
AMD年终大秀:MI300正面挑战英伟达,Lisa Su首谈AI三大战略
当地时间12月6日,在圣何塞举办的AMD Advancing AI活动上,AMD CEO Lisa Su释出重磅消息,为强劲的年终业绩画上一串惊叹号:盛传许久的MI300发布;终于兑现E级APU承诺;在ROCm软件领域取得显著进步,硬刚CUDA的薄弱环节继续得以强化。
随着生成式AI的快速发展,全球高性能计算需求不断增加,进一步推动了AI芯片的激烈竞争。以微软、Meta为首的大型云厂商也在寻求自研AI芯片或支持新的供应商,来降低对英伟达的依赖。AMD MI300 推出后,微软、Meta就在首批客户之列。
MI300两大系列:MI300X大型GPU、MI300A数据中心APU
在英伟达占据绝对地位的AI芯片领域中,AMD是为数不多具备可训练和部署AI的高端GPU公司之一,业界将其定位为生成式AI和大规模AI系统的可靠替代者。AMD与英伟达展开竞争的战略之一,就包括功能强大的MI300系列加速芯片。当前,AMD 正在通过更强大的 GPU、以及创新的CPU+GPU平台直接挑战英伟达H100的主导地位。
Lisa Su在开场演讲中谈到,包括GPU、FPGA等在内的数据中心加速芯片,未来四年每年将以50%以上的速度增长,从2023年的300亿市场规模,到2027年将超过1500亿。她表示,从业多年,这种创新速度比她以往见到的任何技术都快。

