
经济形势晦暗不明,NetApp削减成本
NetApp创下第二季度收入纪录,但面对预期客户支出减少和整体经济形势萎缩等情况,公司仍决定削减成本。
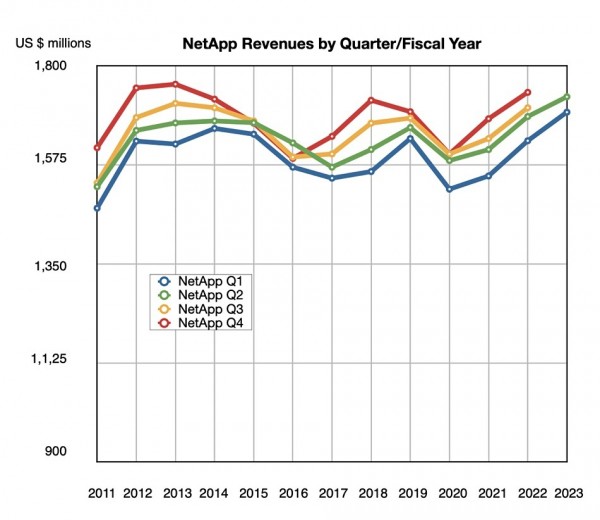
截至10月28日,NetApp当季度收入为16.6亿美元,同比增长6%。季度利润为7.5亿美元,远高于上年同期的2.24亿美元。但这部分源自总额4.45亿美元的所得税返还。
公司CEO George Kurian表示,“我们在活跃的市场环境下实现了稳定的季度表现,第二季度收入、账面、毛利、营业收入和每股收益均创下历史新高……在充满挑战的宏观环境中,我们仍然专注于创新、行动和运营纪律。”
他也在发言中提出警告,“我们对云服务增长放缓感到失望。但我们仍抱有坚定不移的信念——把握云业务这一宝贵发展机遇,并贯彻执行下去。”
有迹象表明,客户的支出正在减少。为此,NetApp实施了广泛的招聘冻结、运营费用削减、自由支配部分支出的收缩、优化办公场地规模等等。公司还决定从低收益活动中抽离出资源,并投入到前景更光明的商业机会中去。
公司CFO Mike Berry表示,“我们将在2023财年的剩余时间内,继续暂停云运营方面的收购。”
正好借这段时间,NetApp公司打算好好整理之前买下的云运营资产。Berry表示,NetApp将“完善Cloud Insight的价值主张和销售方式,加快将Spot和CloudCheckr整合至单一finops套件当中,并通过整合加强我们的InstaClustr产品组合。”
他还补充道,Cloud Insights的交叉销售也将从2024年起被提上议程。
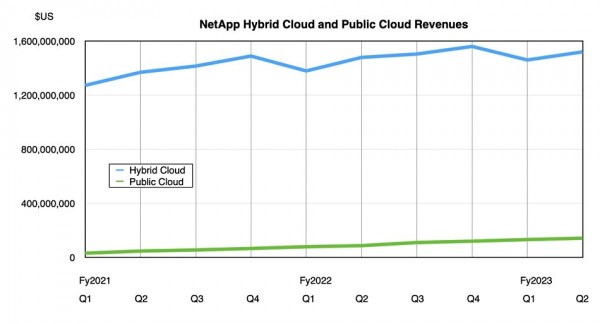
NetApp本季度的混合云业务收入为15.2亿美元,上年同期为14.8亿美元。公有云收入为1.42亿美元,上年同期为8700万美元。公有云年度经常性收入为6.03亿美元,虽然同比增长55%,但仍未达到NetApp的预期。
Kurian指出,“随着客户着力优化云支出,目前业务增长已经放缓、我们云存储服务的销售增速也开始下降。”他还特别提到“这主要是指那些项目工程量极大的客户,比如芯片设计。在这部分群体中,云支出优化已经成为普遍趋势。”
但另一方面,NetApp的云成本优化工具Spot则表现出色。“与第一季度相比,Spot在第二季度内的客户增速有所加快。”在Kurian看来,“我们的公有云服务体现出高度差异化,也为NetApp创造了新的客户粘性。在这个关键市场中,我们相较于几家传统竞争对手拥有多年优势,能够更好地保持稳定增长。”
具体来讲,“我们是VMware Cloud唯一认证且支持的第三方云存储解决方案,这为我们创造了重要的新机遇。随着更多VMware环境被迁移至云端,我们将承接更多原本存留在竞争对手本地系统上的数据。”
全闪存阵列收入增长2%,年化收入为31亿美元,与上年基本持平。在已售存储设备中,全闪存产品的渗透率目前为33%。
财务摘要
- 毛利率:66.3%(上年为68.3%)。
- 现金、现金等价物和投资:截至本季度末为30.3亿美元。
- 运营现金流:2.14亿美元,上年同期为2.98亿美元。
- 自由现金流:1.37亿美元。
- 股票回购与股息:共回购价值1.5亿美元的股票,并支付1.08亿美元的现金股息,共向股东返还2.58亿美元。
- 每股收益:3.41美元,去年同期为0.98美元。
从前景来看,客户支出放缓已成定局。Kurian表示,“我们坚信光明就在前头,但随着近期宏观经济态势萎靡,我们也略微下调了本财年剩余期间的收入预期……随着本季度推进,我们发现预算审查有所增加、需要更高级别的批准后方可通过,因此交易规模变小、销售周期变长,部分交易甚至延后至下个季度。在第二季度,我们在美洲的高科技和服务提供商身上有了最为强烈的开支收缩感受。”
另外,前所未有的汇率冲击也已到来。
因此,NetApp预计下季度的收入在15.25亿美元至16.75亿美元之间,中间值为16亿美元,较上年同期的16.1亿美元减少1000万。
Kurian解释称,“目前的宏观经济低迷和前所未有的汇率冲击,正持续影响IT支出总量,导致我们调低了对下半年的收入预期。”从结论来看,NetApp预计2023年的全年收入将达到65亿美元,与2022年相比增长2%至4%。
从结果看,NetApp可以算是存储厂商中受影响最小的一家。面对经济衰退,希捷、美光、SK海力士等从NAND到磁盘驱动器厂商显然情况更为糟糕。
好文章,需要你的鼓励


亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
亚马逊旗下运营近20年的众包平台Mechanical Turk已停止接受新用户注册,并将于2026年7月30日正式关闭。该平台于2005年上线,早于AWS公有云业务,曾是全球知名的众包任务市场,涵盖验证码识别、情感标注等人工任务,后转型为AI训练数据标注工具。随着亚马逊推出SageMaker Ground Truth等替代方案,Mechanical Turk的历史使命已宣告终结。

当AI助手“看“电脑屏幕,就像让一个视力正常的人蒙眼操作——德克萨斯大学达拉斯分校的解法
LUMOS是一个让AI通过操作系统无障碍接口直接读取界面语义信息来操控电脑的中间层,避免依赖截图识别,降低AI电脑操作的资源消耗和出错率。

微软推出Memora,致力于解决AI智能体的记忆难题
微软研究院发布Memora记忆系统,旨在解决AI智能体在长期部署中记忆碎片化、检索效率低的问题。Memora通过将存储内容与检索方式解耦,引入"主抽象"与"线索锚点"双组件架构,在LoCoMo和LongMemEval两项基准测试中表现优异,上下文token用量最高可降低98%。但专家提醒,实际企业成本还需考虑索引、存储及合规审计,且该项目目前仍处于研究阶段,尚未达到生产就绪水平。

腾讯混元携手多所高校,让3D网格生成快如闪电——PolyFlow如何破解困扰业界多年的“拓扑难题“
腾讯混元联合多所高校提出PolyFlow,用流匹配模型并行生成艺术家风格3D网格,速度比自回归方法快百倍,几何精度达到新高。
2022
12/07
15:00
分享
点赞

Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
Day-0支持|摩尔线程完成美团LongCat-2.0极速适配
亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
微软推出Memora,致力于解决AI智能体的记忆难题
SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
特斯拉在迈阿密划定Robotaxi小范围服务区,得克萨斯扩张仍受阻
Luxonis完成1400万美元融资,为智能自动化打造视觉感知层
.NET 8 与 .NET 9 即将停止支持,微软建议升级至 .NET 10
苹果供应商塔塔电子遭黑客攻击,iPhone 18 Pro核心机密外泄
美国解除对Anthropic旗下Fable 5和Mythos 5大语言模型的出口限制
Meta推出定制CXL芯片Vistara,让旧内存在新服务器中焕发新生
