
数据保护延伸到SaaS领域,Veeam推出Backup for Salesforce
Veeam公司现已推出面向Salesforce用户的数据与元数据保护方案,借此将保护范围从本地和公有云进一步扩大至SaaS应用领域。
这是对Veeam功能的重要补充。与其他数据保护服务商一样,Veeam的早期业务也是备份本地裸机和虚拟化服务器,之后将这部分功能扩展至公有云端,填补AWS、Azure和GCP功能缺失给用户带来的数据隐患。但随着Salesforce和ServiceNow等SaaS应用程序的广泛流行,新的数据保护前沿也由此诞生。之前已经有OwnBackup等专业供应商提供这类数据保护选项,如今Veeam也正式投身于这部分市场。

Rick Vanover
Veeam公司产品战略高级总监Rick Vanover写道,“大部分使用Salesforce的组织都在批量导入数据,而这一导入过程正是造成数据损坏和删除的首要原因。”
Veeam在今年5月发布了其Falesforce备份产品的预览版。
Vanover介绍称,“Veeam可提供对Salesforce数据和元数据的完整访问与控制,并为IT部门及Salesforce管理员提供强大且快速的恢复功能,可恢复对象包括Salesforce记录、层次结构、字段和文件。”
“绝大多数IT专业人士都承认,组织内总会不可避免地发生Salesforce数据丢失,而且他们很少会主动备份。”
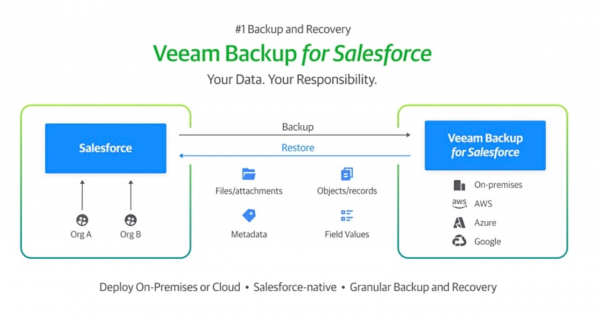
Veeam Backup for Salesforce功能概述:
- 专为Salesforce API的设计和使用所构建
- 可恢复Salesforce记录、层次结构、字段、文件及元数据
- 可部署在本地或云端(AWS、微软Azure等)
- 在对象级别设置分粒度的备份计划与留存设置
- 通过单一控制台管理多个Salesforce实例
- 提供增量同步与灵活调度选项,允许客户几乎无缝对Salesforce数据和元数据进行连续备份
- 通过Veeam GUI,在几分钟内运行备份策略和恢复作业
- 查看记录和元数据的版本,并将其与生产版本进行比较
- 将链接对象精细还原至任意记录,包括父/子记录
作为同类方案供应商,OwnBackup公司自2012年成立以来就一直保持着高速增长。2020年7月,该公司有2000名员工,但到2022年7月,这个数字就上涨到了4700人。
该公司为Salesforce SaaS和PaaS数据提供安全、日常自动备份、恢复、灾难还原及管理工具。经历先后七轮融资,OwnBackup已经累计筹得5.07亿美元,并将保护范围拓展到了微软Dynamics 365和ServiceNow用户当中。
近期针对Salesforce数据出现了一波“保护热潮”,Salesforce用户迅速在大量相似的新产品中挑花了双眼:
- Veritas在Netbackup中推出了Salesforce用户数据保护方案,这也呼应了该公司产品组合战略高级总监Santhosh Rao在5月做出的“Salesforce保护功能即将亮相”承诺。
- Commvault推出的Metallic备份即服务也适用于Salesforce。
- IBM的Spectrum Protect Plus Online Services for Salesforce为Salesforce客户提供自动每日备份、按需备份与恢复功能组合。
- 其他发布有Salesforce数据保护方案的厂商还包括AvePoint、CloudAlly、Cohesity、Druva、Odaseva、Kaseya’s Spanning以及Skyvia。
Veeam公司目前拥有超40万客户,此次推出的新功能也将完整覆盖这个群体。毕竟如果坐视需求不理,就相当于放任竞争对手乘虚而入、抢夺自己的客群。我们预计,Veeam及其他主要备份供应商将不断增加SaaS产品的覆盖率,并在市场上OwnBackup展开一番你死我活的竞争。
Veeam Salesforce备份的一到五年期订阅价格为每用户每年36美元,但同时也提供以下两种折扣套餐:
- 每年最多300名用户——2000美元
- 每年无限多用户)——10000美元
Veeam公司也提供Salesforce备份服务的免费版本,即Veeam Backup for Salesforce社区版。此版本只适用于Salesforce用户许可数在50个或以下的组织,但数据备份和恢复功能一应俱全。
感兴趣的朋友可以点击此处查看Veeam Backup for Salesforce产品概述(https://www.veeam.com/veeam_backup_salesforce_product_overview_ds.pdf),通过这里参阅用户指南(https://www.veeam.com/veeam_backup_salesforce_1_0_user_guide_pg.pdf)。
好文章,需要你的鼓励