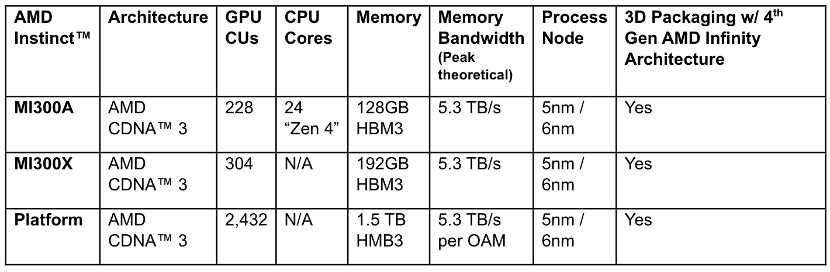
最新发布的MI300目前包括两大系列,MI300X系列是一款大型GPU,拥有领先的生成式AI所需的内存带宽、大语言模型所需的训练和推理性能;MI300A系列集成CPU+GPU,基于最新的CDNA 3架构和Zen 4 CPU,可以为HPC和AI工作负载提供突破性能。毫无疑问,MI300不仅仅是新一代AI加速芯片,也是AMD对下一代高性能计算的愿景。
生成式AI领域,MI300X正面挑战英伟达
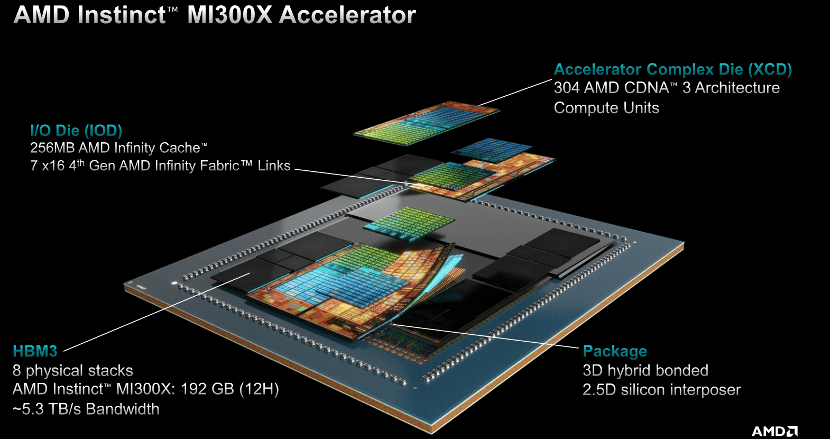
AMD MI300X 拥有最多 8 个 XCD 核心,304 组 CU 单元,8 组 HBM3 核心,内存容量最大可达 192GB,相当于英伟达H100(80GB)的2.4 倍,同时HBM内存带宽高达5.3TB/s,Infinity Fabric总线带宽896GB/s。拥有大量板载内存的优点是,只需更少的GPU 来运行内存中的大模型,省去跨越更多GPU的功耗和硬件成本。
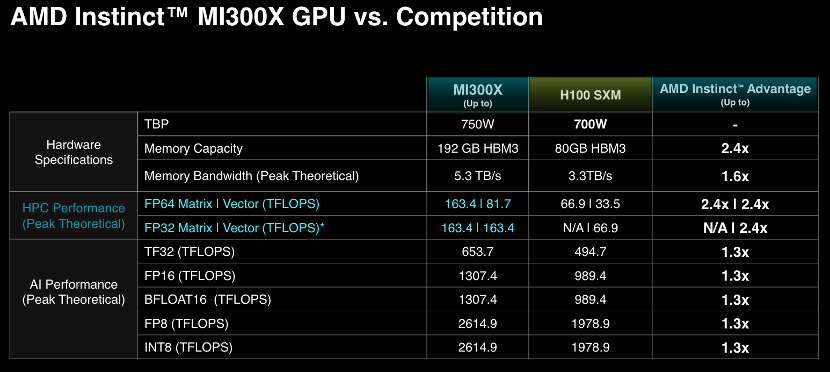
Lisa Su表示,生成式AI是有史以来要求最高的工作负载,需要成千上万的加速器来训练和完善数十亿参数的模型。它的“法则”非常简单,你拥有的计算越多,模型的能力越强,生成答案的速度就越快。
“GPU是生成式AI世界的中心。每个与我交谈的人都说,GPU计算的可用性和能力是AI采用的一个最重要的因素”,她兴奋地表示,“MI300X是我们迄今为止最先进的产品,也是业内最先进的AI加速芯片。”
Instinct平台是基于OCP标准设计的生成式AI平台,包括8个MI300X,可以提供1.5TB HBM3内存容量。与英伟达H100 HGX相比,AMD Instinct平台可以提供更高的吞吐量,例如运行176B的 BLOOM 等LLM推理时,性能提升高达 1.6 倍,并且是当前市场上唯一的能够对 70B 参数模型(如 Llama2)进行推理的方案。
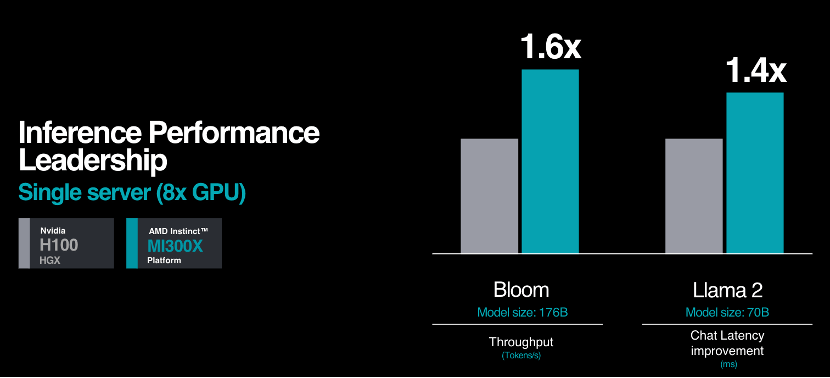
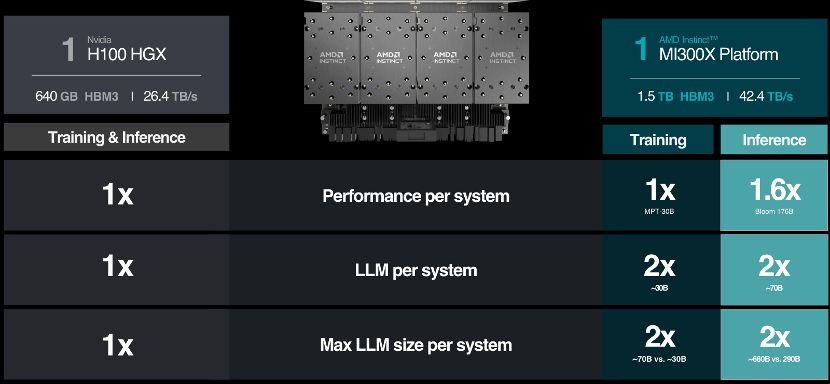
此外,AMD宣布了与微软Azure等合作,通过将尖端的AI硬件集成到领先的云平台中,也标志着当前业界人工智能应用的持续进步。而在 Azure 生态系统中引入 AMD Instinct MI300X,也进一步巩固了AMD在云端AI的市场地位。


