
IDC:2018上半年浪潮在企业级存储市场出货量和增速中国第一
日前,IDC正式公布2018年上半年《中国企业级存储系统市场调查数据报告》。数据显示,2018年上半年中国市场存储出货量为67,358套。浪潮存储出货量8,414套,居中国企业级存储(不含监控)市场第一;浪潮出货量增速106%,5倍于业界平均增速,居中国第一。
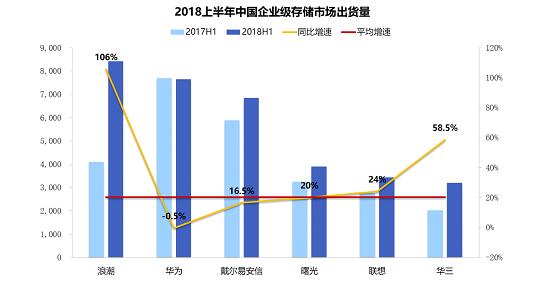 【IDC 2018上半年中国企业级存储市场出货情况】
【IDC 2018上半年中国企业级存储市场出货情况】
整体来看,2018年上半年,中国企业级存储市场出货量达到67,358套,总容量为7430.5 PB。政府增加了IT投资,金融、教育和卫生也显示出良好的增长势头,并将在2018年继续保持增长趋势。
存储需求变化 构建新数据时代
IDC认为,支持数据经济发展的新技术不断涌现,掌握并应用最新技术就是打开数字经济未来的关键。
这个由云计算、大数据、人工智能、区块链、物联网等新技术驱动,移动互联、人脸识别、自动驾驶等新智能应用不断涌现的时代,浪潮将其定义为智慧驱动的新数据时代。相比过去以数据库、文件、流媒体为主的存储应用,新数据时代,存储要面对云、大数据、人工智能等新技术产生的数据需求。
新数据时代,数据有三大需求变化。一是PB成为通常的测量单位,一些行业甚至开始出现EB、ZB级存储需求。IDC数据显示,2018年上半年出货67,358套,单套存储达到PB级出货容量的有数百例;存储集群容量达到EB级。浪潮目前已出货的存储集群裸容量72PB,在业界领先。二是存储性能要求更高,某些核心应用已经要求百万级的IOPS、TB级带宽;前不久进行的浪潮软件定义存储AS13000模拟真实业务环境的测试震撼了业界,整个集群288节点,其中元数据集群128节点,系统实测性能达到380万IOPS、324GB/s聚合带宽。三是对数据的智能管理和流动提出高要求,需要对几百个乃至更多的数据存储节点提供一体化管理运维并保障数据流动。
软件定义存储市场 是未来产业方向
现在数据中心在快速演进,大部分的数据中心都会遵循某个模式来发展。像一些互联网的数据中心,或者一些高性能计算的数据中心,会做得比较激进。这些数据中心主要是新建的,没有一些固有的历史包袱,可以面向未来去更多的采用一些新架构和新技术。IDC认为,软件定义的基础设施将深刻影响未来产业的发展。
基于Scale-out架构的浪潮软件定义存储系列,可融合多类型数据,在“All in One”架构下可支持文件、块、对象和大数据四种数据服务。浪潮成功部署实施了大量PB级大工程,在中国移动分布式存储集采中获得30%份额,预计容量会超过50PB;在某卫星项目实现中国最大规模的软件定义存储部署,达到单系统239个节点、72PB容量;在广电总局,AS13000持续部署超过10PB容量。
SAN存储 稳健增长
IDC预计,未来5年,存储市场将继续显示稳健增长(CAGR增长为9.8%),总容量可能达到约90 EB。政府、金融、电信仍是主要投资者,教育和医疗也将显示出巨大潜力。
对于关键业务来说,用户广泛采用基于FC协议的SAN存储,SAN存储已经在帮助用户解决关键业务的数据管理方面发挥了巨大作用。IDC数据显示,2018年上半年FC存储出货量24,467套。同时,企业级存储市场,混闪存储在2018年上半年的市场份额为33.5%,仍占主导。
在基于FC协议的SAN存储领域,浪潮存储2018上半年出货量2,293套,主要包括智能存储G2系列和智能全闪G2-F系列,承载关键业务数据。目前,浪潮存储已在广东省高级人民检察院项目、25PB华中科大脑科学研究项目、重庆国土项目、邮储银行项目部署,金额都达到千万级,实现金融、能源、政府、教育等行业的规模推广。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。


清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2018
09/28
11:27
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