雷克萨斯LFA电动超跑2027年量产,将搭载固态电池
丰田旗下豪华品牌雷克萨斯正以纯电动版本复活经典跑车LFA。新车已在古德伍德速度节亮相,预计2027年量产,将采用丰田期待已久的固态电池技术。该技术承诺更高能量密度与更快充电速度,但丰田已多次推迟相关计划。新款LFA搭载电动动力系统,内饰配备Yoke方向盘与沉浸式数字座舱,车身尺寸与阿斯顿马丁DB12相近。面对比亚迪腾势Z等1500马力级竞品,雷克萨斯能否追上电动超跑赛道,值得关注。

慧眼难辨“何时何处“——慕课里AI通才的专业盲区,庆应义塾大学新出的这套考卷让15个顶级模型集体翻车
庆应义塾大学与英伟达推出AnyGroundBench,测试15个顶级视觉语言模型在手术、工业等五大专业领域的时空定位能力,揭示当前AI在专业场景下的系统性空间定位瓶颈。

科学家研究证明:我们并非生活在模拟现实中
加拿大不列颠哥伦比亚大学奥卡纳根分校的研究人员通过数学方法,对"模拟现实"理论给出了否定答案。研究人员米尔·法扎尔在《物理全息应用期刊》上指出,基于不完备性与不可判定性数学定理,现实无法仅通过计算来完整描述,它需要非算法性的理解,而这超出了算法计算的范畴,因此无法被模拟。尽管如此,"模拟宇宙"的观念短期内仍难以从公众讨论中消失。

清华大学与蚂蚁集团联合打造“数据科学AI考官“:AgenticDataBench如何给数据智能体打出一张精准成绩单?
清华大学与蚂蚁集团联合推出AgenticDataBench,含344道真实数据科学任务和433个精细技能标签,系统评测12种主流数据智能体配置的能力边界与短板。
2022
11/01
16:44
分享
点赞

科学家研究证明:我们并非生活在模拟现实中
苹果与博通签署高达300亿美元芯片采购协议
零信任网络访问如何从根本上消除隐性信任
Crusoe扩展AI平台:推出无服务器微调与自助推理部署
Oratomic完成3亿美元融资,仅需2万个量子比特造出实用量子计算机
Anthropic将Claude Cowork智能体扩展至网页端与移动端
OpenAI发布延迟模型,美国AI监管混乱引发企业隐忧
微软押注企业AI需要工程师而非庞大销售团队
Anthropic揭开Claude AI黑箱:J-space技术带来模型内部可见性突破
英格兰银行获授权监管亚马逊、谷歌等科技巨头
酷睿Ultra战力Plus,英特尔携九大合作伙伴亮相Bilibili World 2026
iOS 26.5.2正式发布,包含逾20项安全修复,Claude协助发现漏洞
《网络数据安全管理条例》正式施行,企业数据保护合规如何落地?
AI 时代的隐形身份威胁与安全隐患
中东地区的网络安全记录背后的企业掩盖行为
智慧医疗网络安全发展与创新论坛在南昌成功举办
Veeam CEO谈20亿美元融资、Cohesity-Veritas合并、Rubrik IPO和数据弹性
Veeam公司CEO谈近期20亿美元融资、Cohesity-Veritas并购、Rubrik上市以及数据弹性
万字指南 | 当SaaS出海“回到”美国,那些共识与非共识背后的观察与思考
西门子提供Capital X软件即服务
IBM现身SaaStr 2024大会的五大AI要点
Veeam与Palo Alto Networks 集成应对攻击