数据中心MI300A——E级APU成为现实
MI300A 是全球首款适用于HPC和AI的数据中心APU,结合了CDNA 3 GPU内核、最新的基于AMD“Zen 4” x86的CPU内核、以及128GB HBM3 内存,通过3D封装和第四代AMD Infinity架构,可提供HPC和AI工作负载所需的性能。与上一代 AMD Instinct MI250X5 相比,运行HPC和AI工作负载,FP32每瓦性能为1.9 倍。
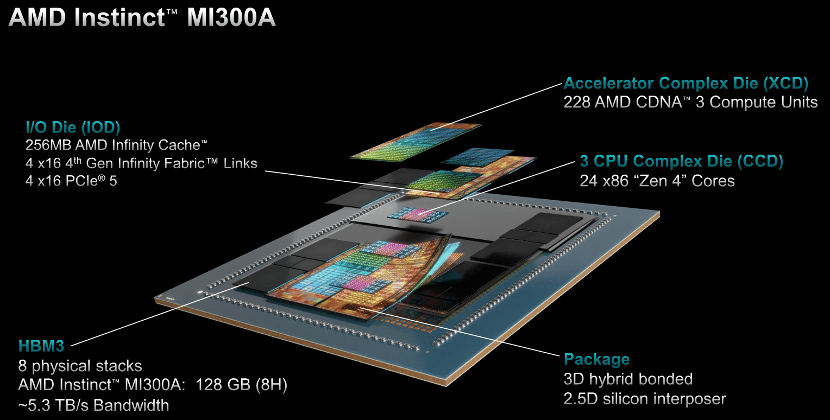
能源效率对于HPC和AI领域至关重要,因为这些应用中充斥着数据和资源极其密集的工作负载。MI300A APU将CPU和GPU核心集成在一个封装中,可提供高效的平台,同时还可提供加速最新的AI模型所需的训练性能。在AMD内部,能源效率的创新目标定位为30×25,即2020-2025年,将服务器处理器和AI加速器的能效提高30倍。

对比MI300X的8个XCD核心,MI300A采用6个XCD,从而为CCD留出空间。APU的优势意味着,它拥有统一的共享内存和缓存资源,因此省去了在CPU和GPU之间来回复制数据。切换电源时,它只需运行GPU,在CPU上运行串行部分即可,由于省去复制数据的过程,因此性能表现更好。同时也可以为客户提供易于编程的GPU平台、高性能的计算、快速的AI训练能力和良好的能源效率,能够为需求严苛的HPC和AI工作负载提供动力。

美国即将推出的新一代 2ExaFLOPS (200亿亿次)的El Capitan超算将采用AMD MI300A,这将使得El Capitan成为世界上最快的超级计算机。


AI开源软件战略持续强化
AMD 发布了最新的ROCm 6开放软件平台,也是AMD对开源社区贡献最先进的库的承诺。Lisa Su表示,ROCm 6代表AMD软件工具的重大飞跃,进一步推进了AMD开源AI软件开发的愿景。该软件平台增强了AMD的AI加速性能,在 MI300 系列加速器上运行Llama 2 文本生成时,与上一代硬件和软件相比,性能提高约8倍。
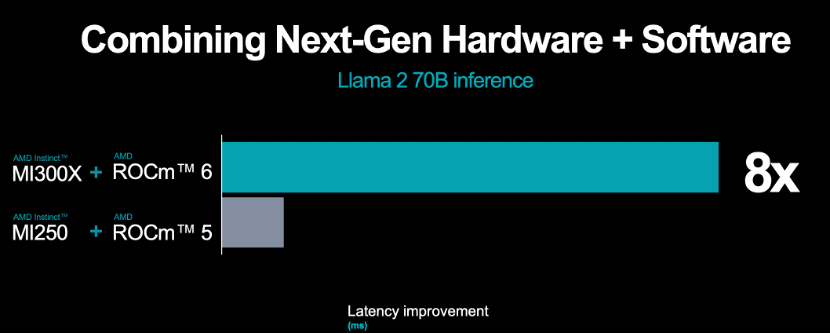
针对生成式AI,ROCm 6增加了关键功能:包括 FlashAttention、HIPGraph 和 vLLM等。 AMD正在在与软件伙伴推进合作,例如PyTorch、TensorFlow、hugging face等,打造强大的AI生态系统,简化AMD AI 解决方案的部署。
此外,AMD 还通过收购开源软件公司Nod.AI,进一步增强为AI客户提供开放软件的能力,使他们能够轻松部署针对AMD硬件调整的高性能AI模型。并且通过与Mipsology的生态系统合作等,持续强化其开源的AI软件战略。

