
深信服EDS:敬畏数据,充分实践,与用户共创数据宏图
4月14日,由百易传媒(DOIT)与厦门大学信息学院联合主办,中国计算机学会信息存储专委会、中国计算机行业协会信息存储与安全专委会、武汉光电国家研究中心协办的“2022分布式存储线上峰会”召开,深信服存储产品线副总经理田皓野在峰会中进行了题为《深信服分布式存储EDS与用户共创数据宏图》的主题分享。
企业数字化转型,数据量“爆发式增长”,存储面临着“存不下”、“成本高”、“替换难”的挑战,以及层出不穷的安全威胁,同时迎来高扩展性、多元化、高性能等新需求,传统数据存储已无法适应发展。
始于当下的需求与挑战,深信服带来EDS分布式存储解决方案,以分布式存储支撑创新业务发展及海量数据的存储与备份,最终面向未来,通过EDS构建混合云/多云数据统一管理平台,管理和承载数据。
>>一个理念:一个数据底座,无限数据潜力
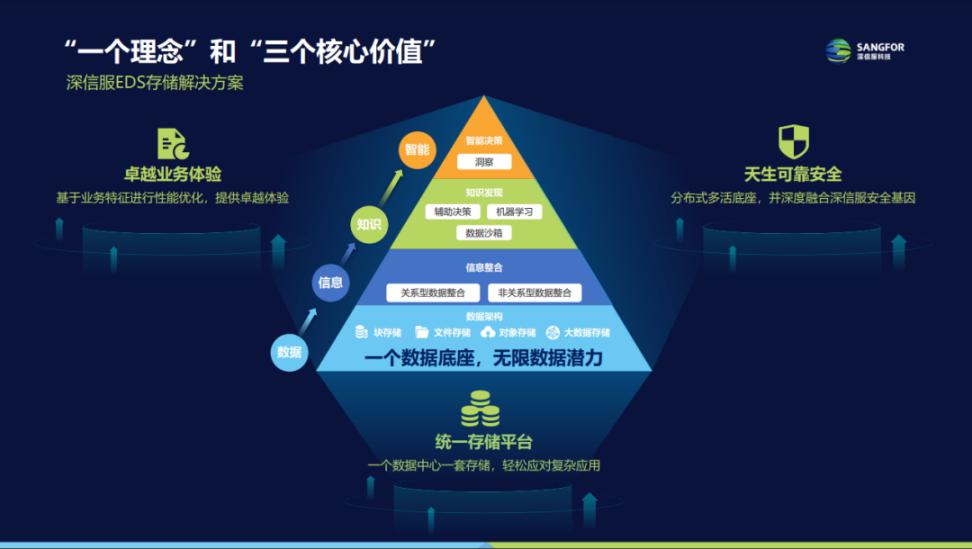
深信服EDS为用户打造统一的数据底座,实现“一个数据中心一套存储”承载海量数据,并在此基础上提供高性能业务体验以支撑各类业务,同时为数据提供全方位安全防护,应对高级安全威胁。存储数据的同时,发挥数据的价值,将数据转化为促进企业高速发展的核心生产材料。
>>三个核心价值,构建面向未来的数据中心存储方案
(1)统一存储平台
统一架构:为企业各类业务提供存储支持、云存储服务与技术支撑。
统一资源:底层硬件解耦,上层应用兼容,深信服EDS是业内唯一一个集群同时支持块、文件、对象、大数据多种存储类型和十几种存储协议接口,可广泛兼容业务应用;同时,EDS存储软件采用互联网式敏捷开发模式,快速迭代,可快速支持新场景、新应用;支持硬件供应解绑,降低替换成本,帮助新硬件快速适配。
统一管理:一套管理平台,多种存储资源统一运维,全方位监控及运维多种类型存储资源使用情况,运维更简单。
(2)卓越业务体验
深信服EDS从不“唯数据论”,不盲目追求性能数据上的提升,而是落到真实的业务场景,针对业务特征进行性能优化,为实际业务运行带去更好的体验。
针对高IO数据生产业务,提供块存储服务,3节点EDS集群即可获得347000+ IOPS、2,500+ MBPS。这是什么概念呢?田皓野举了几个简单的例子:可支持2000+个云桌面稳定运行、300+个应用虚拟机稳定运行、支持5+个并发用户数400+的数据库稳定运行。
针对高吞吐数据生产业务,提供文件存储服务,3节点EDS集群,单客户端可达 1.9GB/s,多客户端可达 6GB/s。在真实场景中如何体现,田皓野也给了生动的案例展示:在广电高清视频制作中,3节点可支持16台4K超高清工作站或120台高清工作站并发运行;使用EDS承载医院PACS数据,开启智能预加载机制的情况下,医生阅片时单张读取时长不超过10ms。
针对海量小文件并发业务,提供对象存储服务,3节点EDS集群可承载100亿+个小对象数据,且性能下降不超过5%。
(3)天生可靠安全
深信服EDS通过构建事前、事中、事后体系化数据保护框架,保障业务数据0丢失;通过分布式多活架构,保障业务0中断,重新定义“可靠”。
同时,基于深信服20多年来安全技术的积累,深信服EDS深度融合深信服强大的安全基因,内建体系化数据安全方案,提供企业级多层次的安全防护,轻松应对高级威胁,切实保障数据的安全性。
深信服EDS从一开始作为VDI(市占率第一,数据来源于IDC)、超融合HCI(市占率前三,数据来源于IDC)的存储底座,积累丰富实践经验,到如今累计参与交付超过20000个客户,覆盖商企、政府、医疗、广电、金融、教育等行业;PB级项目交付超过100例,独立为2000个客户提供统一存储解决方案;存储发明专利100+,获得USENIX顶级学术论文。发展的路上,我们持续投入研发与优化,为用户提供更优的数据存储解决方案。
对数据保持敬畏之心,充分实践,与用户共创数据宏图,是深信服EDS不懈的追求。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。


清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2022
04/19
14:23
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
