
存储市场新盘点:谁在赚钱,谁在亏损?
对存储供应商收入趋势的最新观察发现,闪存与硬盘厂商的业绩正在跳水,戴尔、Pure Storage及Snowflake等系统供应商的占比则逐渐崛起。
随时间推移,我们一直在关注上市存储公司的收入变化。下图所示,为变动模式的最新比照结果:
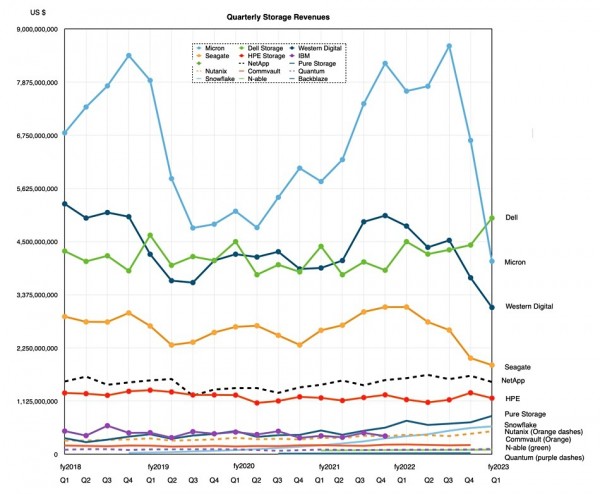
所有供应商的季度收入报告,都经过标准化处理以与HPE财年设置对齐。对于其中列出的戴尔、HPE等系统供应商,我们只关注存储部分收入。
我们的上一轮存储厂商收入趋势回顾是在2022年9月,当季度各厂商的收入增势相当强劲。但NAND供应过剩加上总体经济形势疲软,共同拉下了一季度的统计结果。其中美光收入已经不及戴尔存储业务,甚至连西部数据和希捷也被戴尔斩落马下。自2021年中以来,戴尔甚至一直保持着逆势增长的状态。
以下是重新整理的图表,其中仅列出收入高于NetApp的厂商,这样可以更明确地了解到存储领域各头部厂商的运营情况:

就存储收入而言,NetApp与HPE间的差距正逐渐拉开。有三家厂商正在向HPE靠拢,分别为Pure、Snowflake以及Nutanix,后两位本季度刚刚互换了份额排名。
在第二份图表中排名垫底的选手分别为:Commvault、Quantum、N-able以及Backblaze。
我们认为,Rubrik可能会在今年晚些时候或2024年进行首轮公开募股,Cohesity、Databricks乃至Veeam都有可能紧随其后。在上市之后,这些新秀的业绩数字也将出现在我们的统计图表当中。
来源:至顶网存储频道
好文章,需要你的鼓励


NHS App将引入AI分诊工具,助力缩短患者等待时间
英国NHS计划在NHS App中部署AI智能分诊工具,作为三年100亿英镑数字化转型计划的一部分。该工具可引导患者前往最合适的医疗服务渠道,包括全科医生、药店或急诊等。试点数据显示,早高峰电话等待人数减少29%。此外,AI语音记录工具可为临床医生节省近四分之一的行政时间。该应用将于未来12个月向约20万患者开放,并计划于2028年4月前全面推广。

当AI助手“看“电脑屏幕,就像让一个视力正常的人蒙眼操作——德克萨斯大学达拉斯分校的解法
LUMOS是一个让AI通过操作系统无障碍接口直接读取界面语义信息来操控电脑的中间层,避免依赖截图识别,降低AI电脑操作的资源消耗和出错率。

Station F加速器助力欧洲AI创业公司崛起
巴黎创业中心Station F正在筹备其F/ai加速器项目的第二批次,计划于9月启动。第一批次吸引了AMD、Anthropic、OpenAI、Meta等众多科技巨头支持,20家AI初创公司共完成3400万美元的种子前融资,并已有两支团队获得国际认可。第二批次将新增ElevenLabs、Nebius、Rippling等合作伙伴,目标是帮助初创公司在六个月内实现100万欧元收入,推动欧洲AI创业生态发展。

腾讯混元携手多所高校,让3D网格生成快如闪电——PolyFlow如何破解困扰业界多年的“拓扑难题“
腾讯混元联合多所高校提出PolyFlow,用流匹配模型并行生成艺术家风格3D网格,速度比自回归方法快百倍,几何精度达到新高。
2023
03/10
14:33
分享
点赞

Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
Day-0支持|摩尔线程完成美团LongCat-2.0极速适配
亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
微软推出Memora,致力于解决AI智能体的记忆难题
SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
特斯拉在迈阿密划定Robotaxi小范围服务区,得克萨斯扩张仍受阻
Luxonis完成1400万美元融资,为智能自动化打造视觉感知层
.NET 8 与 .NET 9 即将停止支持,微软建议升级至 .NET 10
苹果供应商塔塔电子遭黑客攻击,iPhone 18 Pro核心机密外泄