AMD致力于建立一个开放的软件生态系统,利用广泛的开源社区基础来加快创新步伐,同时为客户提供更多的灵活性。不得不说,对标英伟达在AI领域强大的CUDA生态,此举是AMD将其自身打造为有力的AI竞争者的关键环节,也有助于AMD切入CUDA现有的市场。
三代产品演进,Lisa首谈三大AI战略
前不久,AMD在公布2023年Q3财报时,预计到 2024 年数据中心 GPU 收入将超过20 亿美元,实现大幅增长。当时,这种加速的收入预测主要取决于以AI为中心的解决方案,能够满足跨行业的各种AI工作负载的能力,这也是最新推出的MI300获得业界高度关注的一个原因。

AMD的加速芯片之旅,始于第一代基于CDNA计算架构的MI100,通过一些HPC的应用和部署,为MI200取得更广泛的商业成功铺平了道路。MI200量产出货已有几年,在大型HPC和前沿AI部署应用方面收获颇丰,并且是超级计算机500强榜单的第一名。
也正是经过这两代产品的打磨,使AMD真正对AI工作负载、软件需求等有了更深入的理解,为MI300打下了坚实基础。当前,MI300A主要专注于HPC和AI应用,是全球首个数据中心APU。MI300X则专为生成式AI而设计,通过硬件和软件全面提升,使得该产品的应用门槛进一步降低。
Lisa Su在大会上首次谈到了AMD的三大AI战略:首先,AMD始终提供通用的、高性能的、节能的GPU、CPU和用于AI训练和推理的计算方案;其次,将继续扩展开放、成熟和对开发人员友好的软件平台,使得领先的AI框架、库和模型都完全支持AMD硬件;第三,AMD将与合作伙伴扩大联合创新,包括云提供商、OEM、软件开发人员等等,实现更进一步的AI加速创新。
写在最后
AMD此次推出MI300是其发展历程中的一个重要里程碑。 通过比英伟达H100更优的一系列表现,AMD致力于成为生成式AI时代的有力竞争者。
随着重磅产品的问世,大客户合作是否会助力AMD加速追赶?AMD能否抓住AI时代机遇,复刻CPU成功之路?在高端GPU领域,英伟达已经先发制人,AMD能否成为游戏规则改变者?
短期内可以看到的是,随着英伟达明年推出H200和B100两款芯片,高端AI芯片的竞争态势继续胶着,AI加速计算有望开启新一轮超级周期。
至于AMD是否有计划开发和销售能够符合美国对华芯片出口禁令的特定版本的MI 300?就在本文发稿前,AMD方面回应:中国市场对AMD很重要,但今天没有宣布专门针对中国市场的特别产品。
来源:业界供稿
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2023
12/13
12:05
分享
点赞

AMD 发布新一代 AMD RDNA(TM) 4 架构,推出 AMD Radeon(TM) RX 9000 系列显卡
苏姿丰的十年历程回顾:AMD如何从英特尔廉价替代品成长为x86领域的有力竞争者
面临AMD及自身内部挑战,英伟达Green 500主导地位受到威胁
微软率先拿下HBM驱动的AMD CPU供货
基于 AMD 加速器的 El Capitan 首次登全球超算500强榜首
突发!AMD大爆雷!
AMD Versal家族再添新成员 ——打破AI内存桎梏 支持CXL 3.1
AMD超低时延金融加速卡 帮你跑赢高频交易“竞速赛”!
要超越英伟达,AMD还须十年时间
深度剖析:聊聊英特尔与AMD各自不同的CPU整合思路
