
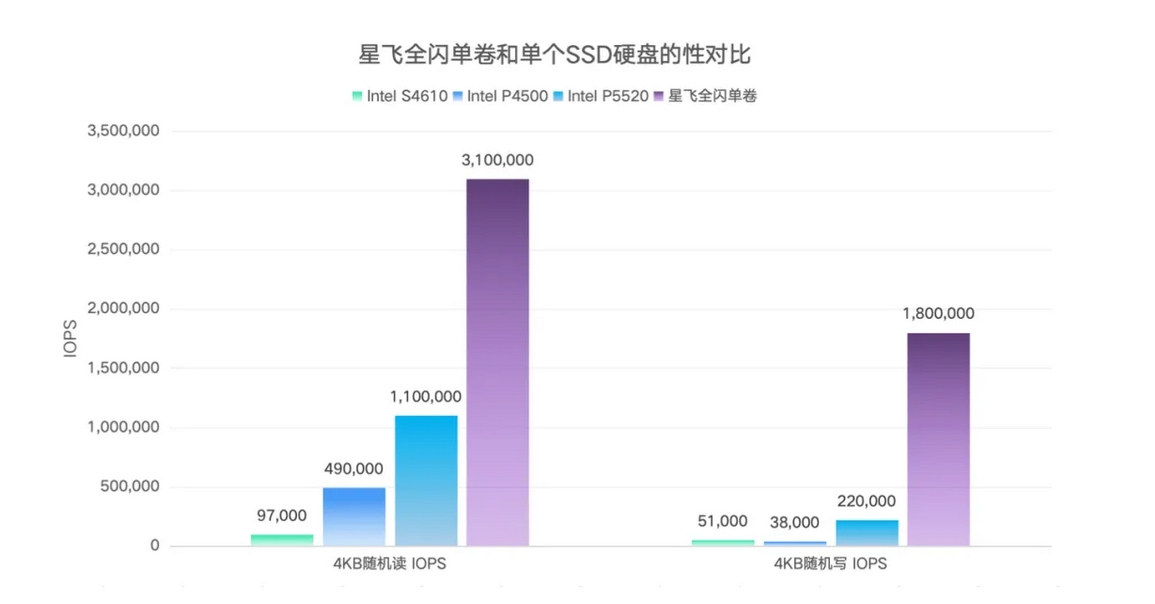
黑神话,XSKY 星飞全闪单卷性能突破310万
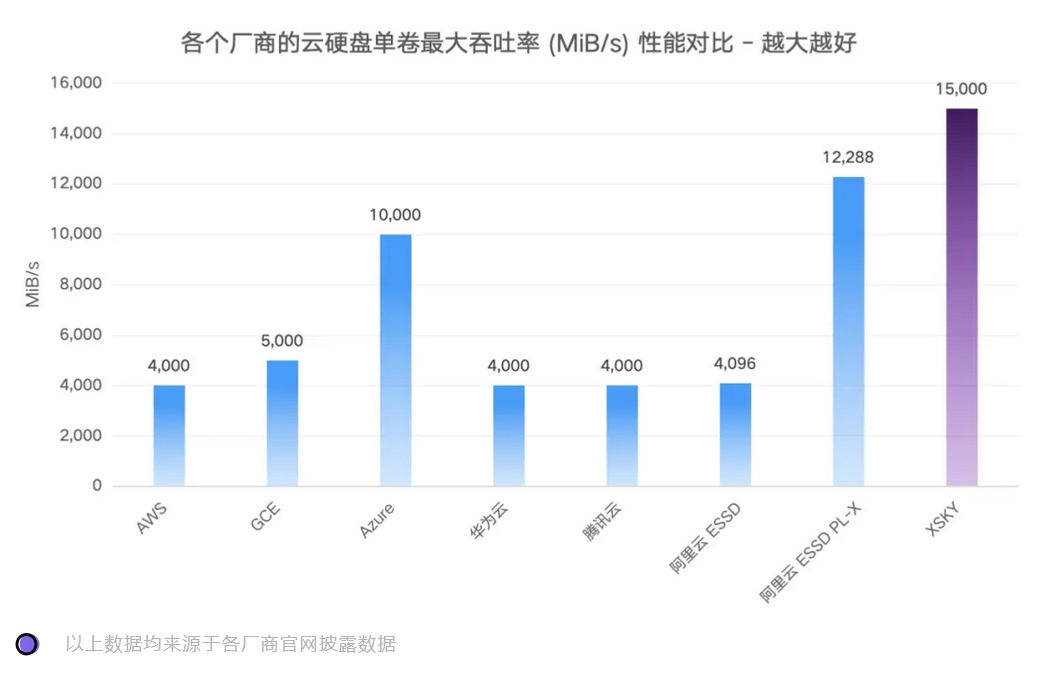
在吞吐率方面,星飞全闪同样表现优异,其单卷的最大吞吐率能够达到 15,000MiB/s,是华为云极速型 SSDV2 的 3.75 倍,是阿里云 ESSD 的 3.66 倍。
为什么需要“单卷”性能?
