe在性能上有了大幅度的提升,在一些典型的CNN拓扑上,提升幅度达到数十倍。另外英特尔积极响应客户的需求,针对目前国内许多安防类型的企业有很多的工作负载仍然运行在Windows上,也进行了在Windows上的性能优化。
从第一代至强可扩展处理器开始,英特尔至强处理器提供了全新的AVX-512指令集,该指令可以同时处理16个单精浮点数,比上一代至强处理器处理单精浮点数的能力提升2倍,这个特性在处理人工智能这种高密度计算的工作负载时展现了前所未有的优势。
AI 算法的开发基本上都是基于一些开源框架进行的,如TensorFlow, Caffe, MxNet等。为了能够将底层的硬件计算力全部释放,英特尔针对这些开源框架做了大量的优化工作,其中非常关键的一点是通过调用英特尔数学核心库(MKL/MKL-DNN)很好的利用到了英特尔处理器的AVX-512指令集。
通过测试,优化之后性能明显提升
如下测试数据是在金山云N3实例上进行测试获得的。测试使用三台VM:
VM1(蓝色):24vCPU,安装默认版本的TensorFLow和Caffe;
VM2(橙色):24vCPU,安装优化版本的TensorFLow和Caffe;
VM3(灰色):16vCPU,安装优化版本的TensorFLow和Caffe。
首先对比优化版本的TensorFlow和Google默认版本的TensorFlow的性能。在不同配置的三个VM中,分别运行如下测试case。
(1)运行batch size为1的resnet50 inference
(2)运行batch size为1的inception3 inference
(3)运行batch size为1的ssd_mobilenet inference
(4)运行batch size为256的wide_deep 测试,测试基于 movielens-1M数据集
测试结果如下图所示,可以看到优化后的TensorFlow有了很大程度的性能提升。
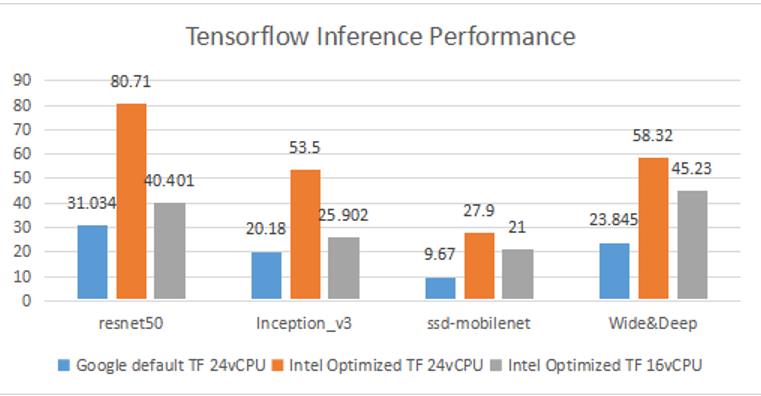
图 1 TensorFlow性能对比测试
对比Intel Caffe和默认版本Caffe的性能,在不同配置的三个VM中,分别运行如下测试case:
运行batch size为1的resnet50前向传播测试
运行batch size为1的inception3前向传播测试
运行batch size为1的ssd-mobilenet前向传播测试
运行batch size为1的resnext50前向传播测试
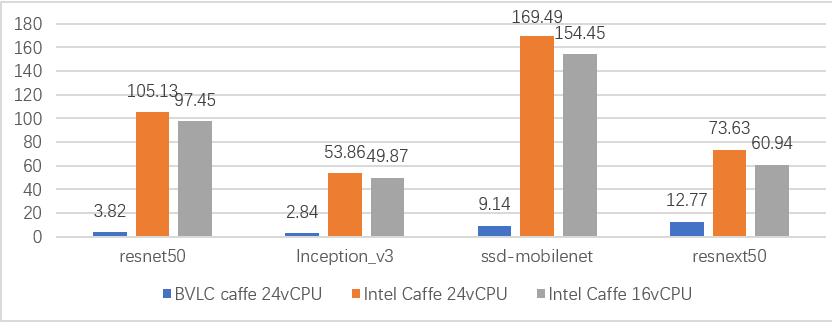
图 2 Caffe性能对比测试
基于AI as a service新解决方案的云主机更强、更省成本
经过对比实验,如果只升级硬件不升级框架的话,那个性能的提升实际上是很小的,纯粹就是硬件一个正常的线性的提升,可能计算能力提升50%,测出来性能也是提升50%。
“但基于AI as a service新解决方案则不同,相当于把框架做一个深入的优化之后,最后跑下来的性能可能提升了很多倍,那客户就很满意,比如原来他需要租10台机器干这个事,现在租1台机器就完全满足了。对于客户来讲,第一节省了成本,第二体验好了。” 杨峰谈到。
比如以前做人脸识别延时比较高,现在不仅吞吐量提升,延时也降低,在成本下降的同时,提高了效率,最终为客户提供的服务质量也是提升的。
最后可以看到基于AI能力的用户应用,不仅需要训练出一个更好的模型,同时这个要保证模型跑在硬件上、框架上、性能上等方面全方位进行提升。此次金山云与英特尔的联合创新推出的AI as a service新解决方案,可以说是为AI增强解决方案提供了新的开端,持续加速技术创新和应用落地,从而深入挖掘、释放平台能力,助力企业发展和数字化转型。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

华南理工大学与西湖大学联手破解3D场景生成难题:让AI真正“站在你的角度“看世界
CGGS是华南理工大学与西湖大学联合提出的以自我为中心三维场景生成框架,通过一致性增强多视角扩散模型、光流深度估计和互信息几何优化,实现高保真文本驱动3D场景生成。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

南加州大学团队揭示:AI抑郁症检测中藏着一个让准确率虚高23%的“致命漏洞“
南加州大学团队发现语音抑郁检测领域存在数据漏洞,并提出CLeaD跨语言对比对齐框架,揭示模型规模越大跨语言性能越差的反直觉规律。
2019
07/12
11:55
分享
点赞

Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
Apple芯片现不可修复漏洞,或成iPhone越狱突破口
