
IBM Storage Scale被采用于Blue Vela AI超级计算机
IBM的Vela AI超级计算机功能已经不足以满足IBM研究院的AI训练需求。于是2023年开始研发的Blue Vela旨在满足GPU计算能力方面的重大扩展,用以支持AI模型训练需求。截至目前,Blue Vela正被积极用于运行Granite模型训练作业。

IBM Blue Vela示意图。
Blue Vela基于英伟达的SuperPod概念打造,并采用IBM自家的Storage Scale设备。
Vela被托管在IBM Cloud之上,但Blue Vela集群则托管在IBM研究院的本地数据中心当中。这意味着IBM研究院拥有全部系统组件的所有权及责任,涵盖从基础设施层到软件技术栈的整个体系。
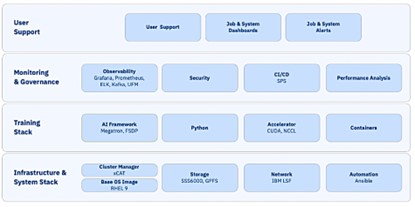
Blue Vela系统中的各层。
随着训练体量更大、连接更紧密的模型所需要的GPU数量的增长,通信延迟成为影响结果的关键瓶颈。因此,Blue Vela的设计从网络起步,围绕四种不同专用网络构建而成。
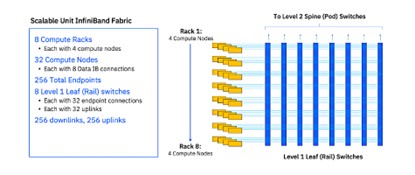
- 计算InfiniBand结构,促进GPU到GPU之间的通信,如下所示;
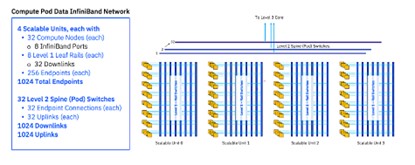
- 存储InfiniBand结构,提供对各存储子系统的访问,如下所示;
- 带内以太网主机网络,用于计算结构外部各节点间的通信;
- 带外网络(也称管理网络),提供对服务器和交换机上的管理接口的访问。
Blue Vela基于英伟达的SuperPod参考架构。其采用128节点计算Pod,其中包含4个可扩展单元,每单元又包含32个节点。这些节点均采用英伟达H100 GPU。英伟达的Unified Fabric Manager统一结构管理器(FCM)则用于管理由计算和存储结构组成的InfiniBand网络。该管理器有助于识别并解决单个GPU限流或者不可用问题,而且无法兼容以太网网络。
各计算节点基于戴尔PowerEdge XE9680服务器,具体组成包括:
- 双48核第四代Gen英特尔至强Scalable处理器;
- 八英伟达H100 GPU加80 GB高带宽内存(HBM);
- 2 TB RAM;
- 十英伟达ConnectX-7 NDR 400 Gbps InfiniBand主机通信适配器(HCA);
-其中八个专用于计算结构;
-两个专用于存储结构
- 八块4 TB Enterprise NVMe U.2 Gen4 SSD;
- 双25G以太网主机链路;
- 1G管理以太网端口。
IBM“修改了标准存储结构配置,旨在集成IBM新的Storage Scale System(SSS)6000,我们自己也成为首家部署该系统的公司。”
这些SSS设备属于集成化的纵向/横向扩展存储系统,可容纳1000台设备,且安装有Storage Scale。其支持自动、透明的数据缓存以加快查询速度。
每个SSS 6000设备均可通过其InfiniBand和PCI Gen 5互连提供高达310 GBps的读取吞吐量及155 GBps的写入吞吐量。Blue Vela最初拥有两个满配SSS 6000机箱,每机箱配备48 x 30 TB U.2 G4 NVMe驱动器,可提供近3 PB的原始存储容量。每台SSS设备最多可额外再容纳七个外部JBOD机箱,每机箱最多可提供22 TB的容量扩展。此外,Blue Vela结构最多可容纳32台SSS 6000设备。
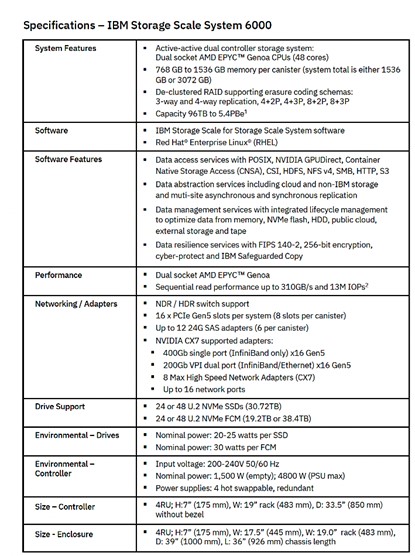
IBM表示,基于FCM驱动器及3:1压缩比率,其最大有效容量可高达5.4 PB,具体取决于存储在FCM当中的数据特性。
Blue Vela使用戴尔PowerEdge R760XS服务器以建立单独的管理节点,可用于运行身份验证与授权、工作负载调度、可观察性及安全性等服务。
在性能方面,论文作者表示“从一开始,这套基础设施也表现出了良好的吞吐量潜力。与同等配置的其他环境相比,其开箱即用性能提高了5%。”
“集群的当前性能显示出良好的吞吐量水平(每天90至321B,具体取决于训练设置与实际训练的模型)。”
Blue Vela性能统计。
IBM研究论文中列出了关于Blue Vela数据中心设计、管理功能以及软件堆栈的更多详细信息,感兴趣的朋友可以点击此处(https://arxiv.org/abs/2407.05467)查看。
来源:至顶网存储频道
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2024
08/06
14:50
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
