
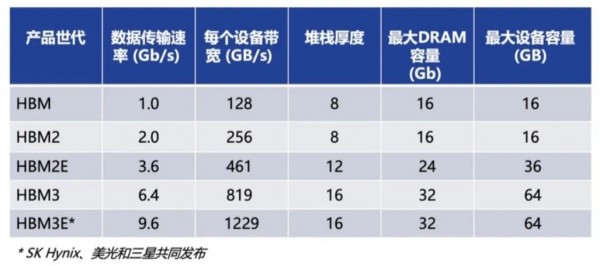
HBM、HBM2、HBM3和HBM3e技术对比
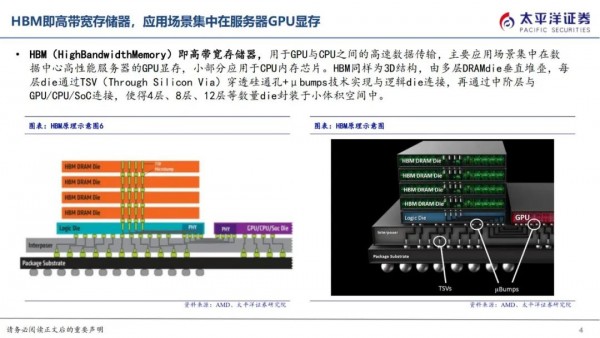
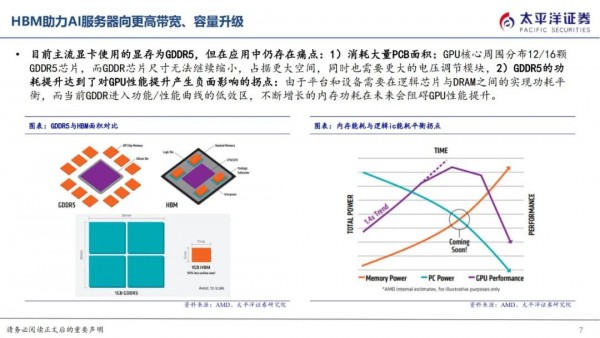
HBM即高带宽存储,由多层DRAM Die垂直堆叠,每层Die通过TSV穿透硅通孔技术实现与逻辑Die连接,使得8层、12层Die封装于小体积空间中,从而实现小尺寸于高带宽、高传输速度的兼容,成为高性能AI服务器GPU显存的主流解决方案。
目前迭代至HBM3的扩展版本HBM3E,提供高达8Gbps的传输速度和16GB内存,由SK海力士率先发布,将于2024年量。
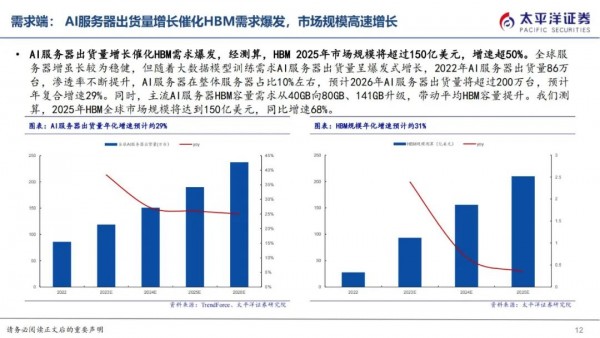
HBM主要应用场景为AI服务器,最新一代HBM3e搭载于英伟达2023年发布的H200。根据Trendforce数据,2022年AI服务器出货量86万台,预计2026年AI服务器出货量将超过200万台,年复合增速29%。
AI服务器出货量增长催化HBM需求爆发,且伴随服务器平均HBM容量增加,经测算,预期25年市场规模约150亿美元,增速超过50%。
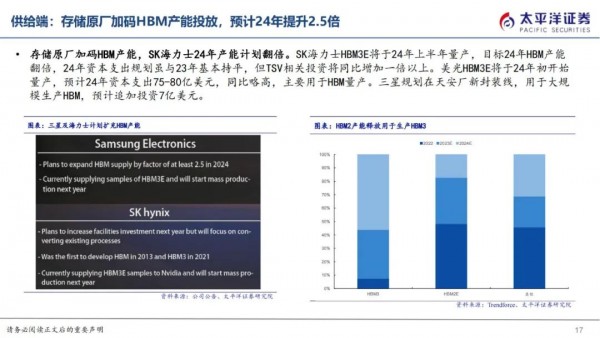
HBM供给厂商主要聚集在SK海力士、三星、美光三大存储原厂,根据Trendforce数据,2023年SK海力士市占率预计为53%,三星市占率38%、美光市占率9%。HBM在工艺上的变化主要在CoWoS和TSV。
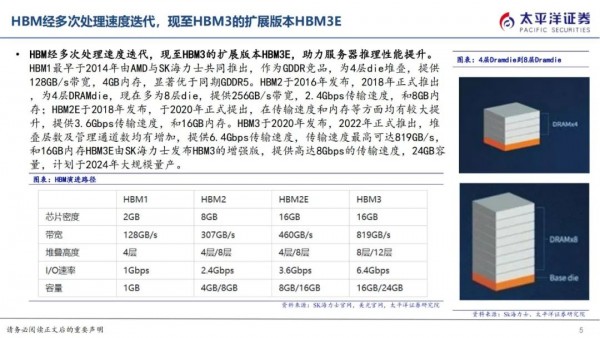
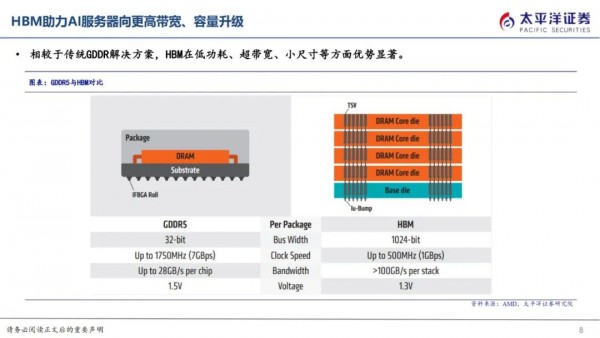
HBM1最早于2014年由AMD与SK海力士共同推出,作为GDDR竞品,为4层die堆叠,提供128GB/s带宽,4GB内存,显著优于同期GDDR5。
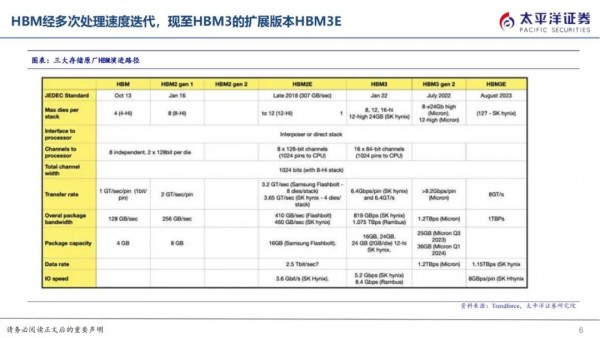