01
02
对于某些应用,可能对特定数据的访问和处理有较高的要求。如果单个卷性能不佳,可能导致依赖该卷的应用出现明显的延迟、卡顿,影响应用的响应速度和效率。例如:
- 在线事务处理(OLTP)应用:如关系型数据库(MySQL、Oracle、Postgre 等)。这些应用通常需要频繁地读写数据,对存储的响应时间和 IOPS 要求较高。特别是对于关键的交易处理或数据查询操作,如果单个卷性能不足,可能导致查询延迟增加,交易处理时间延长,从而影响业务的正常进行;
- 虚拟化/云环境:在服务器虚拟化/云场景中,多个虚拟机可能共享存储资源。某些对性能敏感的虚拟机,例如承载关键业务服务的虚拟机,其数据所在的单卷性能至关重要。单个卷性能不佳可能导致虚拟机运行缓慢,影响整个虚拟环境的稳定性和性能。
因此,对应用来说,如果单个卷不能满足应用的性能需求,即使整个集群性能看起来不错,该应用的运行仍可能受到严重影响,导致用户体验下降,甚至业务流程受阻。
哪些应用能驾驭单卷310万性能?
- AIGC:高性能训练和推理场景;
- KV 键值存储:如 RocksDB、Etcd 等,KV 存储业务常以串行 I/O 模式落盘,对每个 I/O 处理时延要求极高,单并发时延决定了系统的整体性能。星飞全闪块存储提供 100us 的时延表现;
- 中间件:如 Redis、Kafka;
- 大型 OLTP 数据库:支持千万级行表级别的 MySQL、Oracle、PostgreSQL、SQL Server 等中大型关系数据库应用;
- 大型 NoSQL:满足 HBase、Cassandra、MongoDB 等 NoSQL 业务对存储的性能要求;
- OLAP 数据库:Clickhouse、Greenplum;
- ElasticSearch:满足 ES 对存储低时延的性能要求;
- 大数据分析:提供针对 TB、PB 级数据的分布式处理能力,适用于数据分析、挖掘、商业智能等领域;
- 核心业务系统:对数据可靠性要求高的 I/O 密集型等核心业务系统。
除了满足应用性能要求
企业级存储系统还有哪些优势?
01
目前仍有很多用户在众多分布式数据库场景中使用本地硬盘,但是这种方案的弊端很多:
- TCO 居高不下:基于本地 SSD 的服务器集群中的存储容量和性能利用率不均衡,资源浪费严重;
- 运维管理困难:服务器本地盘数量众多,缺乏统一的硬盘管理工具,无法自动预警和处理存储介质故障和亚健康问题,导致业务受影响时间长、运维成本高;
- 无数据服务:没有快照等数据保护服务。本地盘无数据冗余保护,可靠性低。
星飞全闪单卷不仅在 TCO、可管理性、可靠性上完胜本地 SSD 硬盘,而且读性能是 SATA SSD 的 31 倍,写性能是 PCIE 4.0 NVME SSD 的 8 倍,可轻松替代本地 SSD 硬盘。
02
应用也可以用多个普通卷来提高 IOPS 性能。但是使用多个卷也存在一些缺点:
- 增加管理复杂性:使用多个卷需要更多的管理和维护工作(比如使用 LVM 和 RAID),例如需要为每个卷配置存储参数、监控性能和管理数据;
- 降低存储利用率:每个卷都会有一些额外的空间用于存储元数据和其他管理信息,因此使用多个卷可能会降低存储利用率;
- 增加成本:使用多个卷可能会增加存储成本,因为需要购买和维护更多的存储设备。
XSKY 星飞,不止当下
在存储技术领域,通过 NVMe over RoCE 技术+SPDK+硬件堆砌,虽然可以实现高 IOPS 性能,但要同时达到高性能、高可靠性(100ms 故障切换)以及高得盘率(大比例 EC 和压缩),则需要依赖于最先进的存储架构和专利技术支撑。
XSKY 凭借过去 9 年在存储产品领域积累的深厚经验和对国内外最前沿技术趋势的深入洞察,精心打造了创新的星海全闪架构。这一架构不仅能够满足当前市场对高性能、高可靠性和高得盘率的严苛要求,更具备在未来十年内保持产品竞争力领先地位的潜力。
XSKY 刚开始在测试单卷性能时候,单卷最大随机读 IOPS 只有 100 万,最大随机写 IOPS 只有 70 万,基于星海全闪架构的先进性,XSKY 的研发团队只增加了 500 行代码,就让单卷最大随机读 IOPS 提高到 310 万(提高了 2.1 倍),最大随机写 IOPS 提高到 180 万(提高了 1.5 倍)。这足以证明星海全闪架构能够游刃有余地处理各种性能问题。
我们相信,在未来面对 256 核 CPU、400Gb/800Gb 网络、 PCIE 6.0 NVME 新硬件时,星海全闪架构也能够完美适配,充分释放硬件潜能,为用户带来更卓越的性能体验,为业务提供更全面、更可靠的支持。

好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2024
08/28
11:43
分享
点赞

GPU 云服务运营商 CoreWeave 申请上市
IBM 完成 64 亿美元收购 HashiCorp 交易,监管审批已获通过
AI 优化公有云服务商 Together AI 完成 3.05 亿美元融资
Azure Files 磁盘存储引入类似 SSD 的预配置计费模式
Kelsey Hightower 谈 AI 热潮回避及 IT 术语词汇表的必要性
Gartner:中国企业弥合基础设施和运营内部云技能差距的三大举措
Informatica 因收入未达预期股价暴跌 33%,称存在"内部问题"但强调基本面依然稳健
Amazon 在新加坡开设亚太总部
AI 热潮推动云计算增长,但三大云服务商面临产能限制
AWS 全年利润和收入增长,AI 和公有云需求飙升