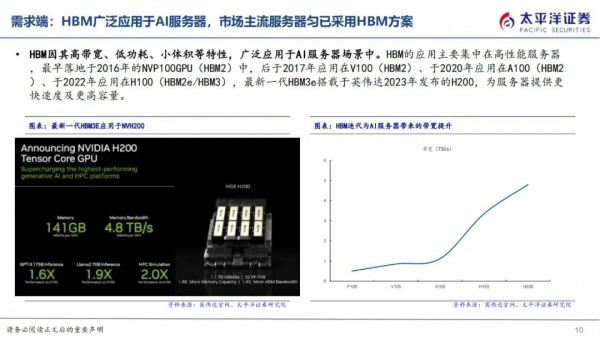
HBM因其高带宽、低功耗、小体积等特性,广泛应用于AI服务器场景中。HBM的应用主要集中在高性能服务器,最早落地于2016年的NVP100GPU(HBM2)中,后于2017年应用在V100(HBM2)、于2020年应用在A100(HBM2)、于2022年应用在H100(HBM2e/HBM3),最新一代HBM3e搭载于英伟达2023年发布的H200,为服务器提供更快速度及更高容量。
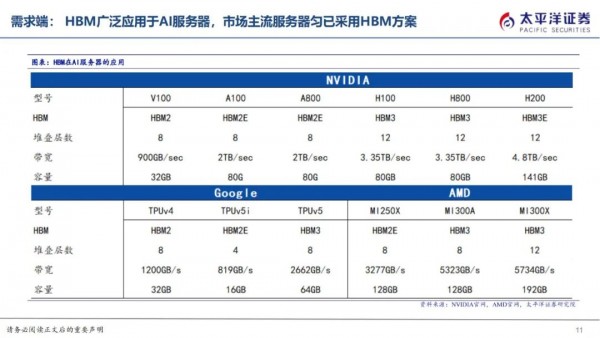
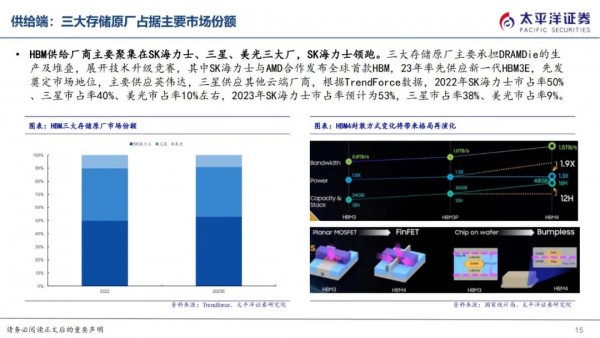
HBM供给厂商主要聚集在SK海力士、三星、美光三大厂,SK海力士领跑。三大存储原厂主要承担DRAMDie的生产及堆叠,展开技术升级竞赛,其中SK海力士与AMD合作发布全球首款HBM,23年率先供应新一代HBM3E,先发奠定市场地位,主要供应英伟达,三星供应其他云端厂商,根据TrendForce数据,2022年SK海力士市占率50%、三星市占率40%、美光市占率10%左右,2023年SK海力士市占率预计为53%,三星市占率38%、美光市占率9%。
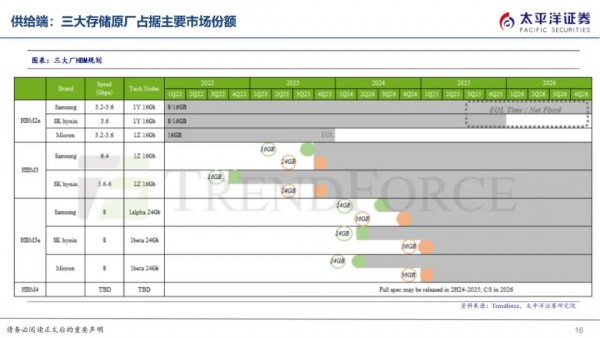
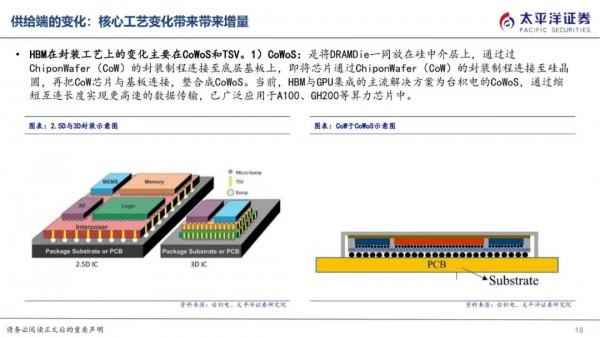
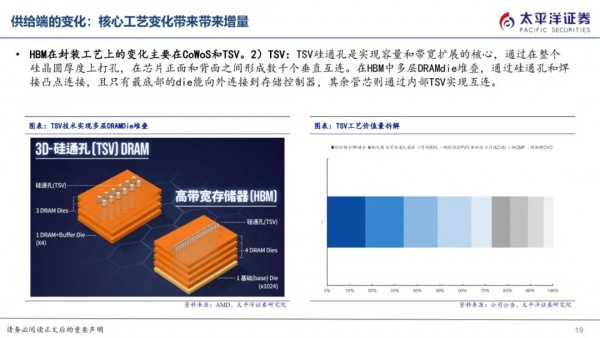
HBM在封装工艺上的变化主要在CoWoS和TSV。
1)CoWoS:是将DRAMDie一同放在硅中介层上,通过过ChiponWafer(CoW)的封装制程连接至底层基板上,即将芯片通过ChiponWafer(CoW)的封装制程连接至硅晶圆,再把CoW芯片与基板连接,整合成CoWoS。当前,HBM与GPU集成的主流解决方案为台积电的CoWoS,通过缩短互连长度实现更高速的数据传输,已广泛应用于A100、GH200等算力芯片中。
2)TSV:TSV硅通孔是实现容量和带宽扩展的核心,通过在整个硅晶圆厚度上打孔,在芯片正面和背面之间形成数千个垂直互连。在HBM中多层DRAMdie堆叠,通过硅通孔和焊接凸点连接,且只有最底部的die能向外连接到存储控制器,其余管芯则通过内部TSV实现互连。
好文章,需要你的鼓励


HPE Unix系统HP-UX正式终结42年历史
HPE旗下Unix系统HP-UX 11i v3最终版本已于去年底结束支持,标志着这一始于1982年的操作系统产品线正式终结。该系统经历了从HP FOCUS处理器到摩托罗拉68000,再到PA-RISC架构的演进历程。最后几个版本仅支持英特尔安腾处理器,随着2021年安腾处理器停产,HP-UX失去硬件支撑而走向终结。

UCSD团队打造终极仿真世界:让AI智能体在虚拟城市中自立更生的惊人实验
SimWorld是由UCSD等多所顶尖院校联合开发的革命性AI仿真平台,基于虚幻引擎5构建了具备真实物理规律的虚拟城市环境。该平台支持无限扩展的程序化世界生成和自然语言交互,让AI智能体能够在复杂环境中学会生存、合作和竞争,为通用人工智能的发展提供了前所未有的训练平台。

AI基础设施革命:2026年数据中心发展预测
AI正成为数据中心行业最具颠覆性的力量。2025年AI加剧了电力危机,代理AI技术进一步推高了数据中心需求,AWS和Cloudflare等大型服务商的重大故障凸显了基础设施韧性的重要性。展望2026年,液冷系统将加速普及,AI基础设施监管将趋严,边缘AI部署增长,量子-AI融合准备启动,现场电源投资将增加,这些趋势将持续重塑数据中心行业格局。

浙江大学团队提出C2DLM:让AI推理更像人类思维的全新语言模型
浙江大学联合华为提出C2DLM,这是一种因果概念引导的扩散语言模型,通过自动提取因果关系并融入注意力机制来增强AI推理能力。相比传统方法,C2DLM在推理任务上平均提升1.31%-12%,训练效率提高3.2倍,为解决语言模型推理能力不足开辟了新路径。
2024
03/01
20:04
分享
点赞

